


 雷达卡
雷达卡




说起回归分析,尤其是线性回归,想必大家一定已经有所了解。
无论是研究影响关系或是预测数据走势,回归分析都是十分可靠的方法,也因而受到了研究人员的青睐。
但,回归分析同样也很容易被错误地使用。回归分析有很多条件限制,初学者往往在没有意识到这些条件限制之前,就已经得出了自认为正确的结果,并以此作为最终的结论。
这样误用分析方法的例子在现实研究中,并不少见。本文,就来向大家展示几个关于回归分析的常见误用场景,看看你有没有犯过这些“错误”?
场景一:
红星大学的李华收集了100份问卷数据,并选择线性回归分析来分析大学生的垃圾分类行为及其影响因素,其中自变量为影响因素,因变量Y为‘您是否特意按照垃圾分类标识进行分类?’。

问卷题项
纠正: 线性回归中,因变量应为定量数据
一个老生常谈的问题。在使用回归之前,首先应该确定Y是否为定量数据,例如:
- 某公司的销售额
- 问卷满意度得分
- 考试成绩
- 身高
- …
由于案例中Y为分类数据,并且只分为两项,因而应使用二元Logit回归分析。
如果Y是性别这类——定类数据,可以使用logistic回归;如果Y是频次这类——计数资料,可选择Poisson回归;如果Y是生存资料,可选择Cox回归。
使用路径:SPSSAU→医学研究
同时如果是问卷数据,想使用回归分析,那么在问卷设计阶段就要确保设计了因变量对应的问题,以免正式分析时缺少因变量,造成无法分析的尴尬局面。
场景二:
XX外国语大学的韩梅梅,想要研究本校学生英语四级成绩的影响因素,调查收集了200份数据。其中影响因素包括性别、专业、高考成绩、父母教育水平等。由于Y为定量数据因此选择线性回归分析方法。她将性别、专业、高考成绩、父母教育水平作为自变量,四级成绩作为因变量放入回归方程分析。
纠正: 自变量中如果有需要分析的定类数据,需进行哑变量的设置
由于案例中性别、专业均为定类数据,并且是作为核心研究变量纳入模型,因而分析时应先进行哑变量设置再分析。
原则上回归分析对自变量的数据类型没有要求,可以是定量数据也可以是定类数据。自变量中如果有定类数据是作为控制变量纳入模型,可直接放入模型;如果是定类数据且需要分析,此时则需要进行虚拟变量(也称哑变量)设置。
场景三:
XX师范大学的李雷,收集了一份关于学习动机的影响因素研究数据。在没有进行任何预处理的情况下,就直接进行回归分析。
纠正: 分析前首先应当对数据进行预处理,首先可通过散点图观察变量间的关系情况,如存在异常值结合实际情况考虑是否需要剔除。
回归分析对异常值较为敏感,异常值的存在可能会使回归模型产生偏差,影响分析结果。首先可通过散点图等观察数据中是否存在异常值。
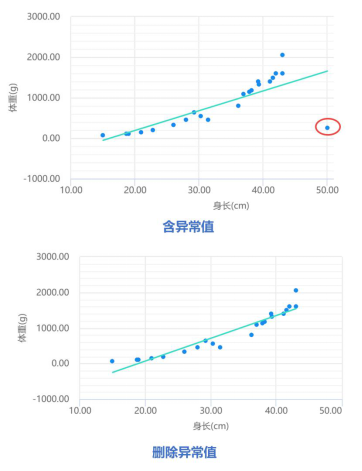
如上图所示,异常值影响了分析结果。将其删除后重新分析,此时拟合线与之前相比有明显的移动。说明异常值确实对模型产生较大影响。
除了上述鉴别异常值的方法,还可以通过箱线图、描述分析、正态图等检验异常值。
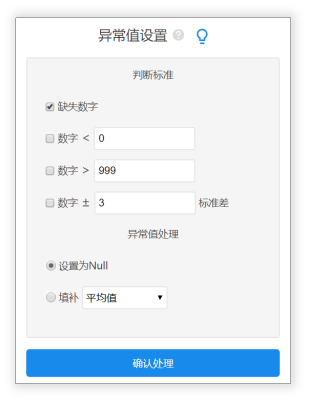
SPSSAU提供四种异常值的判定标准分别是:缺失数字、小于设定标准的数字、大于设定标准的数字、大于3个标准差。用户可以在系统中直接操作删除异常值。
上述问题的出现主要是由于对分析方法的使用了解的不够清楚,分析前应该多加注意。当解决掉这些“初级”问题后,不要掉以轻心,因为这并不意味着你可以得到一份有效的回归分析结果。
问题四:共线性问题
共线性问题是指一个解释变量(X)的变化引起另一个解释变量(X)地变化。严重的共线性问题会导致数据研究出来严重偏差甚至完全相反的结论,因而需要解决此问题。
问题五:残差分析
残差分析在回归分析中,是很重要的部分。残差分析主要包括分析残差的正态性、独立性以及方差齐性。
- 残差正态性:在分析时可保存残差项,然后使用“正态图”直观检测残差正态性情况,如果残差直观上满足正态性,说明模型构建较好,反之说明模型构建较差。如果残差正态性非常糟糕,建议重新构建模型,比如对Y取对数后再次构建模型等。
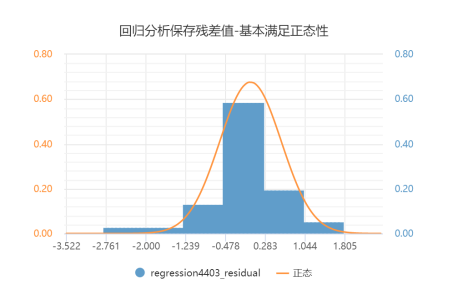
正态图
-
自相关性:如果D-W值在2附近(1.7~2.3之间),则说明没有自相关性,模型构建良好,反之若D-W值明显偏离2,则说明具有自相关性,模型构建较差。自相关问题产生时建议对因变量Y数据进行查看。
-
异方差性:可将保存的残差项,分别与模型的自变量X或者因变量Y,作散点图,查看散点是否有明显的规律性,比如自变量X值越大,残差项越大/越小,这时此说明有规律性,模型具有异方差性,模型构建较差。如果有明显的异方差性,建议重新构建模型,比如对Y取对数后再次构建模型等。
散点图
问题六:样本量
为了保证模型的稳定,入选的样本不能太少,一般情况下,样本量应该至少是自变量的20倍以上才较为稳定。
以上都是一些在日常分析中容易忽略的问题,虽然都是一些细小的步骤,但只有通过这些处理判断,得到的结果才更加真实可信。


 京公网安备 11010802022788号
京公网安备 11010802022788号







