


 雷达卡
雷达卡



由英伟达与香港大学联合开源的最新研究成果——ToolOrchestra模型,凭借仅80亿参数的规模,在人类终极考试(HLE)等高难度挑战中表现卓越,甚至超越了GPT-5等大型闭源模型。


该研究提出了一种全新的智能编排架构,通过训练一个轻量级的“指挥官”模型,实现对包括GPT-5在内的多种先进大模型和专业工具的高效调度。这一成果表明,通往超级智能的道路并非只能依赖参数堆叠,学会协调与指挥,往往比单一模型的独立作战更为强大。
异构智能体网络中的指挥艺术
长期以来,业界普遍存在一种思维定式:唯有具备海量参数的单一模型才能应对最复杂的推理任务。这类“单体巨兽”(Monolithic Model)虽具备较强的通用能力,但在面对需要深度计算、领域专精或复杂逻辑的问题时,常常效率低下且成本高昂。
传统意义上的工具使用方式,通常局限于为大模型配备搜索引擎或计算器,未能充分释放外部工具的潜力,也忽略了人类解决问题的核心策略——在关键时刻寻求更强大的协助者。
ToolOrchestra提出的“编排范式”(Orchestration Paradigm),正是基于这一洞察而构建。该系统的智能并非源自某个庞大的中央处理器,而是从一个由多个组件构成的复合系统中涌现而出。
其核心是一个经过专门训练的8B小型模型,称为“指挥官”(Orchestrator)。它的职责不是亲力亲为解决所有问题,而是如同一位经验丰富的项目经理,动态判断每一步所需的资源:是查询本地数据库?运行Python脚本?还是调用如GPT-5或专用数学模型这样的“外援”?
这种分工机制使得小模型能够驾驭远超自身能力的智慧体系,将高难度子任务委派给更擅长的模型,从而突破整体系统的智能上限。

扩展工具边界,构建异构协作网络
Orchestrator的关键创新在于极大拓展了“工具”的定义范畴。在其工具箱中,除了常规的Web搜索(Tavily API)、代码解释器(Python Sandbox)、本地检索(Faiss索引)之外,其他大语言模型(LLM)本身也被视为可调用的工具资源。
整个系统整合了三类不同层级的工具:
- 基础工具:提供通用功能支持,如网页搜索、代码执行、文档检索。
- 专用型LLM:针对特定任务优化的专家模型,例如Qwen2.5-Math专注于数学推理,Codestral擅长代码生成。
- 通用型LLM:行业顶尖的全能选手,如GPT-5、Claude Opus 4.1、Llama-3.3-70B,用于处理高度复杂的综合任务。
Orchestrator通过统一接口与这些异构工具交互,实现灵活调度。为了使其准确理解各模型的能力边界,研究团队设计了一套自动化能力描述生成流程:先让目标模型试运行一系列任务,再由另一个LLM分析其行为轨迹并生成能力摘要,从而帮助指挥官做到“知人善任”。
整个求解过程形成一个多轮推理闭环:面对复杂查询,Orchestrator在“推理”与“工具调用”之间反复迭代。它评估当前状态,规划下一步行动,选择合适的工具并设定参数;环境执行后返回结果作为新的观测值(Observation),直至最终答案生成。
多维奖励机制重塑决策逻辑
仅仅提供工具,并不能保证小模型自动掌握指挥技巧。简单的提示工程(Prompting)方法效果有限,且易引入偏见。研究发现,当GPT-5被要求担任指挥角色时,会表现出明显的自我增强倾向(Self-Enhancement Bias),倾向于频繁调用自家轻量版模型,或不计代价地启用最强模型,导致资源浪费。
而Qwen3-8B在类似设置下,则对GPT-5产生严重依赖,高达73%的请求都指向该模型,几乎丧失自主判断能力。
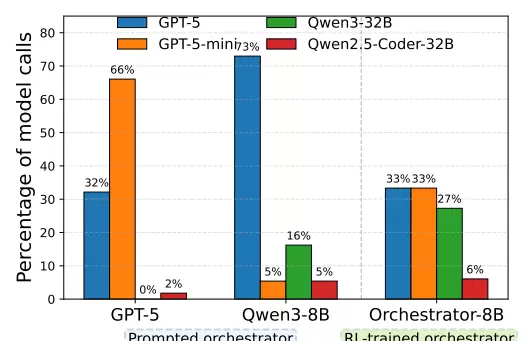
为解决上述问题,ToolOrchestra引入了基于GRPO(Group Relative Policy Optimization,组相对策略优化)的强化学习框架,并设计了三维奖励函数体系,全面重塑Orchestrator的行为模式:
- 结果奖励(Outcome Reward):以任务最终正确性为核心指标,利用GPT-5作为裁判判定答案准确性,确保基本性能达标。
- 效率奖励(Efficiency Reward):依据第三方API定价机制,将Token消耗与响应延迟折算为经济成本进行惩罚,促使模型优先选择性价比更高的方案。
- 偏好奖励(Preference Reward):响应用户的非功能性需求,例如“尽可能节省开支”或“仅使用本地工具保障隐私”,使指挥官能在成功率与用户约束之间做出权衡。
这套多维度激励机制让Orchestrator学会了理性决策:不再盲目迷信某一款模型,而是根据任务类型、难度和成本效益进行动态调配,真正实现了“花小钱办大事”。
合成数据流水线突破训练瓶颈
训练如此智能的指挥模型面临的一大挑战是真实标注数据极度稀缺。为此,研究团队构建了一条高效的合成数据生成流水线,通过模拟大量任务场景自动生成高质量的训练样本,有效缓解了数据瓶颈问题,为Orchestrator的学习提供了坚实基础。
当前可用的数据集普遍缺乏对多工具、多模型协同场景下复杂交互轨迹的支持。为解决这一问题,研究团队开发了名为ToolScale的自动化数据合成框架。该系统能够生成覆盖10个不同领域、包含数千个可验证的多轮工具调用实例,有效填补了高质量训练数据的空白。
ToolScale的工作流程始于环境模拟阶段。系统首先选定一个具体应用领域(如电影预订),利用大语言模型(LLM)自动生成贴近现实的数据库结构与API接口定义,从而构建出一个虚拟的交互环境。
接下来进入意图演化环节。在已建立的环境中,LLM被用于生成多样化的用户需求,并将这些抽象意图转化为具体的任务指令以及对应的标准操作序列(即“金标准”)。为了提升任务难度,避免生成过于简单的样本,系统引入额外的LLM模块来添加约束条件,增强任务的复杂性与挑战性。
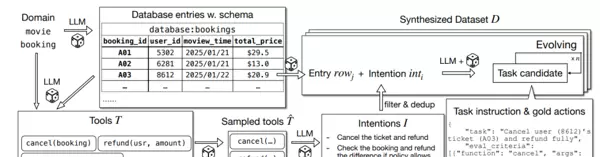
最后是严格的质量过滤过程。通过执行验证机制,系统会剔除那些存在运行错误、无法完成或复杂度不足的样本,确保最终保留的数据具备高训练价值和实际可用性。这一整套流程成功实现了从零开始构建高质量多工具交互数据的能力,为后续的强化学习训练提供了坚实基础。
在多个高难度基准测试中,基于该框架训练出的Orchestrator-8B展现出卓越性能,验证了小模型通过智能编排策略实现超越大型模型的可能性。
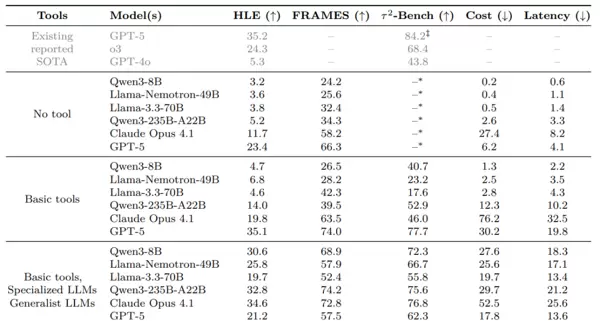
HLE(Humanity's Last Exam,人类终极考试)是一项汇集各学科复杂难题的综合性评测,极具挑战性。Orchestrator-8B在此测试中取得了37.1%的成绩,显著优于GPT-5的35.1%。更重要的是,在获得更高得分的同时,其计算资源消耗仅为GPT-5的几分之一,整体效率提升了2.5倍。
作为对比,未配备外部工具的Qwen3-8B仅得4.7%,表明单一的小模型难以应对此类复杂任务;即便是配备了工具能力的Claude Opus 4.1,得分也仅为19.8%。
在事实推理基准FRAMES上,Orchestrator-8B达到76.3%的准确率,超过GPT-5的74.0%。而在函数调用专项测试Tau2-Bench中,它以80.2%的表现刷新纪录,且总成本仅为GPT-5的30%。分析显示,该模型学会了在60%的步骤中使用低成本工具,仅在关键的40%决策点才调用高成本模型如GPT-5,实现了资源的最优配置。
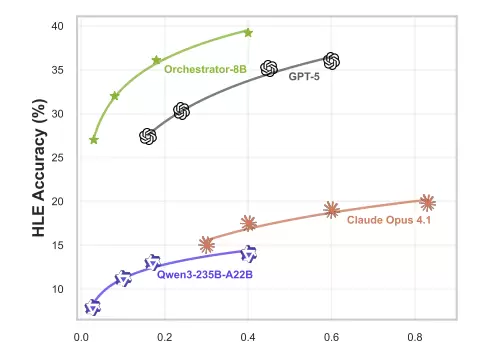
成本效益分析进一步表明,Orchestrator-8B在性价比方面表现最优。随着预算(允许的操作轮数)增加,其性能持续稳定上升,并在所有成本水平下均优于GPT-5和Claude Opus 4.1等超大规模模型。这意味着它能在更低的资金投入下,持续提供更精确的结果。
Orchestrator-8B的成功揭示了人工智能发展中的几项深层趋势。
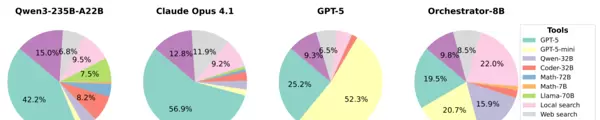
首先是偏见的克服。统计数据显示,Orchestrator-8B在工具选择上表现出高度均衡:GPT-5调用占比为25.2%,数学专用模型占9.8%,本地搜索工具使用率为22%。相比之下,Claude Opus 4.1对GPT-5的依赖高达56.9%,而GPT-5自身则过度倾向使用GPT-5-mini(达52.3%)。Orchestrator摒弃了品牌偏好,真正做到按需选型——只选合适的,不选昂贵的。
其次是强大的泛化能力。即使面对训练过程中未曾接触过的新型工具或模型(例如Claude Sonnet或DeepSeek-Math),Orchestrator也能通过阅读其功能描述快速理解并有效利用,实现即插即用的最佳性能表现。
最后是良好的用户对齐特性。当用户明确提出“我想省钱”等偏好时,Orchestrator能够真正理解和响应这类诉求。在多项偏好测试中,其对用户设定约束的遵循程度远超GPT-5,显示出更强的实际部署可控性和实用性。
ToolOrchestra打破了“模型越大越好”的传统认知,证明了一个经过精心设计、擅长调度外部资源的80亿参数模型,完全可以在复杂任务中胜过当前最先进的万亿参数级模型。这种以小博大的编排范式,为未来高效、灵活、低成本的AI系统建设提供了全新思路。

 京公网安备 11010802022788号
京公网安备 11010802022788号







