



 雷达卡
雷达卡
















A sample of data is a snapshot from a broader population of all possible observations that could be taken of a domain or generated by a process.
Interestingly, many observations fit a common pattern or distribution called the normal distribution, or more formally, the Gaussian distribution. A lot is known about the Gaussian distribution, and as such, there are whole sub-fields of statistics and statistical methods that can be used with Gaussian data.
In this tutorial, you will discover the Gaussian distribution, how to identify it, and how to calculate key summary statistics of data drawn from this distribution.
After completing this tutorial, you will know:
- That the Gaussian distribution describes many observations, including many observations seen during applied machine learning.
- That the central tendency of a distribution is the most likely observation and can be estimated from a sample of data as the mean or median.
- That the variance is the average deviation from the mean in a distribution and can be estimated from a sample of data as the variance and standard deviation.
Let’s get started.
 A Gentle Introduction to Calculating Normal Summary Statistics
A Gentle Introduction to Calculating Normal Summary StatisticsPhoto by John, some rights reserved.
Tutorial Overview
This tutorial is divided into 6 parts; they are:
- Gaussian Distribution
- Sample vs Population
- Test Dataset
- Central Tendencies
- Variance
- Describing a Gaussian
A distribution of data refers to the shape it has when you graph it, such as with a histogram.
The most commonly seen and therefore well-known distribution of continuous values is the bell curve. It is known as the “normal” distribution, because it the distribution that a lot of data falls into. It is also known as the Gaussian distribution, more formally, named for Carl Friedrich Gauss.
As such, you will see references to data being normally distributed or Gaussian, which are interchangeable, both referring to the same thing: that the data looks like the Gaussian distribution.
Some examples of observations that have a Gaussian distribution include:
- People’s heights.
- IQ scores.
- Body temperature.
Let’s look at a normal distribution. Below is some code to generate and plot an idealized Gaussian distribution.
# generate and plot an idealized gaussian from numpy import arange from matplotlib import pyplot from scipy.stats import norm # x-axis for the plot x_axis = arange(-3, 3, 0.001) # y-axis as the gaussian y_axis = norm.pdf(x_axis, 0, 1) # plot data pyplot.plot(x_axis, y_axis) pyplot.show()Running the example generates a plot of an idealized Gaussian distribution.
The x-axis are the observations and the y-axis is the frequency of each observation. In this case, observations around 0.0 are the most common and observations around -3.0 and 3.0 are rare or unlikely.
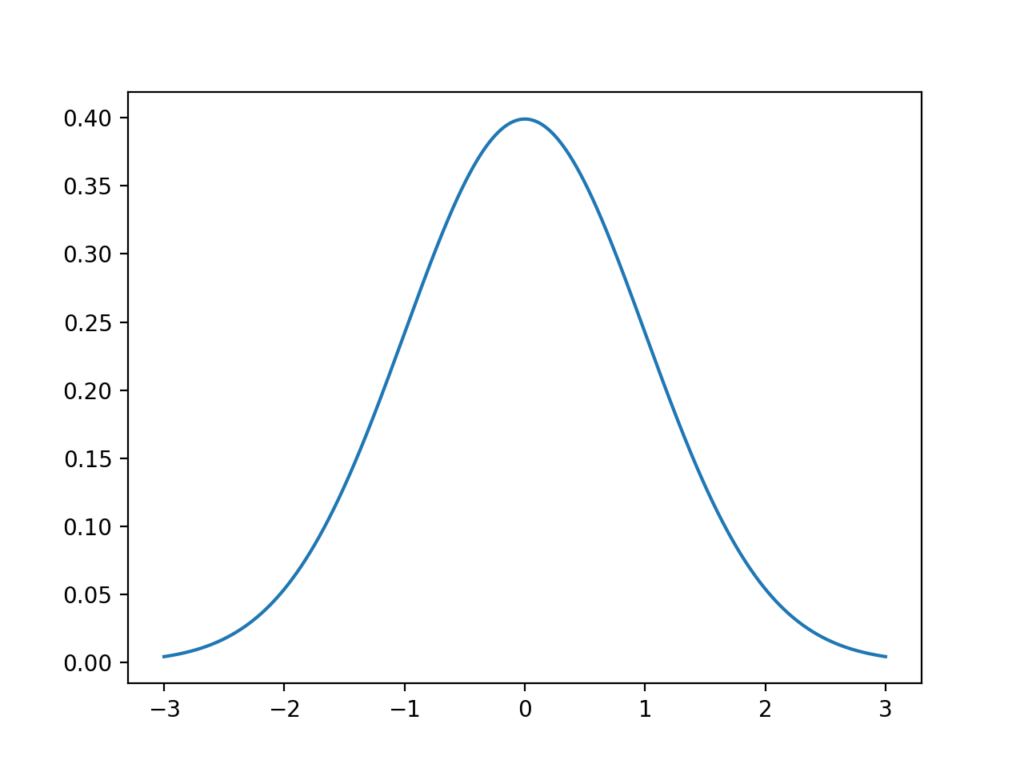 Line Plot of Gaussian Distribution
Line Plot of Gaussian DistributionIt is helpful when data is Gaussian or when we assume a Gaussian distribution for calculating statistics. This is because the Gaussian distribution is very well understood. So much so that large parts of the field of statistics are dedicated to methods for this distribution.
Thankfully, many of the data we work with in machine learning often fits a Gaussian distribution, such as the input data we may use to fit a model, to the repeated evaluation of a model on different samples of training data.
Not all data is Gaussian, and it is sometimes important to make this discovery either by reviewing histogram plots of the data or using statistical tests to check. Some examples of observations that do not fit a Gaussian distribution include:
- People’s incomes.
- Population of cities.
- Sales of books.
We can think of data being generated by some unknown process.
The data that we collect is called a data sample, whereas all possible data that could be collected is called the population.
- Data Sample: A subset of observations from a group.
- Data Population: All possible observations from a group.
This is an important distinction because different statistical methods are used on samples vs populations, and in applied machine learning, we are often working with samples of data. If you read or use the word “population” when talking about data in machine learning, it very likely means sample when it comes to statistical methods.
Two examples of data samples that you will encounter in machine learning include:
- The train and test datasets.
- The performance scores for a model.
When using statistical methods, we often want to make claims about the population using only observations in the sample.
Two clear examples of this include:
- The training sample must be representative of the population of observations so that we can fit a useful model.
- The test sample must be representative of the population of observations so that we can develop an unbiased evaluation of the model skill.
Because we are working with samples and making claims about a population, it means that there is always some uncertainty, and it is important to understand and report this uncertainty.
Test DatasetBefore we explore some important summary statistics for data with a Gaussian distribution, let’s first generate a sample of data that we can work with.
We can use the randn() NumPy function to generate a sample of random numbers drawn from a Gaussian distribution.
There are two key parameters that define any Gaussian distribution; they are the mean and the standard deviation. We will go more into these parameters later as they are also key statistics to estimate when we have data drawn from an unknown Gaussian distribution.
The randn() function will generate a specified number of random numbers (e.g. 10,000) drawn from a Gaussian distribution with a mean of zero and a standard deviation of 1. We can then scale these numbers to a Gaussian of our choosing by rescaling the numbers.
This can be made consistent by adding the desired mean (e.g. 50) and multiplying the value by the standard deviation (5).
data = 5 * randn(10000) + 50We can then plot the dataset using a histogram and look for the expected shape of the plotted data.
The complete example is listed below.
# generate a sample of random gaussians from numpy.random import seed from numpy.random import randn from matplotlib import pyplot # seed the random number generator seed(1) # generate univariate observations data = 5 * randn(10000) + 50 # histogram of generated data pyplot.hist(data) pyplot.show()Running the example generates the dataset and plots it as a histogram.
We can almost see the Gaussian shape to the data, but it is blocky. This highlights an important point.
Sometimes, the data will not be a perfect Gaussian, but it will have a Gaussian-like distribution. It is almost Gaussian and maybe it would be more Gaussian if it was plotted in a different way, scaled in some way, or if more data was gathered.
Often, when working with Gaussian-like data, we can treat it as Gaussian and use all of the same statistical tools and get reliable results.
 Histogram plot of Gaussian Dataset
Histogram plot of Gaussian DatasetIn the case of this dataset, we do have enough data and the plot is blocky because the plotting function chooses an arbitrary sized bucket for splitting up the data. We can choose a different, more granular way to split up the data and better expose the underlying Gaussian distribution.
The updated example with the more refined plot is listed below.
# generate a sample of random gaussians from numpy.random import seed from numpy.random import randn from matplotlib import pyplot # seed the random number generator seed(1) # generate univariate observations data = 5 * randn(10000) + 50 # histogram of generated data pyplot.hist(data, bins=100) pyplot.show()Running the example, we can see that choosing 100 splits of the data does a much better job of creating a plot that clearly shows the Gaussian distribution of the data.
The dataset was generated from a perfect Gaussian, but the numbers were randomly chosen and we only chose 10,000 observations for our sample. You can see, even with this controlled setup, there is obvious noise in the data sample.
This highlights another important point: that we should always expect some noise or limitation in our data sample. The data sample will always contain errors compared to the pure underlying distribution.
 Histogram plot of Gaussian Dataset With More Bins
Histogram plot of Gaussian Dataset With More Bins 提升卡
提升卡 置顶卡
置顶卡 沉默卡
沉默卡 变色卡
变色卡 抢沙发
抢沙发 千斤顶
千斤顶 显身卡
显身卡
 Line plot of Gaussian distributions with low and high variance
Line plot of Gaussian distributions with low and high variance


 京公网安备 11010802022788号
京公网安备 11010802022788号







