



 雷达卡
雷达卡





职场漫漫,Python是岸
12个你必须知道的Python面试技巧

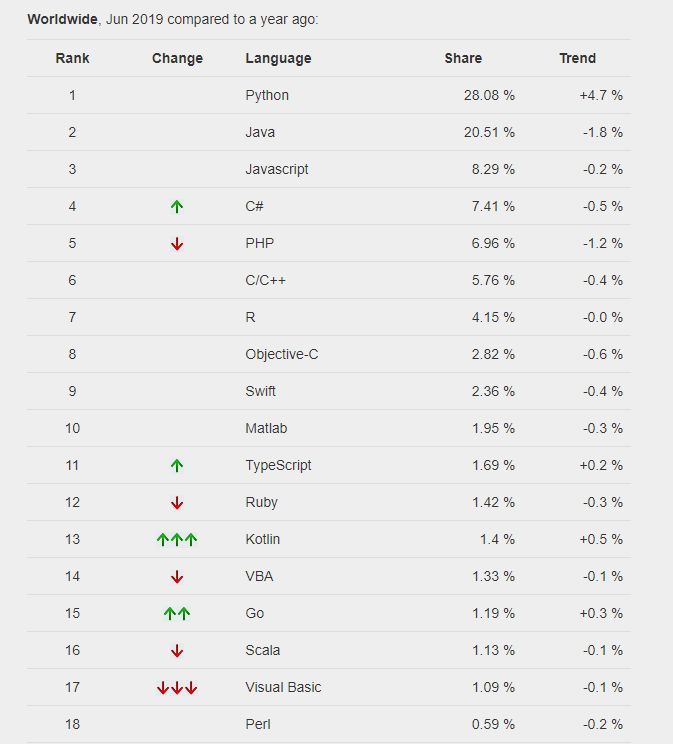
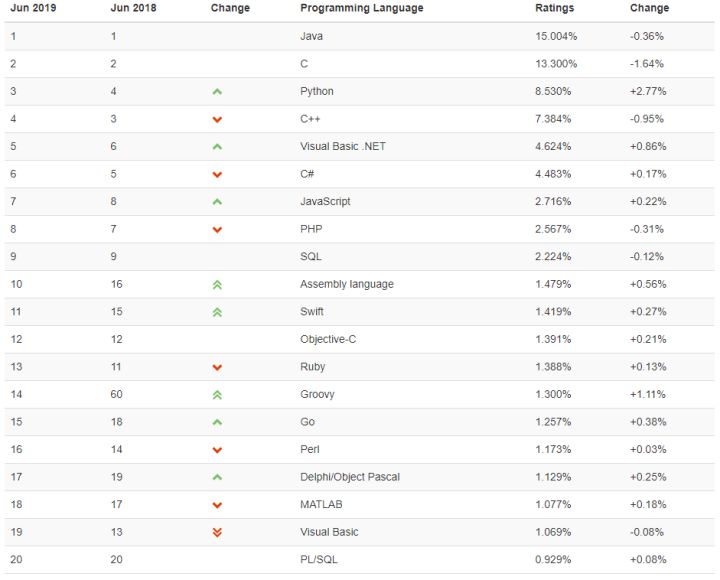
随着人工智能、机器学习、深度学习的发展,这个领域也正在不断的进入人们的眼帘,并且带来了很多、很大的工作机会,随着这些机会的诞生,Python在这个机会中也在不断的发展壮大,因为Python不像其他语言一样复杂,Python简单易学容易被人们接受。并且这并不是我一个人在这里瞎说就可以证明的,在2019年6月PYPL流行程序设计语言中,Python排在第一位占到了28.08%,是第二名Java和第三名Javascript的和,并且还在不断的上涨中。
站在这里,我认为现在正在看这篇文章的你想要找一份有关于Python的工作,不然你也不会点进来不是,你可能是一个Python的初学者,或者说已经在Python工作岗位上已经工作过了,但是如果你还需要找一份Python的工作的话,你可能需要证明你知道如何使用Python。以下是一些涉及与Python相关的基础技能的问题。重点放在语言本身,而不是任何特定的包或框架。
某种程度上来说,我还没有遇到过这么难的面试,如果你能轻松的答对这些问题,找到正确的答案,那么就快去找份工作吧。
本教程不是固定指南,灵活转变哟!
本教程不打算涵盖所有的工作场所因为不同的雇主会以不同的方式向你提出不同的问题; 他们会有各自的习惯; 他们重视的内容也是不同的。他们会以不同的方式测试你。有些老板会让你坐在电脑前,要求你解决简单的问题; 有些会让你在白板前站起来做类似的事; 有些人会给你一个需要让你回家解决的问题,方便节省他们的时间;而还有些人会和你谈谈。
而对程序员的最佳测试实际上就是编程。使用简单的教程测试是一件困难的事情。因此,为了面试过程中的加分,请确保你真的掌握了解决问题的方法。如果你真的很明白这些方法,那么你就可以利用解决问题的方法,使你获得胜利。
同样的,对于软件工程师的最有效的测试实际上是工程学。本教程是关于Python作为一种语言。能够设计高效,有效,可维护的类层次结构来解决小众问题是非常了不起的,并且是一项值得追求的技能,但是这就超出了本文的范围。
本教程不符合PEP8标准。这是有意的,因为如前所述,不同的老板将遵循不同的习惯。你需要适应公司的文化。因为实用性胜过一切。
本教程另一个不足之处是不够简洁。我不想只是向你提出问题和答案,而是希望有些事情可以解决。我希望你能够理解,或者至少理解的足够好,这样你们对任何有问题的话题能够进一步的去解释
问题1
Python到底是什么,你可以在回答中与其他技术进行比较(加分项)。
回答
以下是几个要点:
- Python是一种解释型语言。这意味着,与C语言及其变体等语言不同,Python不需要在运行之前进行编译。其他解释语言包括PHP和Ruby。
- Python是动态类型的,这意味着当你声明变量或类似的变量时,你不需要声明变量的类型。你可以做先一些事情如:x=111,然后再将x="I'm a string"这样并没有错误
- Python非常适合面向对象的编程,因为它允许类的定义以及组合和继承。Python没有访问修饰符(如C ++的public,private),对于这一点的理由是因为‘我们都是成年人’
- 在Python中,函数也是一个类对象。这意味着可以将它们分配给变量,从其他函数返回并传递给函数。类也是一个类对象
- 编写Python代码可以很快,但运行它通常比编译语言慢。但幸运的是,Python允许包含基于C的扩展,因此瓶颈可以被优化掉并且可以经常被优化。这个numpy包就是一个很好的例子,它真的非常快,因为它处理的很多数字运算实际上并不是由Python完成的
- Python可用于许多领域 - Web应用程序,自动化,科学建模,大数据应用程序等等。它也经常被用作“粘合”代码,以使其他语言和组件发挥得很好。
- Python使得困难的事情变得容易,因此程序员可以专注于重写算法和结构,而不是关注底层的低级细节。
如果你正在申请的是Python职位,你应该知道它是什么以及为什么它如此酷。
问题2
填写遗漏的代码:
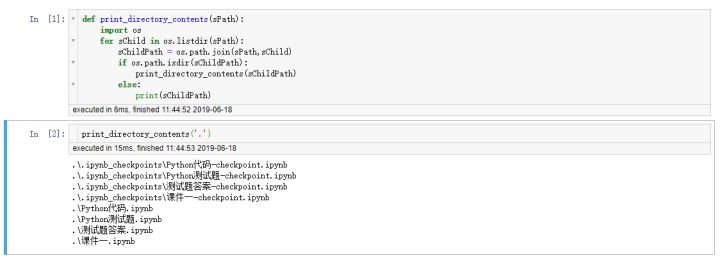
def print_directory_contents(sPath): """ 这个函数接受一个目录的名称 并且打印该目录中的路径文件 包含目录以及目录中的任何文件 这个函数类似于os.walk。 但是请不要使用这个模块系统。 输入你的答案 我们对你使用嵌套结构的能力很感兴趣 """ fill_this_in
回答
def print_directory_contents(sPath): import os for sChild in os.listdir(sPath): sChildPath = os.path.join(sPath,sChild) if os.path.isdir(sChildPath): print_directory_contents(sChildPath) else: print(sChildPath)
特别注意
- 与你的命名约定保持一致。如果在任何示例代码中都有明显的命名约定,请坚持下去。即使它不是你通常使用的命名约定
- 递归函数需要递归和终止。确认你真的了解这是如何发生的,这样你就可以避免无底的调用堆栈
- 我们使用该os模块以跨平台的方式与操作系统进行交互。你可以说,sChildPath = sPath + '/' + sChild但这不适用于Windows
- 熟悉基本的软件包是非常值得的,但是不要为了记住所有的东西而头痛,百度or谷歌是你在工作中遇到需要包的问题的时候的朋友!
- 如果你不理解代码应该做什么,请提出问题
- 保持简单,笨蛋!
为什么这很重要:
- 显示你的基本操作系统交互内容方面的知识
- 递归是非常有用的
问题3
查看下面的代码,写下A0,A1,...An的最终值。
如果你不知道什么是zip那么不用紧张。没有一个理智的雇主会要求你熟记标准库。这是help(zip)的输出。
zip(...) zip(seq1 [, seq2 [...]]) -> [(seq1[0], seq2[0] ...), (...)] Return a list of tuples, where each tuple contains the i-th element from each of the argument sequences. The returned list is truncated in length to the length of the shortest argument sequence.
如果这没有任何意义,那么就请你花几分钟去想清楚你要选择的方式。

回答
A0 = {'a': 1, 'c': 3, 'b': 2, 'e': 5, 'd': 4} # the order may vary A1 = range(0, 10) # or [0, 1, 2, 3, 4, 5, 6, 7, 8, 9] in python 2 A2 = [] A3 = [1, 2, 3, 4, 5] A4 = [1, 2, 3, 4, 5] A5 = {0: 0, 1: 1, 2: 4, 3: 9, 4: 16, 5: 25, 6: 36, 7: 49, 8: 64, 9: 81} A6 = [[0, 0], [1, 1], [2, 4], [3, 9], [4, 16], [5, 25], [6, 36], [7, 49], [8, 64], [9, 81]]
为什么这很重要
- 对于很多人来说,理解列表是一个很好的节省时间的方法,当然也是一个巨大的绊脚石
- 如果你能读懂它们,那么你也可以写下来
- 这些代码中的一部分是故意设计的很奇怪的。因为你可能需要在工作中与一些奇怪的人合作
问题4
多线程使用Python。这是个好主意吗?列出一些方法可以让一些Python代码以并行方式运行。
回答
Python不允许真正意义上的多线程。它有一个多线程包,但如果你想使用多线程来加速你的代码,那么使用它通常不是一个好主意。Python有一个名为全局解释器锁(Global Interpreter Lock(GIL))的结构。GIL确保每次只能执行一个“线程”。一个线程获取GIL,做一点工作,然后将GIL传递到下一个线程。这种情况发生的很快,因此对于人眼看来,你的线程似乎是并行运行的,但它们实际上只是轮流使用相同的CPU核心。所有这些GIL传递都增加了运行的内存。这意味着如果你想让代码运行得更快,那么使用线程包通常不是一个好主意。
使用Python的线程包也是有原因的。如果你想同时运行一些东西,并且效率不是一个问题,那么它就完全没问题了。或者,如果你正在运行需要等待某些事情的代码(例如某些IO),那么它可能会很有意义。但是线程库不会让你使用额外的CPU核心。
多线程可以外包到操作系统(通过多处理),一些调用Python代码的外部应用程序(例如,Spark或Hadoop),或者Python代码调用的一些代码例如:你可以使用你的Python代码调用一个C函数来完成昂贵的多线程事务。
为什么这很重要
因为GIL是一个A-hole。在学习GIL之前,很多人花了很多的时间在他们的Python多线程中遇到了瓶颈。
问题5
如何跟踪代码的不同版本?
回答:
版本控制!此时,你应该表现的非常兴奋,并告诉他们你如何使用Git(或任何你最喜欢的)来跟踪与Granny的通信。Git是我首选的版本控制系统,但还有其他版本控制系统,例如subversion。
为什么这很重要:
因为没有版本控制的代码就像没有杯子的咖啡。有时我们需要编写一次性丢弃的脚本,这没关系,但是如果你正在处理大量的代码,版本控制系统将是一个优势。版本控制有助于跟踪谁对代码库进行了哪些更改; 找出Bug是什么时候引入代码的; 跟踪软件的版本和发布版本; 在团队成员之间分发源代码; 部署和某些自动化。它允许你在破坏代码之前将代码转回到自己的代码之上。等等很多东西。这太棒了。
问题6
这段代码输出了什么:
def f(x,l=[]): for i in range(x): l.append(i*i) print(l) f(2) f(3,[3,2,1]) f(3)
回答
[0, 1] [3, 2, 1, 0, 1, 4] [0, 1, 0, 1, 4]
为什么重要?
第一个函数调用应该相当明显,循环将0和1附加到空列表中l.l是指向存储在内存中的列表的变量的名称。 第二个调用通过在新的内存块中创建新列表开始。l然后指向这个新列表。然后它将0,1和4附加到这个新列表中。这太好了。 第三个函数调用是奇怪的。它使用存储在原始内存块中的原始列表。这就是它从0和1开始的原因。
如果你不明白,试试这个:
l_mem = [] l = l_mem # the first call for i in range(2): l.append(i*i) print(l) # [0, 1] l = [3,2,1] # the second call for i in range(3): l.append(i*i) print(l) # [3, 2, 1, 0, 1, 4] l = l_mem # the third call for i in range(3): l.append(i*i) print(l) # [0, 1, 0, 1, 4]

问题7
什么是猴子补丁?,这是个好主意吗?
回答
猴子补丁是在定义函数或对象已经定义后进行更改的行为。例如:
import datetime datetime.datetime.now = lambda: datetime.datetime(2012, 12, 12)
大多数时候,这是一个非常糟糕的想法 - 如果事情以明确的方式运行,通常是最好的。猴子补丁的一个原因是测试。该模拟包对此还是非常有用的。
为什么这很重要
它表明你对单元测试中的方法有所了解。你提到避免使用猴子补丁会表明你不是那些喜欢花哨的代码而不喜欢可维护代码的程序员(他们就在那里,而且合作起来会非常糟糕)。它表明你对Python如何在较低层次上工作,如何实际存储和调用函数等有所了解。
问题8
这是什么东西的意思是:*args,**kwargs?我们为什么要用它呢?
回答
当我们不确定要向函数传递多少参数时,或者我们想向函数传递已存储的列表或参数元组时使用*args。**kwargs用于当我们不知道将多少关键字参数传递给函数时,或者它可以用用于关键字参数传递字典的值。标识符args和kwargs是一种约定,你也可以使用*bob,**billy但这不是明智的。
这是一个小示例:
def f(*args,**kwargs): print(args, kwargs) l = [1,2,3] t = (4,5,6) d = {'a':7,'b':8,'c':9} f() f(1,2,3) # (1, 2, 3) {} f(1,2,3,"groovy") # (1, 2, 3, 'groovy') {} f(a=1,b=2,c=3) # () {'a': 1, 'c': 3, 'b': 2} f(a=1,b=2,c=3,zzz="hi") # () {'a': 1, 'c': 3, 'b': 2, 'zzz': 'hi'} f(1,2,3,a=1,b=2,c=3) # (1, 2, 3) {'a': 1, 'c': 3, 'b': 2} f(*l,**d) # (1, 2, 3) {'a': 7, 'c': 9, 'b': 8} f(*t,**d) # (4, 5, 6) {'a': 7, 'c': 9, 'b': 8} f(1,2,*t) # (1, 2, 4, 5, 6) {} f(q="winning",**d) # () {'a': 7, 'q': 'winning', 'c': 9, 'b': 8} f(1,2,*t,q="winning",**d) # (1, 2, 4, 5, 6) {'a': 7, 'q': 'winning', 'c': 9, 'b': 8} def f2(arg1,arg2,*args,**kwargs): print(arg1,arg2, args, kwargs) f2(1,2,3) # 1 2 (3,) {} f2(1,2,3,"groovy") # 1 2 (3, 'groovy') {} f2(arg1=1,arg2=2,c=3) # 1 2 () {'c': 3} f2(arg1=1,arg2=2,c=3,zzz="hi") # 1 2 () {'c': 3, 'zzz': 'hi'} f2(1,2,3,a=1,b=2,c=3) # 1 2 (3,) {'a': 1, 'c': 3, 'b': 2} f2(*l,**d) # 1 2 (3,) {'a': 7, 'c': 9, 'b': 8} f2(*t,**d) # 4 5 (6,) {'a': 7, 'c': 9, 'b': 8} f2(1,2,*t) # 1 2 (4, 5, 6) {} f2(1,1,q="winning",**d) # 1 1 () {'a': 7, 'q': 'winning', 'c': 9, 'b': 8} f2(1,2,*t,q="winning",**d) # 1 2 (4, 5, 6) {'a': 7, 'q': 'winning', 'c': 9, 'b': 8}
为什么关心?
有时我们需要将未知数量的参数或关键字参数传递给函数。有时我们会想要存储参数或关键字参数供以后使用。有时它只是节省时间。
问题9
简要描述Python的垃圾收集机制。
回答
这里可以说很多。但你应该提到一些要点:
- Python维护对内存中每个对象的引用数量的计数。如果引用计数变为零,则关联的对象不再处于活动状态,并且可以释放分配给该对象的内存以用于其他内容
- 偶尔会发生称为“参考周期”的事情。垃圾收集器会定期查找这些并清理它们。一个例子是,如果你有两个对象o1,o2那么o1.x == o2和o2.x == o1。如果o1和o2没有被其它的东西引用那么他们不应该是活的。但是它们中的每一个都具有1的引用计数。
- 某些启发式方法用于加速垃圾收集。例如,最近创建的对象更可能已经死亡了。在创建对象时,垃圾收集器会将它们分配给几代。每个对象都有一代,而年轻一代则先处理。

问题10
按照效率顺序放置以下功能。它们都包含0到1之间的数字列表。列表可能很长。一个示例输入列表将是[random.random() for i in range(100000)]。你如何证明你的答案是正确的?
def f1(lIn): l1 = sorted(lIn) l2 = [i for i in l1 if i<0.5] return [i*i for i in l2] def f2(lIn): l1 = [i for i in lIn if i<0.5] l2 = sorted(l1) return [i*i for i in l2] def f3(lIn): l1 = [i*i for i in lIn] l2 = sorted(l1) return [i for i in l1 if i<(0.5*0.5)]
回答
最高效到最低效:f2,f1,f3。要证明这种情况,你需要对代码进行概要分析。Python有一个可爱的分析包应该可以解决问题。
import cProfile lIn = [random.random() for i in range(100000)] cProfile.run('f1(lIn)') cProfile.run('f2(lIn)') cProfile.run('f3(lIn)')
为了完成,以下是上述配置文件的输出:
>>> cProfile.run('f1(lIn)') 4 function calls in 0.045 seconds Ordered by: standard name ncalls tottime percall cumtime percall filename:lineno(function) 1 0.009 0.009 0.044 0.044 <stdin>:1(f1) 1 0.001 0.001 0.045 0.045 <string>:1(<module>) 1 0.000 0.000 0.000 0.000 {method 'disable' of '_lsprof.Profiler' objects} 1 0.035 0.035 0.035 0.035 {sorted} >>> cProfile.run('f2(lIn)') 4 function calls in 0.024 seconds Ordered by: standard name ncalls tottime percall cumtime percall filename:lineno(function) 1 0.008 0.008 0.023 0.023 <stdin>:1(f2) 1 0.001 0.001 0.024 0.024 <string>:1(<module>) 1 0.000 0.000 0.000 0.000 {method 'disable' of '_lsprof.Profiler' objects} 1 0.016 0.016 0.016 0.016 {sorted} >>> cProfile.run('f3(lIn)') 4 function calls in 0.055 seconds Ordered by: standard name ncalls tottime percall cumtime percall filename:lineno(function) 1 0.016 0.016 0.054 0.054 <stdin>:1(f3) 1 0.001 0.001 0.055 0.055 <string>:1(<module>) 1 0.000 0.000 0.000 0.000 {method 'disable' of '_lsprof.Profiler' objects} 1 0.038 0.038 0.038 0.038 {sorted}
为何关心?
定位和避免瓶颈通常是非常值得的。许多提高效率的编码都归结为常识 - 在上面的示例中,如果列表是较小的,则对列表进行排序显然会更快,因此如果你在排序之前选择过滤,这通常是一个好主意。不那么明显的东西仍然可以使用适当的工具找到。了解这些工具是件很好的事。
问题11
你失败的得地方?
错误的答案
我永远不会失败!
为什么这很重要:
表明你能够承认错误,有能力承认错误,对错误负责,并从错误中吸取教训。如果你想要成为有用的人的话,所有这些都非常重要。如果你真的很完美,那么太糟糕了,你可能需要在这里发挥一下你的想象力和创造力。
问题12
你有什么个人项目吗?
真的吗?
这表明你愿意在更新技能方面做一些更多的事情,而不是做最低限度的事。如果你在工作场所之外从事个人项目和代码工作,那么雇主更有可能将你视为一种可以增长的资产。即使他们不问这个问题,我也觉得提出这个问题很有用。

转行Python之路不易,且行且努力
这些Python面试可以会面临的问题,确实已经涉及到许多话题,答案也是故意冗长的。但迎难而上从来都是职场的必经之路,“不经一番磨难而赢来的结果估计连你自己心里都会觉得不踏实吧?”在python编程面试中,你需要证明自己的理解,如果能够以简洁的方式来表达,那么一定要这样做。我试图在答案中提供足够的信息,即使你以前从未听过其中的一些话题,也可以从中获得一些意义。我希望你在求职时发现这很有用。
互联网寒冬一直狂风呼啸,稍有不慎,我们就很有可能成为炮灰,沦为满地枯叶中的一片。也许目前的你,职业遭遇瓶颈,想提升自己在Python数据分析技能的在职人士;也许现在的你,一心想寻求新出路、新突破,决心转行到Python数据分析行业的求职人士;也许当前的你,对未来摇摆不定,有兴趣想往Python数据分析方向发展的大四学生……
是时候下定决心,好好规划一下自己的职业发展生涯了!2019即将结束,2020就要来临,或许你还在给自己找借口或理由,说什么”快到春节了,好好过个年先吧“、”新年新转变,一切都会好起来的“……是的,没错,好好过个年,一切会好起来,是我们每个职场人士都该有的好心态,但好心态不是靠催眠催出来的,好的心态是靠行动丰满起来的。
Python数据分析师集训班,为一心想变得更出色的您,全面铺开Python数据分析师职业的大门,最新一期将于2020年1月4日开课,事不宜迟,快快买好您的车票,整装起航吧!待到学成之日,也衷心祝愿您找到一份符合自己想法的工作,并且在这个工作上努力下去,不断提高自己的技能,不断提升自我,走向更高的平台,有更高的发展。
加油吧!陌生人
浏览课程及咨询:
1.CDA官网:https://www.cda.cn/kecheng/83.html?seo
2.CDA微信小程序(手机端随时随地浏览最新资讯和优质课程):








 京公网安备 11010802022788号
京公网安备 11010802022788号







