




 雷达卡
雷达卡





从零开始学Python【26】--Logistic回归(理论部分)
从零开始学Python【25】--岭回归及LASSO回归(实战部分)
从零开始学Python【24】--岭回归及LASSO回归(理论部分)
前言基于上一期的理论知识,我们本期跟大家分享一下如何通过Python和R语言完成Logistic回归分类器的构建。大家都知道,Logistic模型主要是用来解决二元分类问题,通过构建分类器,计算每一个样本为目标分类的概率,一般而言,我们会将概率值0.5作为分类的阈值,即概率值P大于等于0.5时判别为目标分类,否则为另一种分类。
本次分享的数据是基于用户信息(年龄、性别和年收入)来判断其是否发生购买,数据来源于GitHub(文末有数据链接可供下载)。接下来,让我们看看Logistic模型是如何完成二分类问题的落地。本次分享会涉及模型的构建、测试集的预测及模型的验证三个方面。
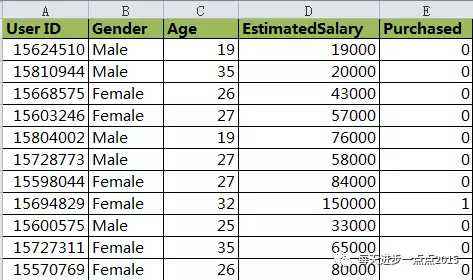
数据查阅# ===== Python3 =====# 导入第三方包import pandas as pdimport numpy as npimport statsmodels.formula.api as smffrom sklearn.cross_validation import train_test_splitfrom sklearn import metricsfrom ggplot import *# 读取数据集purchase = pd.read_csv(r'E:JupyterMLLogistic-Regression-masterSocial_Network_Ads.csv')# 查看数据类型purchase.dtypes# 查看各变量的缺失情况purchase.isnull().sum()
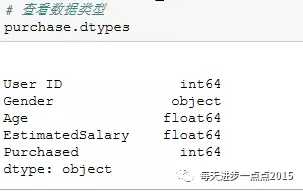
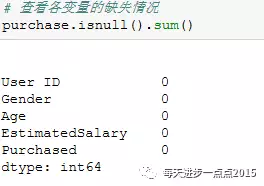
从上图结果可知,除Gender变量,其余变量均为数值型变量,那么待会再构建入模变量时,需要对Gender变量创建哑变量;一般在做数据探索时,需要检查各变量是否存在缺失的情况(如果缺失需要借助于删除法、替换法、插值法等完成缺失值的处理,具体可以参考文章【如何使用R语言解决可恶的脏数据】),很显然上面的结果并没有显示数据中含有缺失值。
变量处理# 对Gender变量作哑变量处理dummy = pd.get_dummies(purchase.Gender)# 为防止多重共线性,将哑变量中的Female删除dummy_drop = dummy.drop('Female', axis = 1)# 剔除用户ID和Gender变量purchase = purchase.drop(['User ID','Gender'], axis = 1)# 如果调用Logit类,需要给原数据集添加截距项purchase['Intercept'] = 1# 哑变量和原数据集合并model_data = pd.concat([dummy_drop,purchase], axis = 1)model_data
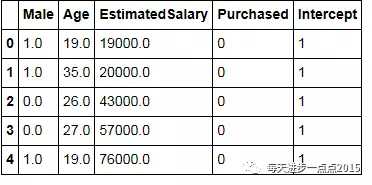
上面所做的处理无非是构建哑变量,然后从哑变量中再剔除一个水平变量(这个非常重要,为了防止多重共线性);同时还要剔除没有意义的变量User ID和不再使用的Gender变量(因为已经拆分为哑变量了)。OK,整理之后的数据集就如上图所示,接下来我们要基于这个数据集进行Logistic模型的创建。
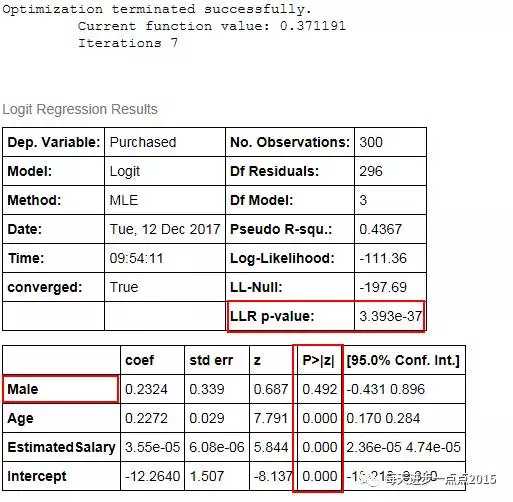
经过7次迭代后,模型系数的计算实现收敛,完成了Logistic分类器的创建。从上图的结果看,除Male这个哑变量不显著(说明性别这个变量并不能构成用户是否购买的因素)外,其余的偏回归系数均为显著。下面,我们不妨将Male变量剔除,再做一次Logistic模型。
# 重新构造分类器logistic2 = smf.logit('Purchased~Age+EstimatedSalary', data = pd.concat([y_train,X_train], axis = 1)).fit()logistic2.summary()print(logistic.aic)print(logistic2.aic)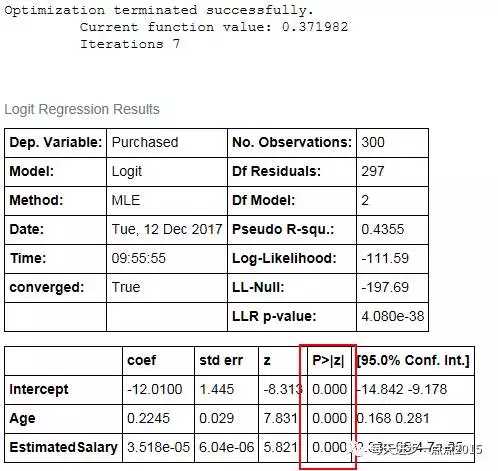
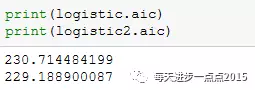
很明显,通过变量的剔除,在保证了所有变量显著的情况下,也降低了模型的AIC,说明,Male哑变量的删除是合理的。
# 优势比np.exp(logistic2.params)
接下来,再来看看模型的系数解释(优势比),在其他变量不变的情况下,用户年龄每增加一个单位(岁),用户购买的概率是不够买概率的1.25倍;用户的年收入每增加一个单位(元),用户购买的概率与不够买概率几乎相等(因为这里只是计算年收入增加1元的概率比,如果对收入变量压缩10000倍,那这个概率比肯定就会上升了,因为此时收入上升一个单位就是一万元了)。
模型预测与验证# 根据分类器,在测试集上预测概率prob = logistic2.predict(exog = X_test.drop('Male', axis = 1))# 根据概率值,将观测进行分类,不妨以0.5作为阈值pred = np.where(prob >= 0.5, 1, 0)# 根据预测值和实际值构建混淆矩阵cm = metrics.confusion_matrix(y_test, pred, labels=[0,1])cm# 计算模型的准确率accuracy = cm.diagonal().sum()/cm.sum()accuracy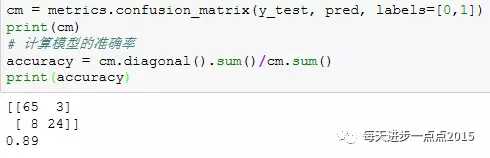
应用分类器对测试数据集进行预测,这里将概率值设为0.5,如果概率大于等于0.5则判用户会购买,否则不会发生购买。通过这个概率值的设定,我们发现模型的准确率还是非常高的(混淆矩阵对角线代表预测正确的数量)。可是单看混淆矩阵还不够,因为当数据不平衡时,计算的准确率也同样会高,并不代表模型就会好,所以我们进一步的借助于ROC曲线下的面积来衡量模型时候合理。
# 绘制ROC曲线fpr, tpr, _ = metrics.roc_curve(y_test, pred)df = pd.DataFrame(dict(fpr=fpr, tpr=tpr))ggplot(df, aes(x='fpr', y='tpr')) + geom_area(alpha=0.5, fill = 'steelblue') + geom_line() + geom_abline(linetype='dashed',color = 'red') + labs(x = '1-specificity', y = 'Sensitivity',title = 'ROC Curve AUC=%.3f' % metrics.auc(fpr,tpr))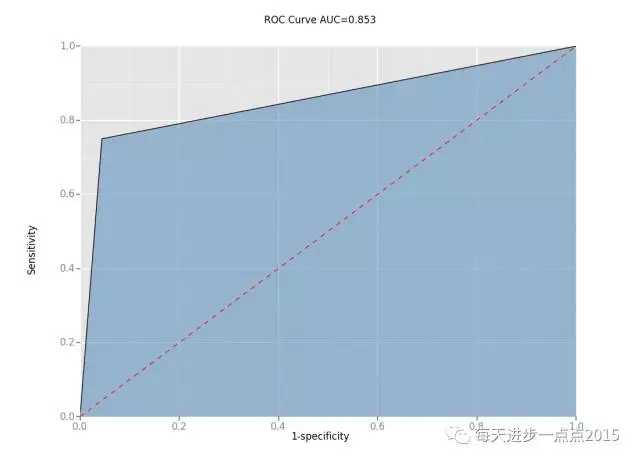
是不是很激动,对于熟悉R语言的你,Python中也有ggplot2的绘图语法!从上面的ROC曲线结果可知,AUC的值超过了0.85,这进一步说明模型的预测效果是非常不错的(一般AUC>0.8就比较好了)。
到此,关于使用Python构建Logistic分类器的实战我们就介绍到这里,接下来将使用R语言重新复现一遍,希望对R语言熟悉的朋友有一点的帮助。如下是R语言的复现脚本:
# 加载第三方包library(pROC)library(ggplot2)# 读取数据purchase <- read.csv(file = file.choose())purchase$Purchased = factor(purchase$Purchased)# 数据类型str(purchase)# 各变量缺失情况sapply(purchase, function(x) sum(is.na(x)))# 数据集拆分为训练集和测试集set.seed(0)idx = sample(1:nrow(purchase), size = 0.75*nrow(purchase))train = purchase[idx,]test = purchase[-idx,]# 构建Logistic模型logit = glm(Purchased ~ ., data = train[,-1], family = binomial(link = "logit"))summary(logit)# 删除性别这个变量train2 = purchase[idx,-c(1,2)]test2 = purchase[-idx,-c(1,2)]# 重新构建Logistic模型logit2 = glm(Purchased ~ ., data = train2, family = binomial(link = "logit"))summary(logit2)# 预测prob = predict(logit2, newdata = test2)pred = factor(ifelse(prob >= 0.5, 1, 0), levels = c(0, 1), ordered = TRUE)# 混淆矩阵Freq = table(test$Purchased, pred)# 准确率sum(diag(Freq))/sum(Freq)# 绘制ROC曲线ROC = roc(factor(test2$Purchased, levels=c(0,1), ordered = TRUE), pred)df = data.frame(x = 1-ROC$specificities, y = ROC$sensitivities)ggplot(df, aes(x = x, y = y)) + geom_area(alpha=0.5, fill = 'steelblue') + geom_line() + geom_abline(linetype='dashed',color = 'red') + labs(x = '1-specificity', y = 'Sensitivity', title = paste0('ROC Curve AUC=', round(ROC$auc,3))) + theme(plot.title = element_text(hjust = 0.5, face = 'bold'))结语
OK,关于使用Python和R语言完成Logistic回归的实战我们就分享到这里,如果你有任何问题,欢迎在公众号的留言区域表达你的疑问。同时,也欢迎各位朋友继续转发与分享文中的内容,让更多的人学习和进步。
关注“每天进步一点点2015”,与小编同进步!
数据链接:
链接: https://pan.baidu.com/s/1eSo3Y2Q 密码: cd7f
 提升卡
提升卡 置顶卡
置顶卡 沉默卡
沉默卡 变色卡
变色卡 抢沙发
抢沙发 千斤顶
千斤顶 显身卡
显身卡


 京公网安备 11010802022788号
京公网安备 11010802022788号







