


 雷达卡
雷达卡



本文以APP设备部分维度数据为例,介绍下APP数据的常见业务类型,以及加工逻辑与分析方法。同时,结合Python编程语言代码实操,通过相关特征工程、模型训练等算法,评估特征字段的应用效果。
1、样本数据概况
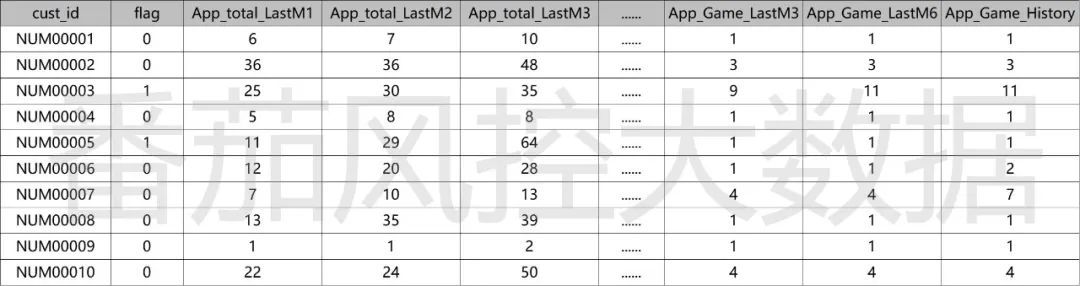
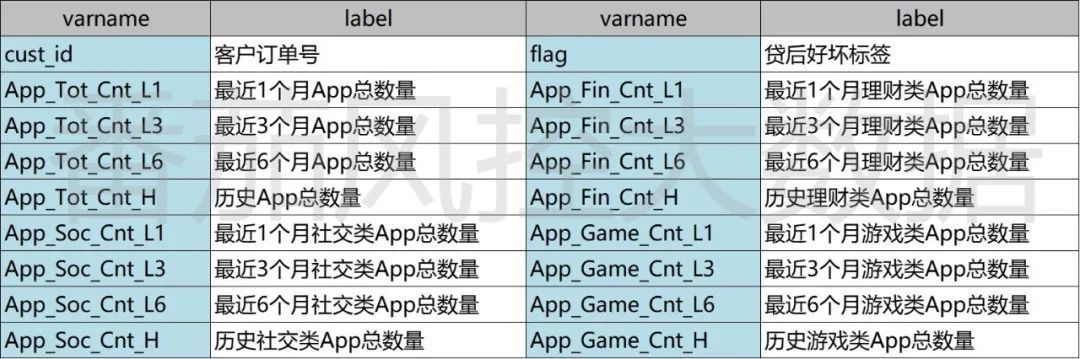
现有一份APP样本数据,示例如图1所示,样本量为20000条,特征量为18个。除了用户主键id、贷后标签flag之外,其余均为APP设备相关字段,包括社交类、理财类、游戏类等不同维度变量,具体特征字段表如图2所示。
 [backcolor=rgba(18, 18, 18, 0.5)]
[backcolor=rgba(18, 18, 18, 0.5)]
编辑切换为居中
添加图片注释,不超过 140 字(可选)
图1: 样本数据示例
 [backcolor=rgba(18, 18, 18, 0.5)]
[backcolor=rgba(18, 18, 18, 0.5)]
编辑切换为居中
添加图片注释,不超过 140 字(可选)
图2: 特征字典表
2、特征衍生分析
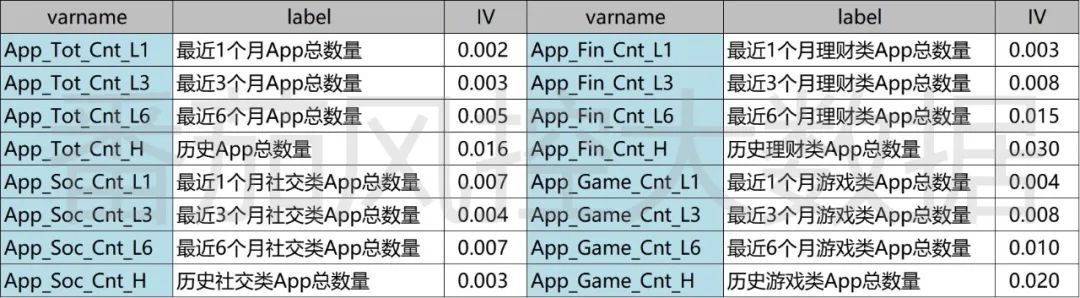
为了提升模型训练的拟合效果,特征字段的性能评估与变量筛选是一项重要环节,具体可通过变量的区分性、相关性、稳定性、解释性等多个维度进行考虑。现根据样本特征的分布情况,采用IV值评估字段的区分能力,实现代码与结果指标分别如图3、图4所示。
 [backcolor=rgba(18, 18, 18, 0.5)]
[backcolor=rgba(18, 18, 18, 0.5)]
编辑切换为居中
添加图片注释,不超过 140 字(可选)
图3: 特征变量分箱
 [backcolor=rgba(18, 18, 18, 0.5)]
[backcolor=rgba(18, 18, 18, 0.5)]
编辑切换为居中
添加图片注释,不超过 140 字(可选)
图4: 原始变量指标IV
从特征字段的IV值结果来看,样本所有字段的区分效果普遍表现较差。当然,若在样本数据不更换的情况下,为了有效完成数据建模任务,还需从中选择性能较好的字段放入模型拟合变量池。但是,从上表信息可知,如果以IV>=0.015作为筛选标准,区分度效果较好的字段仅有4个,分别为App_Tot_Cnt_H(历史App总数量)、App_Fin_Cnt_L6(最近6个月理财类App总数量)、App_Fin_Cnt_H(历史理财类App总数量)、App_Game_Cnt_H(历史游戏类App总数量)。
为了保证模型训练有更多的变量可选,基于样本原始特征字段,可以进行特征衍生加工,以扩大模型变量池范围,有效提升模型的拟合效果。结合图2样本所有字段的分布类型,具体衍生方法可以通过统计学维度进行新变量的加工,包括平均、占比、差分、差比等。现根据这几个常见方式,举例实现特征变量的衍生,部分代码如图5、图6所示。
 [backcolor=rgba(18, 18, 18, 0.5)]
[backcolor=rgba(18, 18, 18, 0.5)]
编辑切换为居中
添加图片注释,不超过 140 字(可选)
图5 : 特征衍生代码1
 [backcolor=rgba(18, 18, 18, 0.5)]
[backcolor=rgba(18, 18, 18, 0.5)]
编辑切换为居中
添加图片注释,不超过 140 字(可选)
图6 : 特征衍生代码2
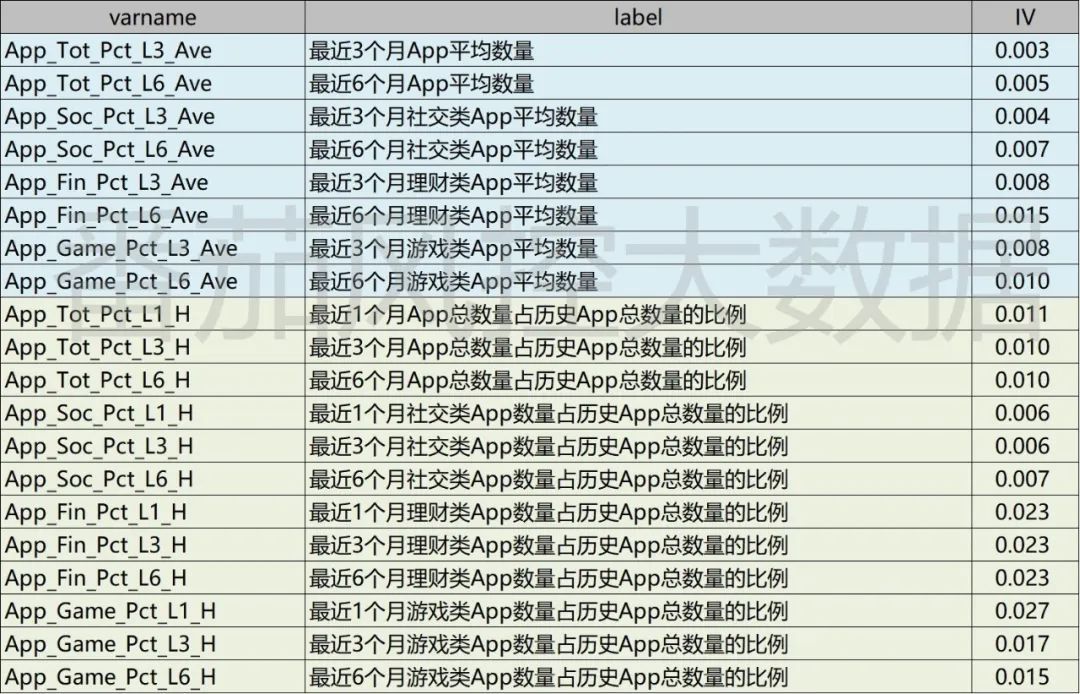
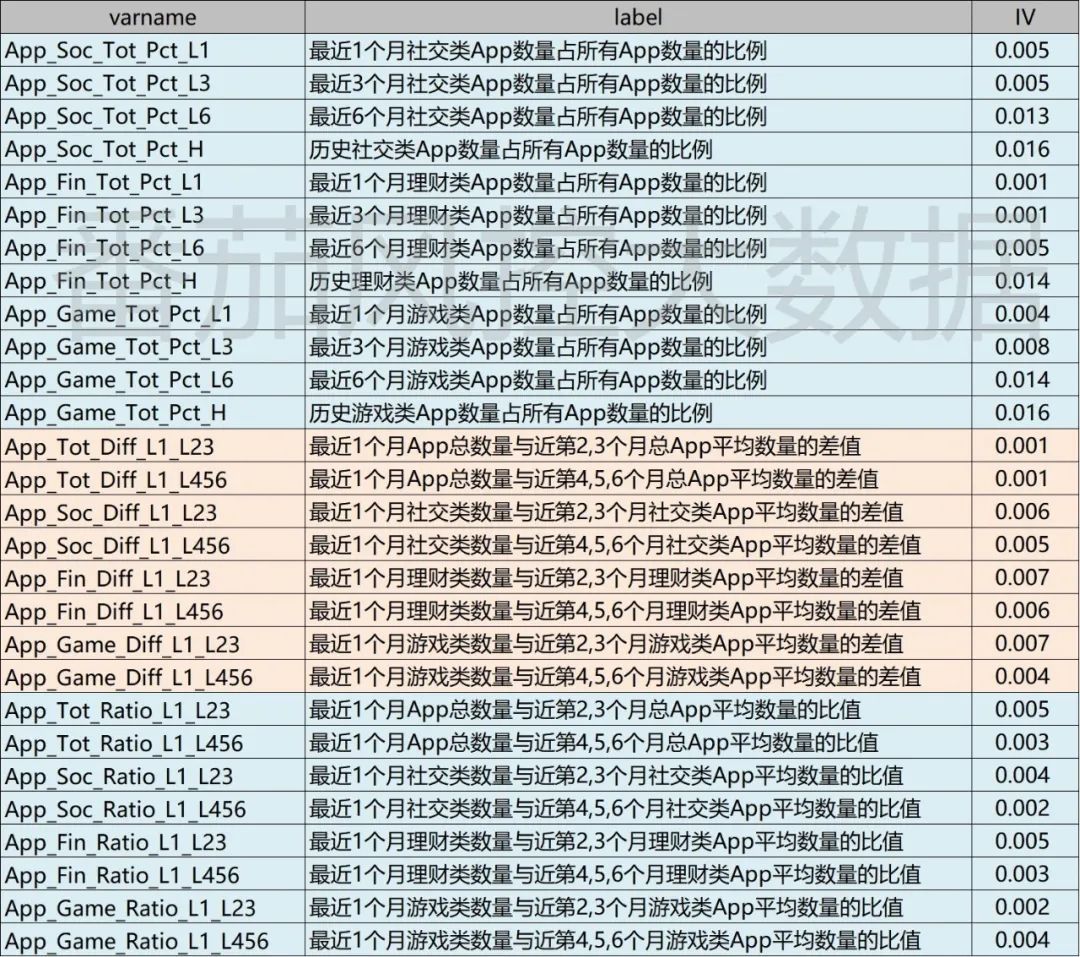
根据以上特征衍生方式,最终得到新变量字段的具体情况如图6所示,详细展示出变量的名称与标签。新加工的变量共个,按照图3代码可以同步得到各字段的IV信息值。当然,特征衍生方法还有很多,除了统计学维度,还可以通过特征聚类、主成分分析(PCA)等算法进一步补充。在实际业务中,往往从多个维度进行综合考虑与加工,但无论采用哪种方式,一定要结合业务场景和逻辑理解。
 [backcolor=rgba(18, 18, 18, 0.5)]
[backcolor=rgba(18, 18, 18, 0.5)]
编辑切换为居中
添加图片注释,不超过 140 字(可选)
图7: 特征衍生变量1
 [backcolor=rgba(18, 18, 18, 0.5)]
[backcolor=rgba(18, 18, 18, 0.5)]
编辑切换为居中
添加图片注释,不超过 140 字(可选)
图8: 特征衍生变量2
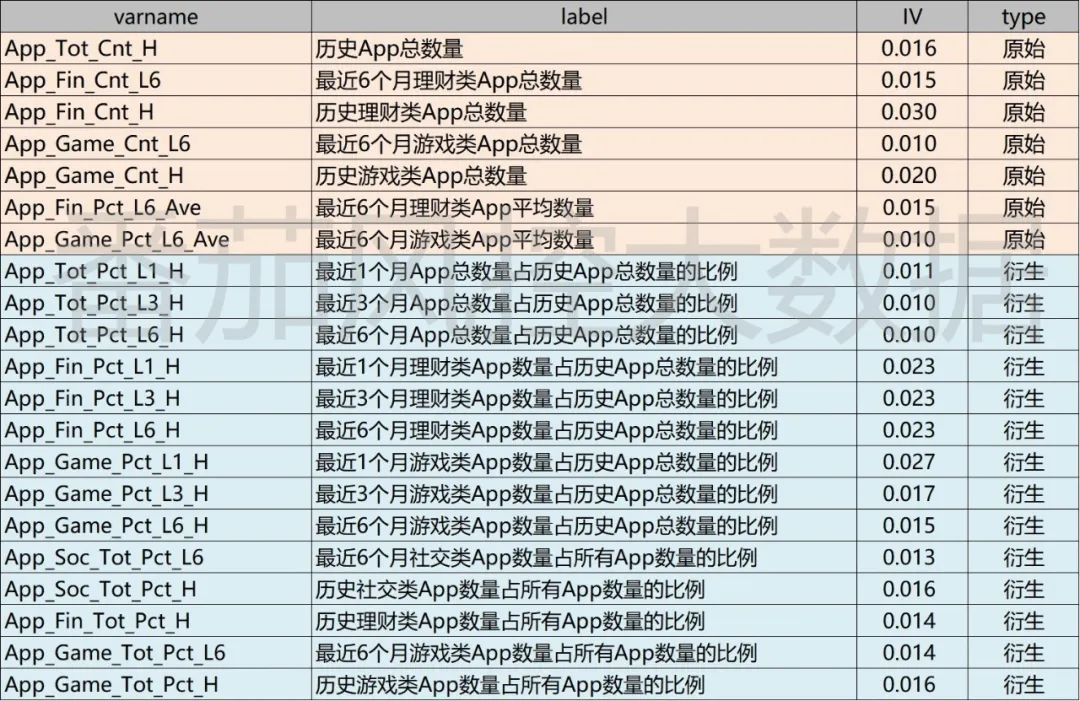
从以上新衍生特征的分布来看,我们在16个原始APP字段的基础上,经过衍生加工出48个新的字段。而且,各个字段的标签含义是非常贴近实际业务的,具有比较强的场景分析意义的。此外,从个字段的IV结果了解到,与原始特征(图4)相比,有部分新字段的IV表现尚可,可以放入模型拟合的变量范围。我们现以IV>=0.01作为选择标准,对衍生的新特征进行筛选,同时加上原始效果相对性较好的几个字段,得到如下图8所示的模型拟合变量池,共包含21个特征变量,其中原始字段有7个,衍生特征有14个。
 [backcolor=rgba(18, 18, 18, 0.5)]
[backcolor=rgba(18, 18, 18, 0.5)]
编辑切换为居中
添加图片注释,不超过 140 字(可选)
图9: 模型拟合变量池
3、模型训练评估
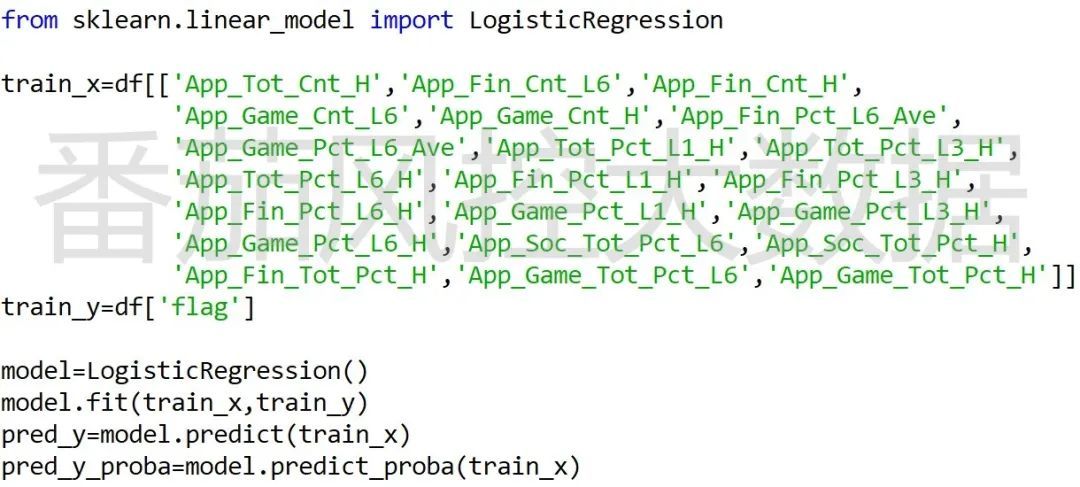
我们根据图8的APP特征变量,采用逻辑回归算法对模型进行训练,并输出相关模型性能指标,具体代码如图9所示。
 [backcolor=rgba(18, 18, 18, 0.5)]
[backcolor=rgba(18, 18, 18, 0.5)]
编辑切换为居中
添加图片注释,不超过 140 字(可选)
图10: 模型拟合训练
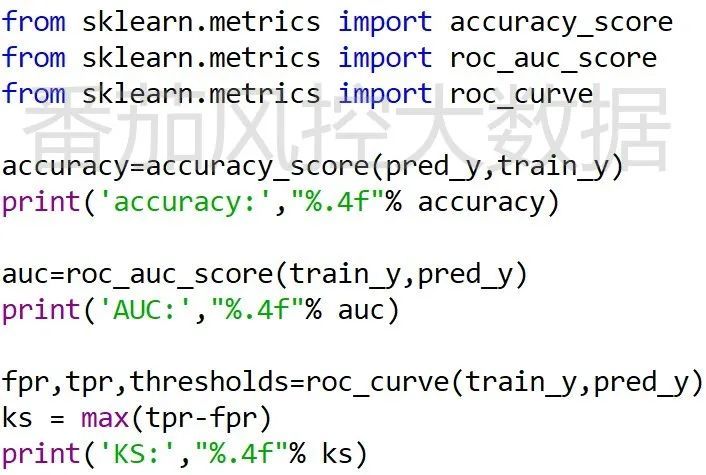
当APP模型训练成功后,可以输出相关模型指标,例如模型准确率、AUC、KS等,如图10所示。
 [backcolor=rgba(18, 18, 18, 0.5)]
[backcolor=rgba(18, 18, 18, 0.5)]
编辑切换为居中
添加图片注释,不超过 140 字(可选)
图11: 模型评估指标
本文关于APP设备数据特征衍生与应用的实操,详情请看:
 [backcolor=rgba(18, 18, 18, 0.5)]
[backcolor=rgba(18, 18, 18, 0.5)]
编辑切换为居中
添加图片注释,不超过 140 字(可选)
我们还给大家准备了相关的实操数据集跟代码,详情大家可以移步至知识星球查看相关的内容:
 [backcolor=rgba(18, 18, 18, 0.5)]
[backcolor=rgba(18, 18, 18, 0.5)]
编辑切换为居中
添加图片注释,不超过 140 字(可选)
~原创文章
...
end

 京公网安备 11010802022788号
京公网安备 11010802022788号







