



 雷达卡
雷达卡
















In the blog “From Autonomous to Smart: Importance of Artificial Intelligence,” we laid out the artificial intelligence (AI) challenges in creating “smart” edge devices:
- Artificial Intelligence Challenge #1: How do the Artificial Intelligence algorithms handle the unexpected, such as flash flooding, terrorist attacks, earthquakes, tornadoes, police car chases, emergency vehicles, blown tires, a child chasing a ball into the street, etc.?
- Artificial Intelligence Challenge #2: The more complex the problem state, the more data storage (to retain known state history) and CPU processing power (to find the optimal or best solution) is required in the edge devices in order to create “smart.”
We also talked about how Moore’s Law isn’t going to bail us out of these challenges; that the growth of Internet of Things (IOT) data and the complexity of the problems that we are trying to address at the edge (think “smart” cars) is growing much faster than Moore’s Law can accommodate.
So we are going to use this blog to deep dive into the category of artificial intelligence called reinforcement learning. We are going to see how reinforcement learning might help us to address these challenges; to work smarter at the edge when brute force technology advances will not suffice.
Why Not Brute Force
With the rapid increases in computing power, it’s easy to get seduced into thinking that raw computing power can solve problems like smart edge devices (e.g., cars, trains, airplanes, wind turbines, jet engines, medical devices). But to understand the scope of the challenge, consider the following:
- Checkers has 500 billion billion (that’s right, billion twice) possible board moves. That’s 500,000,000,000,000,000,000 possible moves (that’s 20 zeros).
- The number of possible moves in a game of chess is a minimum of 10120 moves (that’s 120 zeros).
Look at the dramatic increase in the number of possible moves between checkers and chess even though the board layout is exactly the same. The only difference between checkers and chess is the types of moves that pieces can make. A checker has only two moves: forward diagonally and jump competitor’s pieces diagonally (once a checker is “kinged”, then it can move diagonally both forward and backwards). In chess, the complexity of the chess piece only increases slightly (rooks can move forward and sideways a variable number of spaces, bishops can move diagonally a variable number of spaces, etc.), but the complexity of the potential solutions exploded (from 20 zeros to 120 zeros). And both checkers and chess operate in a deterministic environment, where all possible moves are known ahead of time and there are no surprises (unless your dog decides that he wants to play at the same time).
Now think about the number and breadth of “moves” or variables that need to be considered when driving a car in a nondeterministic (random) environment: weather (precipitation, snow, ice, black ice, wind), time of day (day time, twilight, night time, sun rise, sun set), road conditions (pot holes, bumpy, slick), traffic conditions (number of vehicles, types of vehicles, different speeds, different destinations). One can quickly see that the number of possible moves is staggering. We need a better answer than brute force.
Reinforcement Learning to the Rescue
Reinforcement Learning is for situations where you don’t have data sets with explicit known outcomes, but you do have a way to telling whether you are getting closer to your goal (reward function). Reinforcement learning learns through trial-and-error how to map situations to actions so as to maximize rewards. Actions may affect immediate rewards but actions may also affect subsequent or longer-term rewards, so the full extent of rewards must be considered when evaluating the reinforcement learning effectiveness (i.e., balancing short-term rewards like optimizing fuel consumption while driving a car balanced against the long-term rewards of getting to your destination on time and safely).
Reinforcement learning is used to address two general problems:
- Prediction: How much reward can be expected for every combination of possible future states (e.g., how much can we collect from delinquent accounts based on the following steps?)
- Control: By moving through all possible combinations of the environment (interacting with the environment or state space), find a combination of actions that maximizes reward and allows for optimal control (e.g., steering an autonomous vehicle, winning a game of chess).
The children’s game of “Hotter or Colder” is a good illustration of reinforcement learning; rather than getting a specific “right or wrong” answer with each data action, you’ll get a delayed reaction and only a hint of whether you’re heading in the right direction (hotter or colder).
Reinforcement Learning and Video Games
Reinforcement learning needs lots and lots of data from which to learn and very powerful compute to support its “trial and error” learning approach. Because it can take a considerable amount of time to gather enough data across enough scenarios in the real world, many of the advances in reinforcement learning are occurring from playing against video games.
One such example is the MarI/O program (‘MarI/O AI Program Learns To Play Super Mario World’). MarI/O is an artificial intelligence application that has learned how to play the video game “Super Mario World” (see Figure 1).
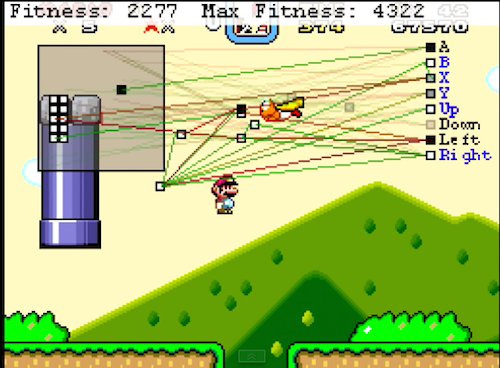
[size=-1]Figure 1: MarI/O Playing “Super Mario World” Video Game
Some key points to learn from MarI/O:
- MarI/O uses random steps to start its exploration process and to re-start whenever it stalls.
- MarI/O takes inputs by sensing white boxes (safe landing areas) and black boxes (obstacles).
- Rewards (Fitness points in the case of Mario Brothers) and punishment (death) guide the learning process (try to maximize rewards while minimizing or eliminating punishments)
- Sometimes losing (failing) is the only way to learn.
Figure 2 shows the progress that MarI/O made in learning the environment in order to maximize its fitness points and survive.
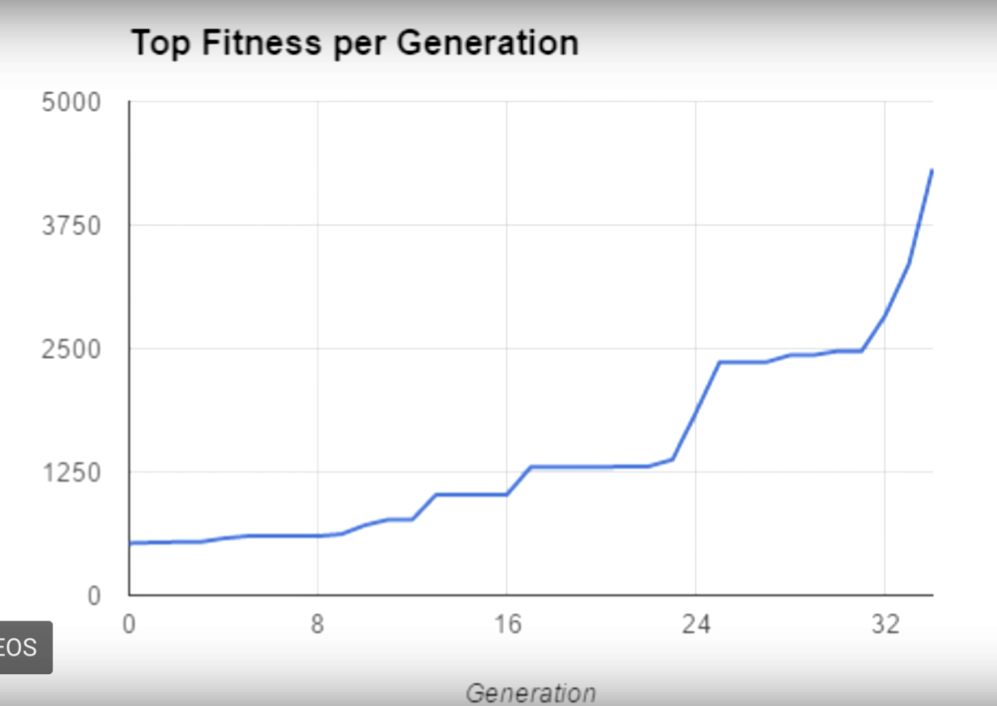
[size=-1]Figure 2: MarI/O Learning Curve
But “Mario Super World” is a deterministic or known environment where the gaming patterns repeat themselves. For example, the chart in Figure 2 doesn’t show any regressions in performance, where the AI model hit a dead end and had to retreat and re-set itself. Retreating is a common behavior that the more advanced AI models must support.
And the game playing strategy in this model is very simple – just survive. There is no strategy to maximize the number of coins captured, which is an equally important part of playing Super Mario World (or at least if you want bragging rights with your friends).
So while the exercise is definitely educational, it’s not terribly application for our smart car example.
Grand Theft Auto to the Rescue!
Applying reinforcement learning to teach a car to drive requires an unbelievably huge quantity of data. Having a bunch of autonomous car tooling around the ‘hood just can’t generate enough data fast enough to optimize the models necessary to safely drive a vehicle. However, autonomous car companies have discovered a much richer training environment – Grand Theft Auto!

The virtual environment within the video game Grand Theft Auto is so realistic that it is being used to generate data that’s nearly as good as that generated by using real-world imagery. The most current version of Grand Theft Auto has 262 types of vehicles, more than 1,000 different unpredictable pedestrians and animals, 14 weather conditions and countless bridges, traffic signals, tunnels and intersections. It’s nearly impossible for an autonomous car manufacturer to operate enough vehicles in enough different situations to generate the amount of data that can be virtually gathered by playing against Grand Theft Auto.
Reinforcement Learning Summary
Ultimately, reinforcement learning model development is going to need to wrestle with real (not virtual) random obstacles that pop up in the normal driving of a vehicle. Grand Theft Auto might be great for teaching vehicles how to operate in an environment with hoodlums, robberies, heists and gratuitous car chases, but more real-world experience is going to be needed in order for autonomous cars to learn to handle the random, life-endangering threats, such as a child chasing a ball into the street, a new pothole caused by some (undocumented) construction or random debris falling off of truck beds.
One recent technology development that might be the key to solving “impossible” problems like autonomous driving is quantum computing. A future blog will explore how combining artificial intelligence with quantum computing might just help us solve the “impossible” problems.
 提升卡
提升卡 置顶卡
置顶卡 沉默卡
沉默卡 变色卡
变色卡 抢沙发
抢沙发 千斤顶
千斤顶 显身卡
显身卡






 京公网安备 11010802022788号
京公网安备 11010802022788号







