



 雷达卡
雷达卡




| 近来由于数据记录和属性规模的急剧增长,大数据处理平台和并行数据分析算法也随之出现。 近来由于数据记录和属性规模的急剧增长,大数据处理平台和并行数据分析算法也随之出现。于此同时,这也推动了数据降维处理的应用。实际上,数据量有时过犹不及。有时在数据分析应用中大量的数据反而会产生更坏的性能。 最新的一个例子是采用 2009 KDD Challenge 大数据集来预测客户流失量。 该数据集维度达到 15000 维。 大多数数据挖掘算法都直接对数据逐列处理,在数据数目一大时,导致算法越来越慢。该项目的最重要的就是在减少数据列数的同时保证丢失的数据信息尽可能少。 以该项目为例,我们开始来探讨在当前数据分析领域中最为数据分析人员称道和接受的数据降维方法。 缺失值比率 (Missing Values Ratio) 该方法的是基于包含太多缺失值的数据列包含有用信息的可能性较少。因此,可以将数据列缺失值大于某个阈值的列去掉。阈值越高,降维方法更为积极,即降维越少。该方法示意图如下:  低方差滤波 (Low Variance Filter) 与上个方法相似,该方法假设数据列变化非常小的列包含的信息量少。因此,所有的数据列方差小的列被移除。需要注意的一点是:方差与数据范围相关的,因此在采用该方法前需要对数据做归一化处理。算法示意图如下:  高相关滤波 (High Correlation Filter) 高相关滤波认为当两列数据变化趋势相似时,它们包含的信息也显示。这样,使用相似列中的一列就可以满足机器学习模型。对于数值列之间的相似性通过计算相关系数来表示,对于名词类列的相关系数可以通过计算皮尔逊卡方值来表示。相关系数大于某个阈值的两列只保留一列。同样要注意的是:相关系数对范围敏感,所以在计算之前也需要对数据进行归一化处理。算法示意图如下:  随机森林/组合树 (Random Forests) 组合决策树通常又被成为随机森林,它在进行特征选择与构建有效的分类器时非常有用。一种常用的降维方法是对目标属性产生许多巨大的树,然后根据对每个属性的统计结果找到信息量最大的特征子集。例如,我们能够对一个非常巨大的数据集生成非常层次非常浅的树,每颗树只训练一小部分属性。如果一个属性经常成为最佳分裂属性,那么它很有可能是需要保留的信息特征。对随机森林数据属性的统计评分会向我们揭示与其它属性相比,哪个属性才是预测能力最好的属性。算法示意图如下:  主成分分析 (PCA) 主成分分析是一个统计过程,该过程通过正交变换将原始的 n 维数据集变换到一个新的被称做主成分的数据集中。变换后的结果中,第一个主成分具有最大的方差值,每个后续的成分在与前述主成分正交条件限制下与具有最大方差。降维时仅保存前 m(m < n) 个主成分即可保持最大的数据信息量。需要注意的是主成分变换对正交向量的尺度敏感。数据在变换前需要进行归一化处理。同样也需要注意的是,新的主成分并不是由实际系统产生的,因此在进行 PCA 变换后会丧失数据的解释性。如果说,数据的解释能力对你的分析来说很重要,那么 PCA 对你来说可能就不适用了。算法示意图如下:  反向特征消除 (Backward Feature Elimination) 在该方法中,所有分类算法先用 n 个特征进行训练。每次降维操作,采用 n-1 个特征对分类器训练 n 次,得到新的 n 个分类器。将新分类器中错分率变化最小的分类器所用的 n-1 维特征作为降维后的特征集。不断的对该过程进行迭代,即可得到降维后的结果。第k 次迭代过程中得到的是 n-k 维特征分类器。通过选择最大的错误容忍率,我们可以得到在选择分类器上达到指定分类性能最小需要多少个特征。算法示意图如下:  前向特征构造 (Forward Feature Construction) 前向特征构建是反向特征消除的反过程。在前向特征过程中,我们从 1 个特征开始,每次训练添加一个让分类器性能提升最大的特征。前向特征构造和反向特征消除都十分耗时。它们通常用于输入维数已经相对较低的数据集。算法示意图如下:  我们选择 2009 KDD chanllenge 的削数据集来对这些降维技术在降维率、准确度损失率以及计算速度方面进行比较。当然,最后的准确度与损失率也与选择的数据分析模型有关。因此,最后的降维率与准确度的比较是在三种模型中进行,这三种模型分别是:决策树,神经网络与朴素贝叶斯。 通过运行优化循环,最佳循环终止意味着低纬度与高准确率取决于七大降维方法与最佳分类模型。最后的最佳模型的性能通过采用所有特征进行训练模型的基准准确度与 ROC 曲线下的面积来进行比较。下面是对所有比较结果的对比。 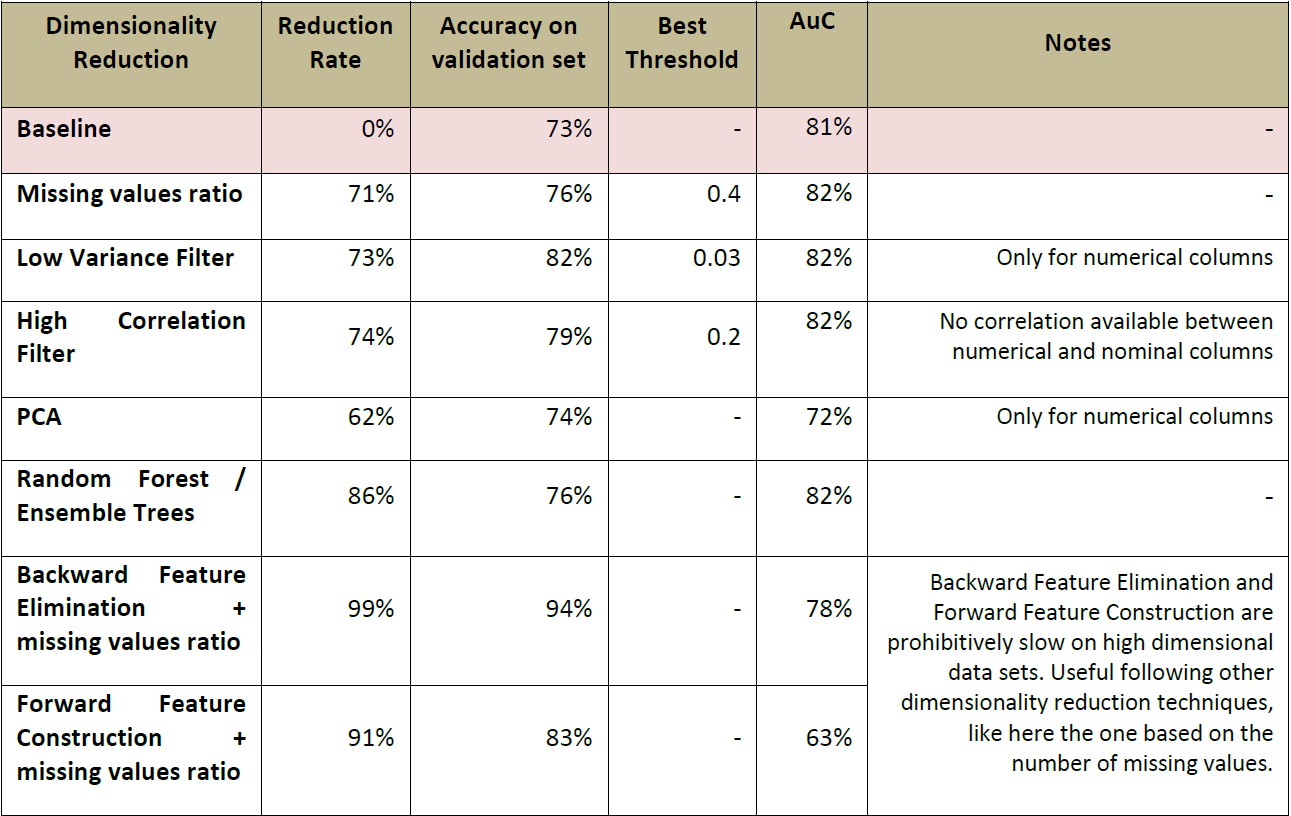 从上表中的对比可知,数据降维算法不仅仅是能够提高算法执行的速度,同时也能过提高分析模型的性能。 在对数据集采用:缺失值降维、低方差滤波,高相关滤波或者随机森林降维时,表中的 AoC 在测试数据集上有小幅度的增长。  确实在大数据时代,数据越多越好似乎已经成为公理。我们再次解释了当数据数据集宝航过多的数据噪声时,算法的性能会导致算法的性能达不到预期。移除信息量较少甚至无效信息唯独可能会帮助我们构建更具扩展性、通用性的数据模型。该数据模型在新数据集上的表现可能会更好。 最近,我们咨询了 LinkedIn 的一个数据分析小组在数据分析中最为常用的数据降维方法,除了本博客中提到的其中,还包括:随机投影(Random Projections)、非负矩阵分解(N0n-negative Matrix Factorization),自动编码(Auto-encoders),卡方检测与信息增益(Chi-square and information gain), 多维标定(Multidimensional Scaling), 相关性分析(Coorespondence Analysis), 因子分析(Factor Analysis)、聚类(Clustering)以及贝叶斯模型(Bayesian Models)。 |
 提升卡
提升卡 置顶卡
置顶卡 沉默卡
沉默卡 变色卡
变色卡 抢沙发
抢沙发 千斤顶
千斤顶 显身卡
显身卡





 京公网安备 11010802022788号
京公网安备 11010802022788号







