


 雷达卡
雷达卡



以上关于树模型相关的内容,大部分都是用python来实现相关逻辑。有童鞋说想进一步了解下树模型相关内容,并且提到是否有跟SAS相关的知识来实现树模型内容,今天就跟介绍最经典的随机森林的算法在欺诈场景中的实现,并且结合SAS的实操进行演绎。
随机森林算法是由大量决策树构成的,同时这些决策树相互之间是没有关联的。随机森林在生成众多决策树的过程中,是通过对建模数据集的样本观测和特征变量分别进行随机抽样,每次抽样结果均为一棵树,且每棵树都会生成符合自身属性的规则和评分,而森林最终集成所有决策树的规则和评分,实现随机森林算法的处理效果。
由于每棵决策树的特征变量是随机选取的,因此每棵树的训练结果对样本客户的评分规则是不同的,而随机森林是综合所有决策树的评分规则,从而对样本客户进行全局评分,避免了由于少量树训练效果较差导致的局部较大误差。因此,随机森林与单棵决策树相比较,其模型效果显得更为准确且可靠。随机森林算法具有训练过程简单、建模速度快、能够深入数据局部、预测能力较强、结果容易解释等优点,在金融领域中被广泛应用于信用评分、反欺诈等样本数据量较大、响应率较低的场景。现结合某场景案例,通过SAS编程语言实现随机森林算法,并介绍建立反欺诈模型的核心环节,同时对模型数据结果进行评估,介绍模型在实际业务中的应用。
1、建模宽表
某金融机构现有一分期产品的贷前反欺诈场景,拟通过开发反欺诈模型来预测申请进件用户的欺诈概率风险,从而辅助贷前信审环节前的风控业务决策。通过对存量用户的贷后数据表现分析,以及实际业务理解,欺诈用户定义逻辑为首期逾期天数达到30天及以上。建模样本数据宽表样例如表1所示,样本观测数量为6000,特征字段数量为62个,其中ID为客户进件号;Flag为目标变量(二分类标签,1为有欺诈,0为无欺诈);X1~X60为自变量,特征数据维度主要包括基本信息、人行征信、银联消费、多头借贷、设备信息等(X变量的部分样例如表2所示)。
表1 建模数据宽表

表2 自变量X特征标签

2、模型训练
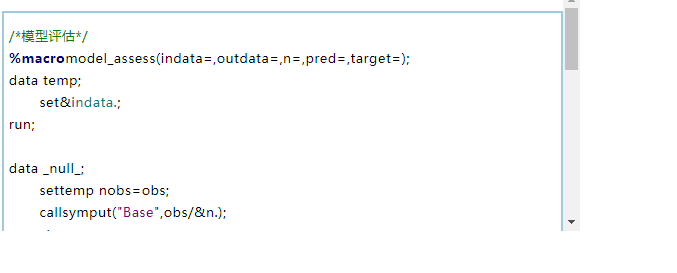
建模宽表data_model准备好后,即可进行模型训练环节,如下代码为采用SAS编写宏进行模型训练,具体重要步骤与参数解读在语句代码后已添加注释。

模型训练运行上述代码后,生成的模型评分规则以SAS文件score_rule&i.输出至指定路径&path.,同时输出样本评分结果数据集为data_score,部分样例如表3所示,字段Score为样本用户的欺诈评分。
表3 样本欺诈评分

3、模型评估
由于随机森林算法是综合了所有决策树训练后的评分规则,而每棵树是根据自身随机抽取的变量进行评分的,样本用户的最终评分是无法与所有变量直接形成函数关系,因而我们需要重点关注样本用户最终评分的准确性。
采用随机森林建立此模型的场景目的是为了识别欺诈用户,在业务决策中提高对欺诈用户的“识别率”,降低欺诈用户的“误报率”。若对表3评分Score进行从高到低排序等分N个区间,则“识别率”与“误报率”定义如下:
识别率 = 累计欺诈人数/ 全部欺诈人数
误报率 = 累计人数/ 累计欺诈人数
为了更直观介绍以上两个评估指标,现对评分结果数据Score降序等分30组,并分别计算出每组的预测欺诈概率(Score)的平均值、实际欺诈占比与数量,SAS实现功能代码如下:
模型评估运行上述代码后,生成的结果数据集data_index如下表(前5列所示),根据宽表生成的每组总人数、欺诈人数、预测欺诈比例(预测概率平均值)、实际欺诈比例,可以进一步计算出评估指标“识别率”与“误报率”:
表4 样本评估指标

根据上表数据可以得出,第1组的“识别率”为累计欺诈人数(32)/全部欺诈人数(160)≈20%,表示预测200个客户(占全部客户的3.33%)中,覆盖了全部真实欺诈客户的20%;第1组的“误报率”为累计人数(200)/累计欺诈人数(32)≈6,表示每预测6个客户可剔除1个真实欺诈客户。
同理可知,第2组的“识别率”=(32+21)/160≈33%,表示预测400个客户(占全部客户的6.67%)中,覆盖了全部真实欺诈客户的33%;“误报率”=(200+200)/(32+21)≈8,表示每预测8个客户可剔除1个真实欺诈客户。

图1 识别率与误报率曲线
如上图所示为识别率与误报率的关系趋势图,其中横坐标为误报率,纵坐标为识别率。随着误报率的增加,识别率也在增加,符合实际业务的变化趋势。图中曲线的拐点出现的越早,则模型的应用效果越好。图中的拐点大体出现在识别率为90%的位置,对应误报率为26(26:1),若以此规则在实际业务中进行决策应用,可以根据客户的预测欺诈评分,每处理26个用户即可剔除1个真实欺诈客户,进而可以预防90%欺诈事件的发生。
从结果数据可知,指标识别率与误报率在分析最终模型效果,以及反欺诈场景对的应用中,都有参考的意义。本次文章所提到的内容,建议大家结合在知识星球上提供的数据集进行练习,完整版本的代码也将在星球中后续发布:

另:

~原创文章
...
end

 京公网安备 11010802022788号
京公网安备 11010802022788号







