



 雷达卡
雷达卡
















Check out 5 Big Data projects that you are not likely to have seen before, but which may be useful to you, and perhaps even scratch an itch you didn't know you had.
By Matthew Mayo, KDnuggets.The Big Data Ecosystem is big. Some say it's too damn big!
Consider, first, the behemoths in the space, the Big Data processing frameworks: Hadoop. Spark. Flink. Any of the other umpteen Apache projects. Google's platforms. Many others. They all work in the same general space, but with various differentiating factors.
Next consider the support tools in the various data processing ecosystems. Then have a look at the various data stores and NoSQL database engines available. Then think about all of the tools that fit particular niches, both "official" and unofficial, that grow out of both large companies and individuals' ingenuity.
It is this final category that we are concerned with herein. We will take a look at 5 Big Data projects that are outside of the mainstream, but which still have something to offer, perhaps unexpectedly so.

As always, finding overlooked projects is much more art than science. I collected these projects over the course of time spent online over an extended period. The only criteria was that the projects were not alpha-level projects (subjective, no?), caught my eye for some particular reason, and had Github repos. The projects are not presented in any particular order, but are numbered like they are, mostly for ease of referencing, but also because I like numbering things.
1. Luigi
Luigi was originally developed at Spotify, and is used to craft data pipeline jobs. From its Github repository README:
Luigi is a Python module that helps you build complex pipelines of batch jobs. It handles dependency resolution, workflow management, visualization etc.
Luigi stresses that it does not replace lower-level data-processing tools such as Hive or Pig, but is instead meant to create workflows between numerous tasks. Luigi supports Hadoop out of the box as well, which potentially makes it a much more attractive option for many, many users. Luigi also supports file system abstractions for HDFS, and local files enforce operation atomicity, which is essential for ensuring state between pipeline tasks.
Luigi also comes with a web interface for visualizing and managing your tasks:

Luigi is also gaining in popularity, and currently boasts nearly 5000 repo stars on Github, which is impressive for something I'm categorizing as "not popular." If you are interested in seeing it in action, here is a tutorial on using Luigi together with Python to build data pipelines, written by Marco Bonzanini.
I'm a fan of pipelines; if you are too, Luigi may be a project worth checking out for managing your data processing tasks and workflows.
2. Lumify

Lumify is an open source big data analysis and visualization platform.
Developer Altamira reasons that the appropriate tools for exploiting data and extracting insight were not well-enough developed, and so they took it upon themselves to design Lumify, a tool to aggregate, organize, and extract insight from your data. Among other things, Lumify is built to analyze relationships within data; perform geographical data analysis; organize data and collaborate in real time.
Its official website has thorough documentation, a set of introductory videos, and an online instance of Lumify for testing, without regard to installation and configuration.
3. Google Cloud Platform Hadoop-interoperability Tools
This project comes to us from Google Cloud Platform's official Github. It is described as:
Libraries and tools for interoperability between Hadoop-related open-source software and Google Cloud Platform.

The main component of this project is the Google Cloud Storage connector for Hadoop (see full description here). The benefit of the connector is being able to run MapReduce jobs on data in Google Cloud Storage by implementing the Hadoop FileSystem interface. Benefits of doing so include:
- Direct data access
- HDFS compatibility
- Interoperability
- Data accessibility
- No storage management overhead
- Quick startup
This project fits a very particular niche, but if you are looking to run Map-Reduce jobs on your own data in HDFS on the Google Cloud Platform, this project is likely worth investigating.
4. Presto
Need a new option for SQL query? Read that correctly: not SQL (relational) storage, but SQL query.

Presto is a distributed SQL query engine for big data.
Presto is a distributed SQL database for the gigabyte to petabyte range, and data sources of all types. Presto is built to query data where it resides, be that Hive, Cassandra, relational databases, or more, and a single query can encompass multiple sources. It is designed for both speed and scalability. Presto is written in Java, and runs on OSX and Linux.
The official site has solid documentation, and provides a good project introduction. For a quick overview, check this 5 minute video from Teradata; for a more detailed detailed, see this video outliningFacebook's use of Presto for querying a diverse data store setup.
Presto should be useful for those of us looking to increase the speed of our SQL queries without having to make changes and investments related to where that queried data is stored. It promises to be even more useful for scenarios where data is stored across multiple platforms.
5. Clusterize
From Denis Lukov comes perhaps the most off-beat of the projects included in this collection. As opposed to back-end or data science/engineering tools like the previous 4, Clusterize is a front-end development project written in Javascript. From the repo README:
Tiny vanilla JS plugin to display large data sets easily.
Clusterize is a simple, yet clever, tool for scrolling through large sets of data, with a scroll progress meter overlay on top of the records as they pass. The outcome is something that looks like this:
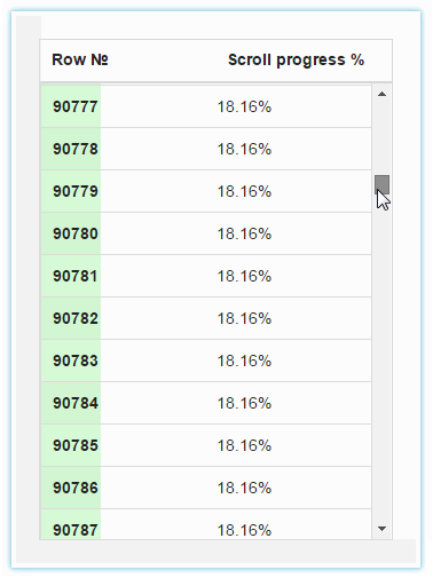
Clusterize claims to remove the lag that comes with scrolling through large sets of data, and promises to scale to handle half a million rows as effortlessly as it deals with 5000. Does this qualify it as a Big Data project? You tell me; it's certainly interesting and could be useful to lots of developers, regardless of its exact classification.
Again, this project is much more useful for a web developer than a data pipeline engineer or a data scientist. But data is growing for everyone, not just for these professions. Developers of all types are dealing with this data overgrowth, and fine tools like this one to help cope are popping up and gaining endorsements.
 提升卡
提升卡 置顶卡
置顶卡 沉默卡
沉默卡 变色卡
变色卡 抢沙发
抢沙发 千斤顶
千斤顶 显身卡
显身卡




 京公网安备 11010802022788号
京公网安备 11010802022788号







