


 雷达卡
雷达卡





在银行做了两年的数据分析和挖掘工作,较少接触互联网的应用场景,因此,一直都在思考一个问题,“互联网和金融,在数据挖掘上,究竟存在什么样的区别”。在对这个问题的摸索和理解过程中,发现数据挖掘本身包含很多层次。并且模型本身也是存在传统和时髦之分的。本文就想聊聊这些话题。
一、数据挖掘的层次
一直想整理下对数据挖掘不同层次的理解,这也是这两年多的时间里面,和很多金融领域、互联网做数据相关工作的小伙伴,聊天交流的一些整理和归纳。大概可以分为四类。
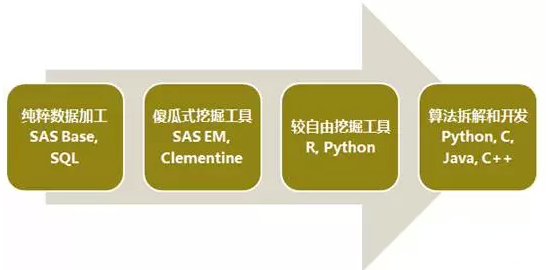
(一)纯粹的数据加工
侧重于变量加工和预处理,从源系统或数据仓库,对相关数据进行提取、加工、衍生处理,生成各种业务表。然后,以客户号为主键,把这些业务表整合汇总,最终可以拉出一张大宽表,这张宽表就可以称之为“客户画像”。即,有关客户的很多变量和特征的集合。
在这个阶段,主要的数据加工工具为SQL和SAS base。
(二)傻瓜式的挖掘工具
较为典型的就是SAS EM和clementine,里面嵌入很多较为传统成熟的算法、模块和节点(例如逻辑回归、决策树、SVM、神经网络、KNN、聚类等)。通过鼠标的托拉拽,流程式的节点,基本上就可以实现你挖掘数据的需求。
傻瓜式操作的优点就是使得数据挖掘,入手非常快,较为简单。但是,也存在一些缺陷,即,使得这个挖掘过程变得有点单调和无趣。没办法批量运算模型,也没办法开发一些个性化的算法和应用。用的比较熟练,并且想要进一步提升的时候,建议把这两者抛弃。
(三)较为自由的挖掘工具
较为典型的就是R语言和Python。这两个挖掘工具是开源的,前者是统计学家开发的,后者是计算机学家开发的。
一方面,可以有很多成熟的、前沿的算法包调用,另外一方面,还可以根据自己的需求,对既有的算法包进行修改调整,适应自己的分析需求,较为灵活。此外,Python在文本、非结构化数据、社会网络方面的处理,功能比较强大。
(四)算法拆解和自行开发
一般会利用python、c、c++,自己重新编写算法代码。例如,通过自己的代码实现逻辑回归运算过程。甚至,根据自己的业务需求和数据特点,更改其中一些假定和条件,以便提高模型运算的拟合效果。尤其,在生产系统上,通过C编写的代码,运行速度比较快,较易部署,能够满足实时的运算需求。
一般来说,从互联网的招聘和对技能的需求来说,一般JD里面要求了前三种,这样的职位会被称为“建模分析师”。但是如果增加上了最后一条,这样的职位或许就改称为“算法工程师”。
二、模型的理解:传统的和时髦的
据理解,模型应该包括两种类型。一类是传统的较为成熟的模型,另外一类是较为时髦有趣的模型。对于后者,大家会表现出更多的兴趣,一般是代表着新技术、新方法和新思路。
(一)传统的模型
传统的模型,主要就是为了解决分类(例如决策树、神经网络、逻辑回归等)、预测(例如回归分析、时间序列等)、聚类(kmeans、系谱、密度聚类等)、关联(无序关联和有序关联)这四类问题。这些都是较为常规和经典的。
(二)时髦有趣的模型
比较有趣、前沿的模型,大概包括以下几种类型,即社会网络分析、文本分析、基于位置的服务(Location-Based Service,LBS)、数据可视化等。
它们之所以比较时髦,可能的原因是,采用比较新颖前沿的分析技术(社会网络、文本分析),非常贴近实际的应用(LBS),或者是能够带来更好的客户体验(数据可视化)。

(1)社会网络的应用
传统的模型将客户视为单一个体,忽视客户之间的关系,基于客户的特征建立模型。社会网络是基于群体的,侧重研究客户之间的关联,通过网络、中心度、联系强度、密度,得到一些非常有趣的结果。典型的应用,例如,关键客户的识别、新产品的渗透和扩散、微博的传播、风险的传染、保险或信用卡网络团伙欺诈、基于社会网络的推荐引擎开发等。
(2)文本挖掘的应用
文本作为非结构化数据,加工分析存在一定的难度,包括如何分词、如何判断多义词、如何判断词性,如何判断情绪的强烈程度。典型的应用,包括搜索引擎智能匹配、通过投诉文本判断客户情绪、通过舆情监控品牌声誉、通过涉诉文本判定企业经营风险、通过网络爬虫抓取产品评论、词云展示等。

文本和湿人。关于文本分析,最近朋友圈有篇分享,很有意思,号称可以让你瞬间变成湿人。原理很简单,就是先把《全宋词》分词,然后统计频数前100的词语。然后你可以随机凑6个数(1-100),这样就可以拼凑出两句诗。比如,随机写两组数字,(2,37,66)和(57,88,33),对应的词语为(东风、无人、黄花)和(憔悴、今夜、风月)。组成两句诗,即“东风无人黄花落,憔悴今夜风月明”。还真像那么一回事,有兴趣可以玩一玩。
(3)LBS应用
即基于位置的服务,即如何把服务和用户的地理位置结合。当下的APP应用,如果不能很好地和地理位置结合,很多时候很难有旺盛的生命力。典型的APP,例如大众点评(餐饮位置)、百度地图(位置和路径)、滴滴打车、微信位置共享、时光网(电影院位置)等服务。此外,银行其实也在研究,如何把线上客户推送到距离客户最近的网点,完成O2O的完美对接,从而带来更好的客户体验。
(4)可视化应用
基于地图的一些可视化分析,比较热门,例如,春节人口迁徙图、微信活跃地图、人流热力图、拥堵数据的可视化、社会网络扩散可视化等。
如果你想让你的分析和挖掘比较吸引眼球,请尽量往以上四个方面靠拢。
三、互联网和金融数据挖掘的差异
博士后两年,对银行领域的数据挖掘有些基本的了解和认识,但是面对浩瀚的数据领域,也只能算刚刚入门。很多时候,会很好奇互联网领域,做数据挖掘究竟是什么样的形态。
很早之前,就曾在知乎上提了个问题,“金融领域的数据挖掘和互联网中的数据挖掘,究竟有什么的差异和不同”。这个问题挂了几个月,虽有寥寥的回答,但是没有得到想要的答案。
既然没人能够提供想要的答案,那就,根据自己的理解、一些场合的碰壁、以及和一些互联网数据小伙伴的接触,试图归纳和回答下。应该有以下几个方面的差异。
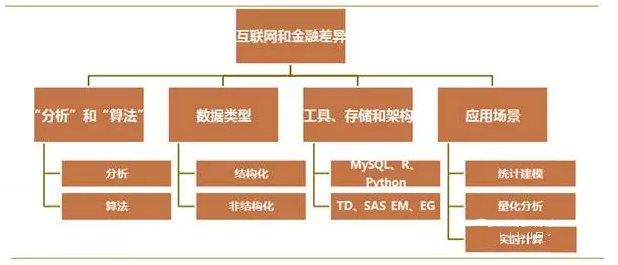
(一)“分析”和“算法”
在互联网中,“分析”和“算法”,分得非常开,对应着“数据分析师”和“算法工程师”两种角色。前者更多侧重数据提取、加工、处理、运用成熟的算法包,开发模型,探索数据中的模式和规律。后者更多的是,自己写算法代码,通过C或python部署到生产系统,实时运算和应用。
在银行领域,基本上,只能看到第一种角色。数据基本上来源于仓库系统,然后运用SQL、SAS、R,提取、加工、建模和分析。
(二)数据类型
数据类型,主要包括“结构化”和“非结构化”两类数据。前者就是传统的二维表结构。一行一条记录,一列一个变量。后者包括文本、图像、音频、视频等。
银行里面的数据,更多的是结构化数据,也有少量的非结构化数据(投诉文本、贷款审批文本等)。业务部门对非结构化数据的分析需求比较少。因此,在非结构化数据的分析建模方面,稍显不足。
互联网,更多的是网络日志数据,以文本等非结构化数据为主,然后通过一定的工具将非结构化数据转变为结构化数据,进一步加工和分析。
(三)工具、存储和架构
互联网,基本上是免费导向,所以常常选择开源的工具,例如MySql、R、Python等。常常是基于hadoop的分布式数据采集、加工、存储和分析。
商业银行一般基于成熟的数据仓库,例如TD,以及一些成熟的数据挖掘工具,SAS EG和EM。
(四)应用场景
在应用场景上,两者之间也存在着非常大的差异。
(1)金融领域
金融领域的数据挖掘,不同的细分行业(如银行和证券),也是存在差别的。
银行领域的统计建模。银行内的数据挖掘,较为侧重统计建模,数据分析对象主要为截面数据,一般包括客户智能(CI)、运营智能(OI)和风险智能(RI)。开发的模型以离线为主,少量模型,例如反欺诈、申请评分,对实时性的要求比较高。
证券领域的量化分析。证券行业的挖掘工作,更加侧重量化分析,分析对象更多的是时间序列数据,旨在从大盘指数、波动特点、历史数据中发现趋势和机会,进行短期的套利操作。量化分析的实时性要求也比较高,可能是离线运算模型,但是在交易系统部署后,实时运算,捕捉交易事件和交易机会。
(2)互联网
互联网的实时计算。互联网的应用场景,例如推荐引擎、搜索引擎、广告优化、文本挖掘(NLP)、反欺诈分析等,很多时候需要将模型部署在生产系统,对实时响应要求比较高,需要保证比较好的客户体验。
四、数据挖掘在金融领域的典型应用
别人常常会问,在银行里面,数据挖掘究竟是做什么的。也常常在思考如何从对方的角度回答这个问题。举几个常见的例子做个诠释。

(一)信用评分
申请评分。当你申请信用卡、消费贷款、经营贷款时,银行是否会审批通过,发放多大规模的额度?这个判断很可能就是申请评分模型运算的结果。通过模型计算你的还款能力和还款意愿,综合评定放款额度和利率水平。
行为评分。当你信用卡使用一段时间后,银行会根据你的刷卡行为和还款记录,通过行为评分模型,判断是否给你调整固定额度。
(二)个性化产品推荐
很多时候,你可能会收到银行推送的短信或者接到银行坐席的外呼,比如,向你推荐某款理财产品。这背后,很可能就是产品响应模型运算的结果。银行会通过模型,计算你购买某款理财产品的概率,如果概率比价高的话,就会向你推送这款理财产品。
此外,很多时候,不同的客户,银行会个性化的推荐不同的产品,很可能就是产品关联分析模型运算的结果。
(三)个性化广告展示
登陆商业银行网站时,通常会有一个广告banner,banner上会展示若干幅广告。很多时候,不同的客户登陆网站,会接触到不同的广告,即个性化的广告推送。一般来说,后台经过计算,会判断,你对哪几款广告和产品感兴趣,最后推送3-5款你最感兴趣的产品,从而能够有效吸引你的注意,促进点击、转化和成交。

 京公网安备 11010802022788号
京公网安备 11010802022788号







