



 雷达卡
雷达卡
















Bayesian Statistics continues to remain incomprehensible in the ignited minds of many analysts. Being amazed by the incredible power of machine learning, a lot of us have become unfaithful to statistics. Our focus has narrowed down to exploring machine learning. Isn’t it true?
We fail to understand that machine learning is only one way to solve real world problems. In several situations, it does not help us solve business problems, even though there is data involved in these problems. To say the least, knowledge of statistics will allow you to work on complex analytical problems, irrespective of the size of data.
In 1770s, Thomas Bayes introduced ‘Bayes Theorem’. Even after centuries later, the importance of ‘Bayesian Statistics’ hasn’t faded away. In fact, today this topic is being taught in great depths in some of the world’s leading universities.
With this idea, I’ve created this beginner’s guide on Bayesian Statistics. I’ve tried to explain the concepts in a simplistic manner with examples. Prior knowledge of basic probability & statistics is desirable. By the end of this article, you will have a concrete understanding of Bayesian Statistics and its associated concepts.
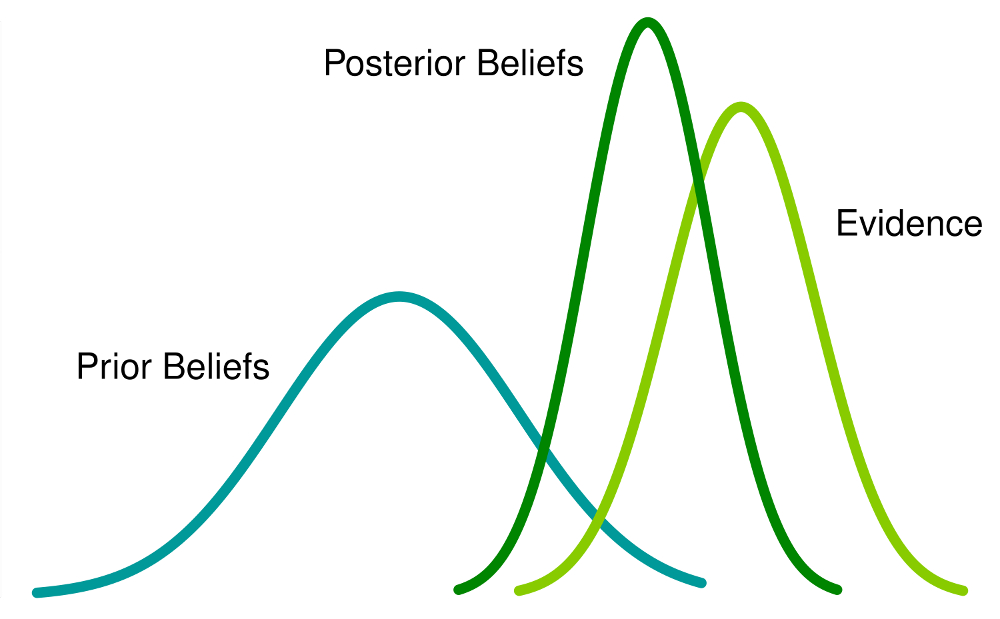
Table of Contents
- Frequentist Statistics
- The Inherent Flaws in Frequentist Statistics
- Bayesian Statistics
- Conditional Probability
- Bayes Theorem
- Bayesian Inference
- Bernoulli likelihood function
- Prior Belief Distribution
- Posterior belief Distribution
- Test for Significance – Frequentist vs Bayesian
- p-value
- Confidence Intervals
- Bayes Factor
- High Density Interval (HDI)
Before we actually delve in Bayesian Statistics, let us spend a few minutes understanding Frequentist Statistics, the more popular version of statistics most of us come across and the inherent problems in that.
1. Frequentist Statistics
The debate between frequentist and bayesian have haunted beginners for centuries. Therefore, it is important to understand the difference between the two and how does there exists a thin line of demarcation!
It is the most widely used inferential technique in the statistical world. Infact, generally it is the first school of thought that a person entering into the statistics world comes across.
Frequentist Statistics tests whether an event (hypothesis) occurs or not. It calculates the probability of an event in the long run of the experiment (i.e the experiment is repeated under the same conditions to obtain the outcome).
Here, the sampling distributions of fixed size are taken. Then, the experiment is theoretically repeatedinfinite number of times but practically done with a stopping intention. For example, I perform an experiment with a stopping intention in mind that I will stop the experiment when it is repeated 1000 times or I see minimum 300 heads in a coin toss.
Let’s go deeper now.
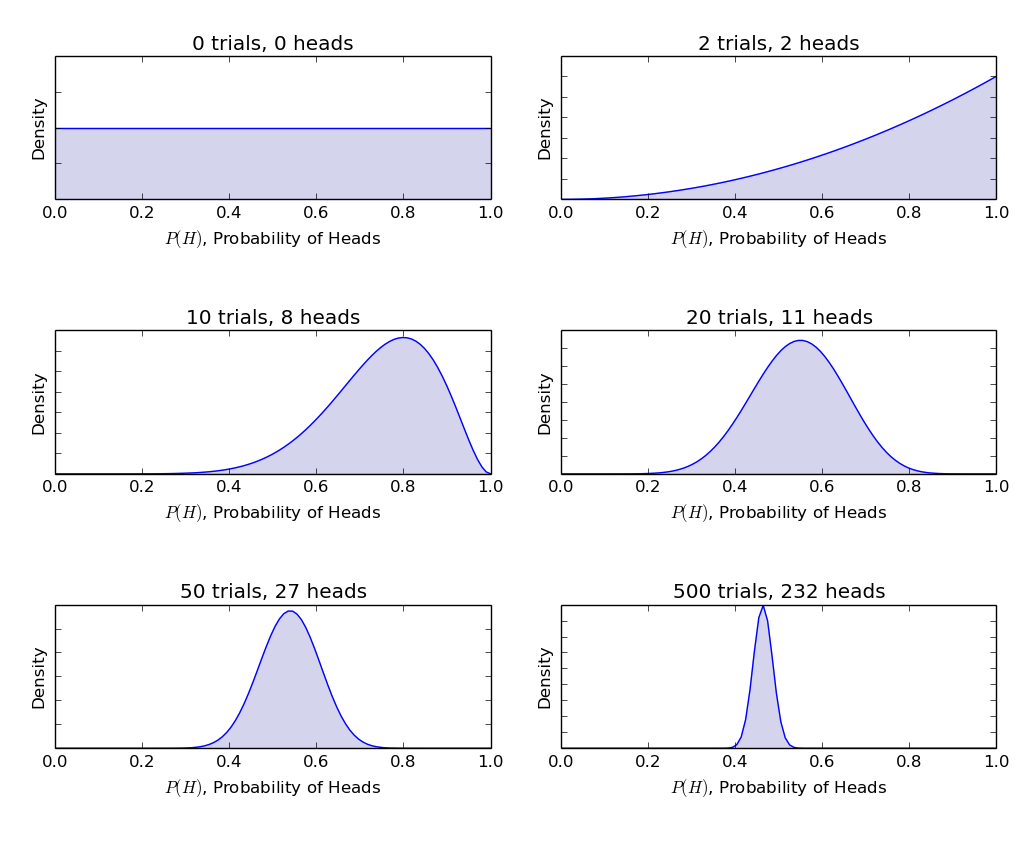
Now, we’ll understand frequentist statistics using an example of coin toss. The objective is to estimate the fairness of the coin. Below is a table representing the frequency of heads:

We know that probability of getting a head on tossing a fair coin is 0.5. No. of heads represents the actual number of heads obtained. Difference is the difference between0.5*(No. of tosses) - no. of heads.
An important thing is to note that, though the difference between the actual number of heads and expected number of heads( 50% of number of tosses) increases as the number of tosses are increased, the proportion of number of heads to total number of tosses approaches 0.5 (for a fair coin).
This experiment presents us with a very common flaw found in frequentist approach i.e. Dependence of the result of an experiment on the number of times the experiment is repeated.
To know more about frequentist statistical methods, you can head to this excellent course on inferential statistics.
2. The Inherent Flaws in Frequentist Statistics
Till here, we’ve seen just one flaw in frequentist statistics. Well, it’s just the beginning.
20th century saw a massive upsurge in the frequentist statistics being applied to numerical models to check whether one sample is different from the other, a parameter is important enough to be kept in the model and variousother manifestations of hypothesis testing. But frequentist statistics suffered some great flaws in its design and interpretation which posed a serious concern in all real life problems. For example:
1. p-values measured against a sample (fixed size) statistic with some stopping intention changes with change in intention and sample size. i.e If two persons work on the same data and have different stopping intention, they may get two different p- values for the same data, which is undesirable.
For example: Person A may choose to stop tossing a coin when the total count reaches 100 while B stops at 1000. For different sample sizes, we get different t-scores and different p-values. Similarly, intention to stop may change from fixed number of flips to total duration of flipping. In this case too, we are bound to get different p-values.
2- Confidence Interval (C.I) like p-value depends heavily on the sample size. This makes the stopping potential absolutely absurd since no matter how many persons perform the tests on the same data, the results should be consistent.
3- Confidence Intervals (C.I) are not probability distributions therefore they do not provide the most probable value for a parameter and the most probable values.
These three reasons are enough to get you going into thinking about the drawbacks of the frequentist approach and why is there a need for bayesian approach. Let’s find it out.
From here, we’ll first understand the basics of Bayesian Statistics.
 提升卡
提升卡 置顶卡
置顶卡 沉默卡
沉默卡 变色卡
变色卡 抢沙发
抢沙发 千斤顶
千斤顶 显身卡
显身卡

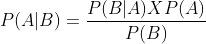
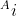 form an exhaustive set with another event B. This could be understood with the help of the below diagram.
form an exhaustive set with another event B. This could be understood with the help of the below diagram.
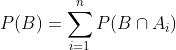
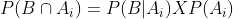
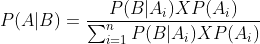
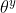 [If coin is fair θ=0.5, probability of observing heads (y=1) is 0.5]
[If coin is fair θ=0.5, probability of observing heads (y=1) is 0.5]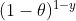 [If coin is fair θ=0.5, probability of observing tails(y=0) is 0.5]
[If coin is fair θ=0.5, probability of observing tails(y=0) is 0.5]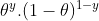
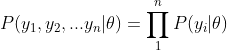
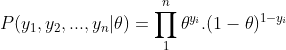
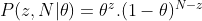
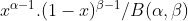






 京公网安备 11010802022788号
京公网安备 11010802022788号







