


 雷达卡
雷达卡






一、引言
过去两年,人工智能语言模型领域掀起了一场序列长度竞赛。我们的技术从4k上下文长度逐步演进至32k、128k,最终迎来了Gemini 1.5 Pro等模型首次承诺的百万token超大上下文窗口。这一愿景极具吸引力:将整个代码库或小说输入模型,使其能基于全部内容进行推理。
但这种近乎“无限”的上下文长度背后,隐藏着一个极少被提及的代价——内存消耗。
在标准Transformer架构中,记忆并推理整个提示词(prompt)并非无成本。随着输入序列长度增加,模型必须存储每个token的键(Key)和值(Value)状态(即KV状态)以计算注意力分数。对于百万token级别的序列,KV缓存(KV Cache)的体积会迅速激增至数百GB,这就需要跨多个数据中心的大规模GPU集群提供支持,仅为将对话内容留存于内存之中。
二、研究动机
在标准注意力机制(Vaswani等人,2017)⁶中,模型生成的每个新token都需要“回溯”提示词中的所有历史token,以充分理解上下文。为提升多轮生成的效率,模型会将历史token的键向量(K)和值向量(V)缓存至GPU显存中,这一机制即为KV缓存。
线性增长陷阱
尽管缓存键值向量(KV缓存)能提升时间效率(无需为每个新token重新计算历史信息),但它的内存占用量极大,且会随输入序列长度呈线性增长。
具体来说:对于一个标准的5000亿参数模型,仅存储2万个token上下文的KV缓存就需要约126GB内存。若将参数规模提升至现代大语言模型的万亿级以上,同时为数百万用户提供实时服务,其总内存占用量将达到天文数字。
历史上,我们处理序列数据主要有两种方式,但均存在缺陷:
循环神经网络(RNN):逐token处理输入提示词,通过更新单一固定的隐藏状态传递信息。这种方式虽能大幅降低内存需求,但难以在长提示词中保留信息细节,导致模型处理到序列末尾时,往往会遗忘开头内容。
Transformer模型:与RNN不同,Transformer通过将整个对话历史存入KV缓存,实现完美记忆。它具备无差别的回忆能力,但受限于庞大的KV缓存,内存消耗极高。
而无限注意力(Infini-attention)正是为解决这一权衡困境而提出的方案。
三、解决方案:无限注意力(Infini-attention)
为破解内存悖论,谷歌研究人员提出了无限注意力机制(Munkhdalai等人,2024)¹。其核心原理是:无需存储完整对话内容,仅保留对话的压缩摘要即可。
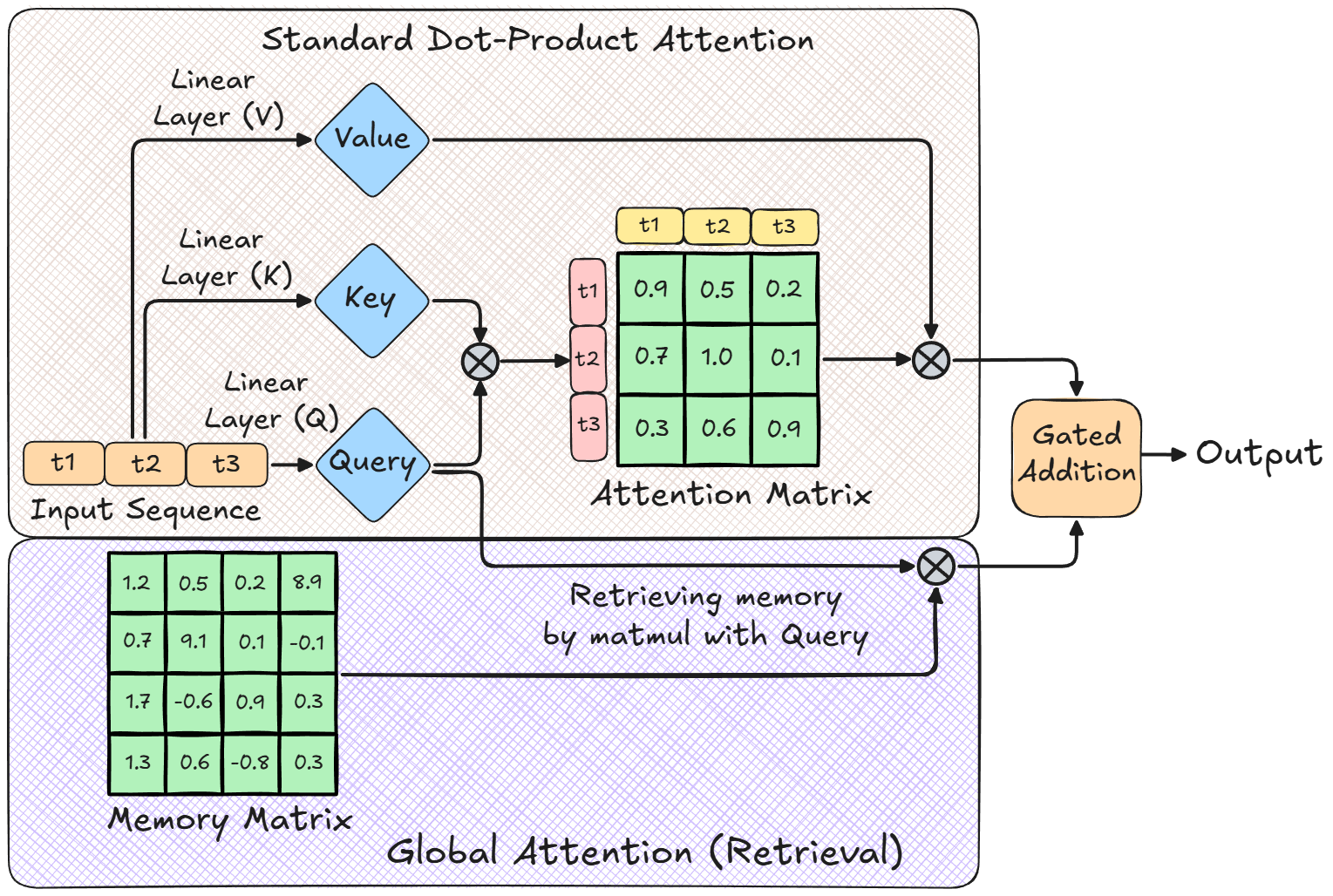
无限注意力将注意力输出拆分为两个并行工作的独立机制:
局部注意力机制:与标准Transformer一致,聚焦即时上下文,为每个token计算注意力矩阵,以高分辨率捕捉细节信息。
全局线性注意力机制:一种压缩内存,将全部历史信息的摘要存储于固定尺寸矩阵中,供模型查询调用。
以下将详细拆解其处理长输入序列的完整流程。
无限注意力工作原理可视化(检索阶段)
步骤1:分段处理
首先,将整个输入序列分割为若干较小的片段(例如,每个片段含2048个token)。在每个片段内部,模型采用标准点积注意力机制理解上下文,确保即时任务的细节分辨率不受影响。
步骤2:压缩处理(内存更新)
为处理下一个片段,模型会将当前片段的键(K)和值(V)的压缩状态存入固定尺寸的内存矩阵(M)。这样,模型无需调用庞大的KV缓存,仅通过查询内存矩阵即可获取前序片段的信息。
但盲目向内存矩阵中添加新数据,会快速覆盖原有信息。为避免这一问题,研究人员引入了增量规则(Delta Rule,Schlag等人,2021)⁷。其核心逻辑是:添加新信息前,先检查内存中是否已存在该信息,从而避免冗余更新。完整更新流程如下:
A. 探查步骤(计算检索值Vretrieved)
首先,模型以当前片段生成的键向量(K)作为查询条件,从现有内存中检索对应值向量。这一步的目的是判断内存中已存储的信息与当前键向量的关联情况。

B. 更新步骤
随后,模型将当前片段的实际值向量(V)与检索到的值向量(Vretrieved)进行对比,计算两者的差值(残差),仅将残差部分写入内存。这一设计确保内存不会重复存储已有信息。

这意味着,若内存已完美存储当前片段的信息,更新量将为零,从而保证内存在多轮更新中始终保持稳定和“洁净”。
步骤3:全局检索(线性注意力)
生成新token时,模型需要获取整个提示词(即所有片段)的上下文信息。为此,模型通过矩阵乘法查询内存矩阵,提取相关全局信息。

最终得到的Amem矩阵包含了所有前序片段的相关信息,为新token生成提供全局上下文支撑。
步骤4:信息融合(“混合器”)
最终,模型会得到两个输出结果:
Adot:来自当前片段的精细化局部上下文信息
Amem:来自内存矩阵的压缩式全局历史信息
模型通过一个可学习门控标量β(贝塔)将两者融合:

β参数作为混合系数,决定了长期信息(Amem)与短期信息(Adot)的权重分配:
当β值较低时:Sigmoid函数结果趋近于0,互补权重因子(1−sigmoid(β))占据主导,模型优先依赖局部点积注意力(Adot),而非全局压缩内存。
当β值较高时:Sigmoid函数结果趋近于1,模型优先采用内存检索内容(Amem),让全局上下文覆盖当前片段的局部信息。
四、研究结果:无限注意力的核心价值
研究人员将无限注意力与现有长上下文模型(如Transformer-XL(Dai等人,2019)²、记忆Transformer(Wu等人,2022)³)进行对比测试,结果如下:
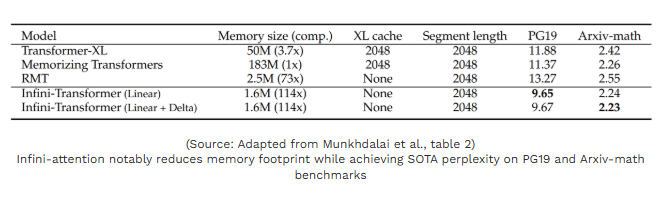
1. 114倍内存压缩比
该研究最具突破性的成果是内存资源的大幅缩减。由于无限注意力将全部历史上下文存储于固定尺寸的内存矩阵,而非线性增长的KV缓存,与记忆Transformer相比,其GPU显存占用量降低了114倍。如下表所示,在处理6.5万个token的上下文时,无限注意力在PG19、Arxiv-math等基准测试中实现了最优困惑度得分,而内存仅需存储160万个参数(即内存矩阵的规模),远低于同类架构。
2. 百万token“密钥检索”测试
“大海捞针”式任务是长上下文架构的常规测试项。研究人员将随机密钥隐藏在海量文本中,要求模型检索该密钥。测试显示,在零样本设置下,模型检索准确率普遍低于20%,表现不佳。
随后,研究人员用仅含5000个token的序列对模型微调400步。令人惊讶的是,模型能够将微调效果泛化至百万token级序列,检索准确率全面大幅提升。
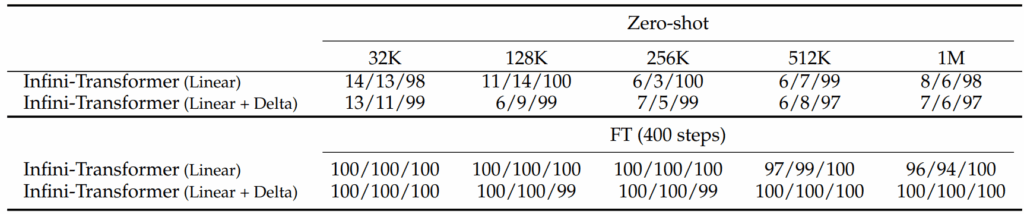
每一项对应的三个分数,分别代表密钥隐藏在文本开头/中间/结尾位置时的检索准确率。
3. 最优书籍摘要能力(50万token上下文)
除合成测试外,研究人员还在BookSum基准测试集(Kryściński等人,2021)⁵中验证模型性能——该任务要求模型为长篇小说生成摘要。结果显示,80亿参数的无限注意力模型创下该基准测试的新纪录,成功为长达50万个token的书籍生成摘要。
测试结果还呈现出明确趋势:输入上下文越长,模型摘要能力越强。下图验证了这一假设——模型不会出现“中间遗忘”(即丢失长序列中间信息的常见缺陷),而是能通过内存矩阵有效利用全局信息,生成精准摘要。
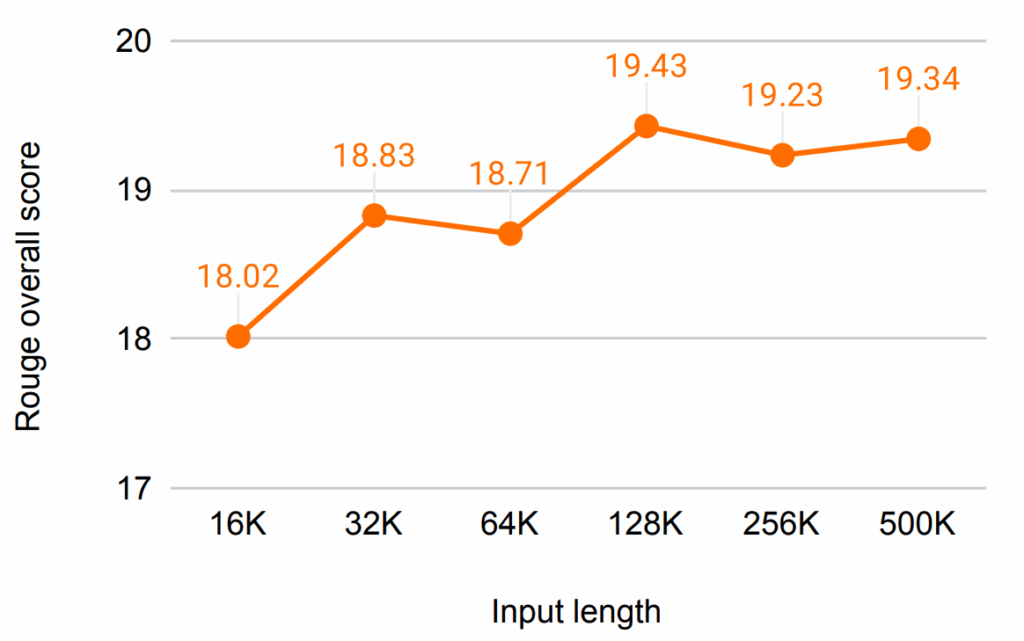
Rouge值与输入长度的关系。Rouge值基于词汇相似度,衡量AI生成摘要与人类撰写摘要的贴近程度。
4. 门控标量可视化分析
作为补充消融实验,研究人员对可学习门控标量β进行可视化,以观察模型对新内存机制的运用方式。下图热力图显示,注意力头分化为两种明确角色:
专用注意力头:β值接近1或0,表明这类注意力头专注于局部上下文(片段内)或全局历史(前序片段)其一。
混合注意力头:β值接近0.5,核心功能是高效融合两种路径的信息。
这一结果表明,模型能够自主学习在短期/长期记忆间切换,并融合整个序列的信息。
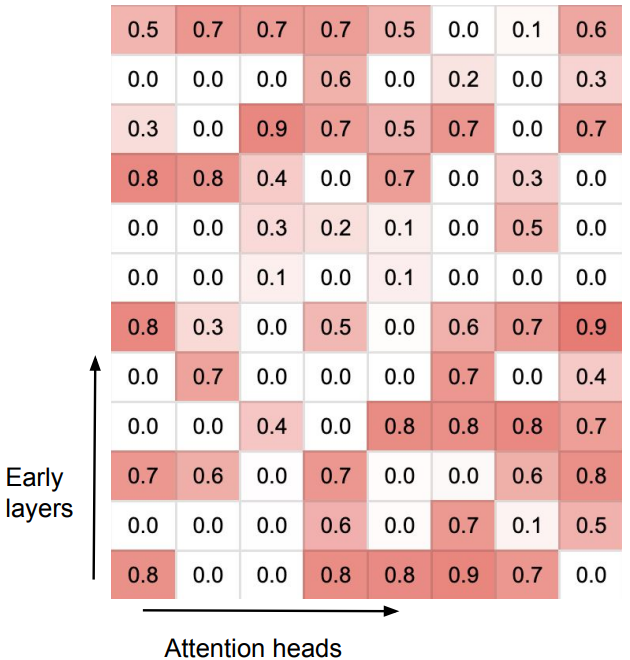
β值可视化结果显示,在无限注意力架构下,注意力头倾向于专门负责全局或局部注意力任务。
五、结论
尽管无限注意力无法完全取代外部向量数据库和检索增强生成(RAG)系统处理静态知识推理,但它彻底改变了模型处理标准用户查询的方式。整合此类架构或将成为推动研究创新的下一步——此前,大语言模型的发展常受限于硬件性能瓶颈,而这一技术突破有望加速语言建模领域的进步。
六、参考文献
无限注意力(核心论文):Munkhdalai, T., Faruqui, M., & Gopal, S. (2024). Leave No Context Behind: Efficient Infinite Context Transformers with Infini-attention. arXiv preprint arXiv:2404.07143.(《不遗漏任何上下文:基于无限注意力的高效无限上下文Transformer》,arXiv预印本)
Transformer-XL:Dai, Z., Yang, Z., Yang, Y., Carbonell, J., Le, Q. V., & Salakhutdinov, R. (2019). Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context. arXiv preprint arXiv:1901.02860.(《Transformer-XL:突破固定长度上下文的注意力语言模型》,arXiv预印本)
记忆Transformer:Wu, Y., Rabe, M. N., Hutchins, D., & Szegedy, C. (2022). Memorizing Transformers. arXiv preprint arXiv:2203.08913.(《记忆Transformer》,arXiv预印本)
线性注意力(数学基础):Katharopoulos, A., Vyas, A., Pappas, N., & Fleuret, F. (2020). Transformers are RNNs: Fast Autoregressive Transformers with Linear Attention. International Conference on Machine Learning.(《Transformer本质是RNN:基于线性注意力的快速自回归Transformer》,国际机器学习大会)
BookSum基准测试集:Kryściński, W., Rajani, N., Agarwal, D., Xiong, C., & Radev, D. (2021). BookSum: A Collection of Datasets for Long-form Narrative Summarization. arXiv preprint arXiv:2105.08209.(《BookSum:长篇叙事摘要数据集合集》,arXiv预印本)
标准注意力机制:Vaswani, Ashish, et al. “Attention is all you need.” Advances in neural information processing systems 30 (2017).(《注意力就是一切》,神经信息处理系统进展,2017年)
增量规则:Schlag, Imanol, Kazuki Irie, and Jürgen Schmidhuber. “Linear transformers are secretly fast weight programmers.” International conference on machine learning. PMLR, 2021.(《线性Transformer本质是快速权重编程器》,国际机器学习大会,PMLR出版社,2021年)
推荐学习书籍 《CDA一级教材》适合CDA一级考生备考,也适合业务及数据分析岗位的从业者提升自我。完整电子版已上线CDA网校,累计已有10万+在读~ !



 京公网安备 11010802022788号
京公网安备 11010802022788号







