



 雷达卡
雷达卡
















Here's a curated short list of interesting and insightful talks to watch from SciPy 2016 to help guide your search through the volume of great video material emerging from the conference.
By Matthew Mayo, KDnuggets.SciPy 2016, the 15th annual Scientific Computing with Python Conference, took place in Austin, Texas, last week from July 11 to 17. The conference was made up of tutorials, talks, and developer sprints, and brought together more than 650 participants from industry, academia, and government. From all accounts, the conference was a success, and lots of interesting projects were debuted or thrust into greater prominence as a direct result of the conference.

As expected, many of the talks and tutorials were recorded and have made their way onto YouTube. Most of us are short on time, however, and combing through tens of hours (or more) of video is completely out of the question. So let's narrow down the field.
Conference attendee Qingkai Kong, of the University of California, Berkeley, put together a great list of interesting things he learnedwhile at SciPy. The post is a very inclusive list of projects, as opposed to talks, that came to his attention while onsite, but there is a relationship between SciPy projects and talks. This list can help us narrow things down.
We also asked Sebastian Raschka, conference attendee, PhD candidate at Michigan State University, and author of the pre-eminent book on machine learning with Python, for a short off-the-cuff list of his favorite talks, and he was good enough to provide us with a tight 6.
Beyond Sebastian's picks, I have used Qingkai's post as guidance as I perused the talk videos that have made their way online to come up with a few additional to round out the list of 10 Great Talks From SciPy 2016, listed below:
1. Machine Learning with scikit-learn Part 1 & Part 2 - Andreas Mueller & Sebastian Raschka
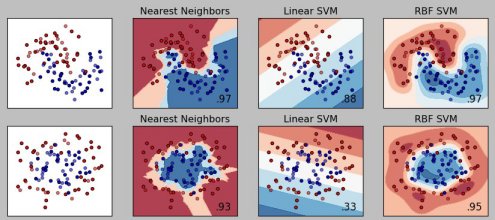
First, since Sebastian wouldn't include the tutorial he and his Andreas Mueller put on, let's get it out of the way first. In 2 parts, this introductory-to-intermediate level tutorial on machine learning with scikit-learn should definitely be on the list. It's not short, at nearly 6 hours in total, but alongside Raschka's book, this is a pretty good place to start practicing machine learning with Python.
Sebastian recommends (with quotes directly from the relevant speakers' talk descriptions):
2. Reproducible, One-Button Workflows with the Jupyter Notebook and Scons - Jessica Hamrick, UC Berkeley
What is the best way to develop analysis code in the Jupyter notebook, while managing complex dependencies between analyses? In this talk, I will introduce nbflow, which is a project that integrates a Python-based build system (SCons) with the Jupyter notebook, enabling researchers to easily build sophisticated, complex analysis pipelines entirely within notebooks while still maintaining a "one-button workflow" in which all analyses can be executed, in the correct order, from a single command.
3. Reinventing the .whl: New Developments in the Upstream Python Packaging Ecosystem - Nathaniel Smith, UC Berkeley
In this talk, I'll describe how members of the scientific Python community have been working with upstream Python to solve some of the worst issues, and show you how to build and distribute binary wheels for Linux users, build Windows packages without MSVC, use wheels to handle dependencies on non-Python libraries like BLAS or libhdf5, plus give the latest updates on our effort to drive a stake through the heart of setup.py files and replace them with something better.
4. High Quality, High Performance Clustering with HDBSCAN - Leland McInnes, Tutte Institute for Mathematics and Computing
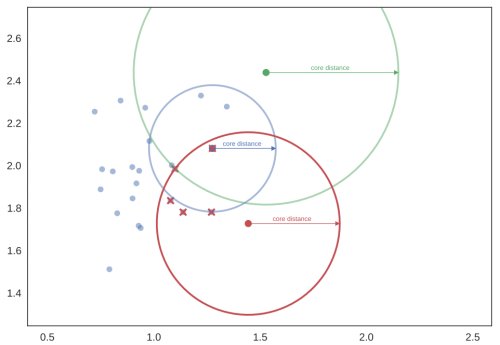
We will discuss how the algorithm works, taking a few different perspectives, and explain the techniques used for a high performance implementation. Finally we'll discuss ways to extend the algorithm, drawing on ideas from topological data analysis.
5. Datashader: Revealing the Structure of Genuinely Big Data - James A. Bednar, Continuum Analytics and University of Edinburgh
The new datashader library makes it practical to work with data at a large scale, easily and interactively visualizing millions or billions of points. In this talk, we'll demonstrate how datashader provides a flexible pipeline for data processing that allows automatic or custom-defined algorithms at every stage.
6. SymEngine: A Fast Symbolic Manipulation Library - Ondřej Čertík, Los Alamos National Laboratory, Isuru Fernando, Thilina Rathnayakem, Abhinav Agarwal, Indian Institute of Technology Kharagpur
The goal of SymEngine is to be the fastest C++ symbolic manipulation library (opensource or commercial), compatible with SymPy, that can be used from many languages (Python, Ruby, Julia, ...). We will present the current status of development, how things are implemented internally, why we chose C++, benchmarks, and examples of usage from Python (SymPy and Sage), Ruby and Julia.
7. Automatic Machine Learning? - Andreas Mueller
This talk will summarize recent progress in automating machine learning and give an overview of the tools currently available. It will also point out areas where the ecosystem needs to improve in order to allow a wider access to inference using data science techniques.
And a few additional talks that I have found interesting as a latecomer:

8. JupyterLab: Building Blocks for Interactive Computing - Brian Granger
While the Jupyter Notebook has proved to be an incredibly productive way of working with code and data interactively, it is helpful to decompose notebooks into more primitive building blocks: kernels for code execution, input areas for typing code, markdown cells for composing narrative content, output areas for showing results, terminals, etc. The fundamental idea of JupyterLab is to offer a user interface that allows users to assemble these building blocks in different ways to support interactive workflows that include, but go far beyond, Jupyter Notebooks.
9. Dask Parallel and Distributed Computing - Matthew Rocklin
This talk discusses Pythonic APIs for parallel algorithm development as well as strategies for intuitive and efficient distributed computing. We discuss recent results in machine learning and novel scientific applications.
10. What's new in Spyder 3.0 - Carlos Cordoba
This version (Spyder 3.0) represents almost two years of development and brings important characteristics that we would like to introduce to the SciPy community. Among them we can find: the ability tocreate and install third-party plugins, improved projects support, syntax highlighting and code completion for all programming languages supported by Pygments, a new file switcher (similar to the one present in Sublime Text), code folding for the Editor, Emacs keybindings for the entire application, a Numpy array graphical builder, and a fully dark theme for the interface.
Bonus: SciPy 2016 Lightning Talks
My thanks to Sebastian Raschka for his contribution, and to Qingkai Kong for putting together a great resource.
 提升卡
提升卡 置顶卡
置顶卡 沉默卡
沉默卡 变色卡
变色卡 抢沙发
抢沙发 千斤顶
千斤顶 显身卡
显身卡


 京公网安备 11010802022788号
京公网安备 11010802022788号







