


 雷达卡
雷达卡



Python基础(三)
第7章:文件与数据格式化
程序运行时的临时数据会随程序结束消失,而游戏角色属性、用户配置等数据需长期保存。Python 通过文件操作实现数据持久化。
7.1:文件概述:计算机中的数据存储单元
文件是计算机中以外部介质(如硬盘)为载体的数据集合,文本文档、图片、程序等均属于文件,操作系统以文件为单位管理数据。
7.1.1 文件标识:找到唯一文件的 “地址”
文件标识用于定位计算机中唯一的文件,由三部分组成:
- 文件路径:文件在存储介质中的位置(如
)f:\a.txt - 文件名主干:文件的核心名称(如
)a - 文件扩展名:标识文件类型(如
、.txt
).png

7.1.2 文件类型:按逻辑结构分类
文件按数据逻辑存储结构分为两类,物理层面均以二进制形式存储:
- 文本文件:存储文本字符数据,可通过记事本直接读写
- 二进制文件:需遵循特定序列化 / 反序列化规则,无法用普通文字处理程序直接打开(如图片、可执行程序)
7.1.3 Python 标准文件
sys 模块内置 3 个标准文件,对应输入输出设备:
stdin:标准输入文件,关联键盘等输入设备stdout:标准输出文件,关联显示器等输出设备stderr:标准错误文件,关联显示器等输出设备
import sys
sys.stdout.write('lucky cloud') # 直接输出到显示器
7.2:文件基础操作:打开、关闭与读写
文件的核心操作包括打开、关闭、读写,所有复杂操作均基于这些基本动作,关键在于控制打开模式和正确处理资源。
7.2.1 文件打开模式:控制操作权限
open() 函数用于打开文件,返回文件对象,核心参数
mode| 打开模式 | 名称 | 描述 |
|---|---|---|
| r/rb | 只读模式 | 只读打开文本 / 二进制文件,文件不存在则报错 |
| w/wb | 只写模式 | 只写打开文本 / 二进制文件,文件存在则覆盖,不存在则创建 |
| a/ab | 追加模式 | 只写打开文本 / 二进制文件,仅在文件末尾追加数据,不存在则创建 |
| r+/rb+ | 读取(更新)模式 | 可读可写打开文本 / 二进制文件,文件不存在则报错 |
| w+/wb+ | 写入(更新)模式 | 可读可写打开文本 / 二进制文件,文件存在则覆盖,不存在则创建 |
| a+/ab+ | 追加(更新)模式 | 可读可写打开文本 / 二进制文件,仅在末尾追加数据,不存在则创建 |
7.2.2 打开与关闭文件:资源管理关键
打开文件:使用
open(file, mode='r', buffering=None)file关闭文件:必须及时关闭以释放资源,避免文件句柄耗尽或数据丢失
两种关闭方式:
close()方法:文件对象的内置方法,需手动调用with 语句:自动关闭文件,推荐使用(无需手动调用 close())
file = open('f:\\a.txt', 'r')
file.close() # 手动关闭文件
with open('f:\\a.txt', 'r') as f:
# 文件操作代码
pass # 代码块结束后自动关闭文件
思考:为什么要及时关闭文件?
- 计算机中可打开的文件数量是有限的。
- 打开的文件占用系统资源。
- 若程序因异常关闭,可能产生数据丢失。
7.2.3 文件读取:三种核心方法
Python 提供 read()、readline()、readlines() 三种读取方法,适用于不同场景:
read(size):读取指定字节数- size 为读取字节数,默认读取全部数据
- 大文件不建议省略 size,避免耗尽内存
示例:读取 f 盘中 luckycloud.txt 的数据,代码示例如下:
方法一:
with open('f:\\luckycloud.txt', 'r', encoding='utf-8') as f: print(f.read(2)) # 读取前 2 个字节 print(f.read()) # 读取剩余全部数据方法二:
file = open('f:\\luckycloud.txt','r') connect = file.read(2) print(connect) print('-'*30) connect = file.read() print(connect) file.close()readline():逐行读取- 每次读取一行数据,换行符
会被保留\n - 适合大文件逐行处理,避免内存占用过高
with open('f:\\luckycloud.txt', 'r') as f: print(f.readline()) print(f.readline())运行结果:
actions speak louder than words luckycloud is here- 每次读取一行数据,换行符
readlines(hint):读取所有行并返回列表- 适合一次性读取小文件的所有内容
readlines()函数能一次性读取文件中的所有信息,如果读取成功,该方法将返回一个列表,其中每行对应列表的一个元素。语法格式如下:
readlines(hint=-1)
hint 参数控制读取的行数(以字节总数为限),默认值为读取所有行。
提示:单位是字节,用于限制要读取的行数。如果行中数据总大小超过 hint 字节,则readlines()不会继续读取更多的行。
返回一个列表,每行数据为列表中的一个元素,处理大文件时需谨慎使用。
在读取文件过程中若遇到编码错误,可以利用 chardet 库自动检测编码:
import chardet
# 首先以二进制模式读取文件,进行编码检测
with open('f:\\luckycloud.txt', 'rb') as f:
raw_data = f.read()
encoding = chardet.detect(raw_data)['encoding'] # 获取编码类型
# 根据检测到的编码格式读取文件
with open('f:\\luckycloud.txt', 'r', encoding=encoding, errors='ignore') as f:
print(f.readlines())
运行结果:
['actions speak louder than words\n', 'luckycloud is here\n']
总结:
read()(当参数缺失时)和readlines()方法都能一次性读取文件中的所有数据,但由于计算机内存有限,对于大文件,使用这两种方法一次读取可能会耗尽系统资源。因此,为了保证安全性,通常建议多次调用read(),每次读取指定大小的数据。
7.2.4 文件写入:两种主要方式
在写入文件时需要注意打开模式(w 覆盖、a 追加),核心方法包括write()和writelines():
write(data): 写入字符串数据- 接收字符串参数,返回写入的字节数量。
- 适用于单行数据的写入。
with open('f:\\luckycloud.txt', 'w', encoding='utf-8') as f: size = f.write('I am planning to write Python') # 写入字符串 print(size) # 输出写入的字节数:29writelines(lines): 写入一系列字符串- 接收字符串或字符串列表,没有返回值。
- 需要显式地添加换行符。
\n- 适用于多行数据的写入。
with open('f:\\luckycloud.txt', 'w', encoding='utf-8') as f: lines = ['Life is short\n', 'I use python'] # 字符串列表 f.writelines(lines) # 按行写入,需要手动添加换行符
写入方法对比:
write(): 只接收字符串参数,对于单行数据的写入更为直接。writelines(): 接收字符串列表,适合多行数据的高效写入,但需要手动处理换行符。
7.2.5 字符编码:文本文件的基础规则
在不同的编码方式下,字符与字节的对应关系各不相同。常见的编码及特点如下:
| 编码方式 | 支持语言 | 中文字节数 | 英文字节数 |
|---|---|---|---|
| ASCII | 英文 | 不支持 | 1 |
| UTF-8 | 多语言 | 3 | 1 |
| Unicode | 多语言 | 2 | 2 |
| GBK | 中 / 英文 | 2 | 1 |
7.2.6 文件定位读写:控制读写位置
read()方法读取了文件luckycloud.txt,结合代码与程序运行结果分析,可以看到read()第一次读取了两个字符,第二次从第三个字符开始读取剩余部分。
在一个打开的文件对象中进行的读写操作是连续的,系统总是从前一次读写的位置继续进行后续的操作。
每个文件对象都有一个称为“当前读写位置”的属性,该属性记录了当前的读写位置,默认为0,即从文件开头开始。
Python 提供了一些方法来获取和修改文件的当前位置,以实现定位读写:
tell(): 获取当前读写位置。with open('f:\\lucky.txt') as f: print(f.tell()) # 获取文件当前位置 print(f.read(5)) # 使用read()方法移动文件的当前位置 print(f.tell()) # 再次获取文件当前位置运行结果:
actio 5seek(offset, from): 移动读写位置。offset: 表示偏移量,即需要移动的字节数。from: 指定读写的位置,该参数可以取值0、1或2。
0:表示文件开头
1:表示使用当前读写位置
2:表示文件尾部
seek()方法调用成功后返回当前位置。
注意:文本文件仅支持 from=0,二进制文件支持所有参考点
# 二进制文件示例
with open('f:\\lucky.txt') as f:
f.tell() # 获取文件读写位置
sep = f.seek(5,0) # 相对文件首部移动5字节
print(sep) # 输出当前文件读写位置
运行结果:
5
7.3:文件与目录管理:os 模块的核心用法
对于用户来说,文件和目录以不同的形式展示,但对计算机而言,目录是文件属性信息的集合,本质上也是一种文件。
os 模块提供文件和目录的管理功能,包括删除文件、创建目录、获取文件列表等。
7.3.1 文件管理
删除文件:remove (文件路径),如果文件不存在则会出错
import os
os.remove('f:\\lucky.txt') # 删除指定文件
重命名文件:rename (原路径,新路径)
import os
os.rename('f:\\luckycloud.txt', 'f:\\cloud.txt') # 文件名修改
7.3.2 目录管理
获取当前目录:getcwd (),返回绝对路径
import os
print(os.getcwd()) # 示例输出:F:\PycharmProjects\pythonProject1\pycode\文件操作
创建目录:mkdir (目录路径),如果目录已存在则会出错
import os
os.mkdir('f:\\abc') # 在F盘创建abc目录
删除目录:rmdir (目录路径),如果目录非空则会出错
import os
os.rmdir('f:\\abc') # 删除abc目录
更改默认目录:chdir (目录路径),修改 Python 工作目录
import os
print('更改前默认路径:', os.getcwd())
os.chdir('f:\\') # 将默认目录改为F盘
print('更改后默认路径:', os.getcwd())
# 运行结果
更改前默认路径: F:\PycharmProjects\pythonProject1\pycode\文件操作
更改后默认路径: f:\\
获取目录文件列表:listdir (目录路径),返回文件名列表
import os
files = os.listdir('f:\\') # 获取F盘所有文件/目录名称
print(files) # 输出格式:['文件1.txt', '目录1', ...]
7.4:数据维度与数据格式化
数据维度和格式化是 Python 数据处理的核心基础,清晰的维度划分能让数据组织更加有序,规范的格式化则是数据存储、交换的关键。
7.4.1 基于维度的数据分类
维度本质上与数据相关联的参数数量有关,不同维度对应不同的数据组织形式,Python 中也有专属的数据结构支持。
- 一维数据:线性对等的基础数据
定义:具有对等关系的线性数据集合,仅需一个参数即可描述。
对应 Python 数据结构:列表(list)、元组(tuple)、集合(set)。
示例:
["成都", "杭州", "重庆"]
、
(10, 20, 30)
、
{"a", "b", "c"}
2)二维数据:表格化的结构化数据
定义:关联两个参数的数据集合,可理解为 “一维数据的集合”,呈现表格形态(行 × 列)。
对应 Python 数据结构:矩阵、二维数组、二维列表、二维元组。
示例:二维数据如下
姓名 语文 数学 英语 理综
刘婧 124 137 145 260
张昭华 116 143 139 263
邢昭林 120 130 148 255
鞠依依 115 145 131 240
黄丽萍 123 108 121 235
赵越 132 100 112 210
3) 多维数据:复杂关联的嵌套数据
定义:关联三个及以上参数,需通过层级关系展示复杂结构。
核心特征:用**键值对(key-value)**表达层级关联。
对应 Python 数据结构:字典(dict),网络传输中常用 JSON 格式。
示例:
"高三一班考试成绩": [
{
"姓名": "刘婧",
"语文": "124",
"数学": "137",
"英语": "145",
"理综": "260"
},
{
"姓名": "张华",
"语文": "116",
"数学": "143",
"英语": "139",
"理综": "263"
}
..........
]
7.4.2 一二维数据的存储与读写实战
数据通常存储在文件中,规范的存储格式是高效读写的前提,其中 CSV 是一二维数据的通用标准。
7.4.2.1 存储格式:约定分隔规则
- 一维数据存储
核心原则:用统一的特殊字符分隔数据,避免歧义。
常用分隔符:空格、逗号(,)、&(需确保 “分隔符不出现于数据中”)。
格式要求:采用英文半角符号,同一文件 / 文件组应使用统一的分隔符。
示例:
逗号分隔:
成都,杭州,重庆,武汉空格分隔:
10 20 30 40(2)二维数据存储:CSV 格式详解
二维数据可以视为多条一维数据的集合,当二维数据仅有一个元素时,这个二维数据即为一维数据。
CSV(Comma-Separated Values,逗号分隔值):一种国际通用的表格数据存储格式,
以纯文本形式存在。
格式规范:
每一行代表一条数据记录;
每条记录的字段用英文半角逗号分隔;
每条记录由一个或多个字段构成;
在Windows平台中,CSV文件的扩展名为.csv,可以通过Office Excel或记事本打开。
示例(学生成绩 CSV):
姓名,语文,数学,英语,理综
刘备,124,137,145,260
张飞,116,143,139,263
关羽,120,130,148,255
周瑜,115,145,131,240
诸葛亮,123,108,121,235
黄月英,132,100,112,210注意:
CSV广泛应用于不同架构下网络应用程序之间的表格信息交换中,它本身没有明确的格式标准,具体标准通常由传输双方协商决定。
7.4.2.2 数据读取:Python 解析 CSV 文件
在Python中读取CSV文件后,默认以二维列表形式存储,需处理编码问题以防乱码。
实战代码:读取CSV并转换为二维列表import chardet
# 自动检测文件编码(解决中文乱码问题)
with open('f:\\score.csv', 'rb') as f:
raw_data = f.read()
encoding = chardet.detect(raw_data)['encoding']
# 读取CSV文件
with open('f:\\score.csv', encoding=encoding, errors='ignore') as f:
lines = []
for line in f:
line = line.replace('\n', '') # 去除换行符
lines.append(line.split(',')) # 按逗号分割字段
print("读取结果(二维列表):")
print(lines)
运行结果:
[
['姓名', '语文', '数学', '英语', '理综'],
['刘备', '124', '137', '145', '260'],
['张飞', '116', '143', '139', '263'],
['关羽', '120', '130', '148', '255']
]7.4.2.3 数据写入:向CSV添加新字段
将一、二维数据写入文件中,即根据数据的组织形式,在文件中增加新的数据。
在已有的CSV文件中新增数据(如学生总分),需遵循CSV格式规则拼接字段。
实战代码:计算学生总分并写入新文件import chardet
# 自动检测编码
def get_file_encoding(file_path):
with open(file_path, 'rb') as f:
raw_data = f.read()
return chardet.detect(raw_data)['encoding']
# 读取原始成绩文件
input_path = 'f:\\score.csv'
output_path = 'f:\\count.csv'
encoding = get_file_encoding(input_path)
with open(input_path, encoding=encoding, errors='ignore') as f:
# 打开新文件用于写入(w+模式:读写+创建)
with open(output_path, 'w+', encoding='utf-8') as new_file:
lines = []
# 逐行读取并处理
for line in f:
line = line.replace('\n', '')
lines.append(line.split(','))
# 1. 添加表头字段“total”
lines[0].append('total')
# 2. 计算每个学生的总分(跳过表头)
for i in range(1, len(lines)):
total = 0
# 遍历当前学生的所有科目成绩
for item in lines[i]:
if item.isnumeric(): # 判断是否为数字(排除姓名字段)
total += int(item)
lines[i].append(str(total)) # 将总分转换为字符串添加到列表中
# 3. 写入新文件(按CSV格式拼接)
for line in lines:
new_file.write(','.join(line) + '\n')
print(line) # 打印验证结果
运行结果(使用Excel打开文件):
姓名
语文
数学
英语
理综
总计
刘备
124
137
145
260
666
张飞
116
143
139
263
661
关羽
120
130
148
255
653
周瑜
115
145
131
240
631
诸葛亮
123
108
121
235
587
黄月英
132
100
112
210
554
关键说明:
isnumeric():判断字符串是否仅为数字,用于区分 “姓名” 和 “成绩” 字段。
','.join(line)将列表元素使用逗号拼接为 CSV 格式的字符串。
输出文件编码设为
utf-87.4.3 多维数据格式化:JSON 核心应用
三维及以上多维数据,需采用键值对形式进行格式化,JSON 是网络传输中最常见的格式(相较于 XML、HTML 更简洁、节省流量)。
7.4.3.1 JSON 格式语法规则
数据存储在键值对中:
"key": "value"字段使用逗号分隔:
"姓名": "张飞", "语文": 116花括号
{}{"姓名": "张飞", "成绩": 561}方括号
[][{"姓名": "张飞"}, {"姓名": "关羽"}]7.4.3.2 JSON 与 Python 对象的转换
Python 的
jsondumps()loads()| 函数 | 功能描述 |
|---|---|
| dumps() | 对 Python 对象进行编码,将其转化为 JSON 字符串 |
| loads() | 将 JSON 字符串解析为 Python 对象 |
(1)类型对应关系
| Python 对象 | JSON 数据类型 |
|---|---|
| dict | object |
| list/tuple | array |
| str | string |
| int/float | number |
| True | true |
| False | false |
| None | null |
(2)实战:Python 对象转 JSON(dumps ())
import json
# 定义 Python 复杂对象(包含列表、字典、布尔值等)
py_obj = [
[1, 2, 3],
10, 3.14,
'tom',
{'java': 98, 'python': 100},
True, False, None
]
# 转换为 JSON 字符串
json_str = json.dumps(py_obj)
print(json_str)
运行结果:
[[1, 2, 3], 10, 3.14, "tom", {"java": 98, "python": 100}, true, false, null](3)实战:JSON 转 Python 对象(loads ())
import json
# 承接上面的 JSON 字符串
json_str = '[[1, 2, 3], 10, 3.14, "tom", {"java": 98, "python": 100}, true, false, null]'
print(json_str)
# 解析 JSON 字符串为 Python 对象
py_new = json.loads(json_str)
print(py_new)
# print("类型验证:", type(py_new)) # 输出:<class 'list'>
# print("字典元素访问:", py_new[5]['python']) # 输出:100
运行结果:
[[1, 2, 3], 10, 3.14, "tom", {"java": 98, "python": 100}, true, false, null]
[[1, 2, 3], 10, 3.14, 'tom', {'java': 98, 'python': 100}, True, False, None]
7.4.3.3 多维数据格式化示例
(1)JSON 格式(学生成绩多维数据)
{
"班级考试成绩": [
{
"姓名": "王小天",
"语文": 124,
"数学": 127,
"英语": 145,
"理综": 259
},
{
"姓名": "张大同",
"语文": 116,
"数学": 143,
"英语": 119,
"理综": 273
}
]
}
(2)对比 XML 格式(同一数据)
<班级考试成绩>
<学生>
<姓名>王小天</姓名>
<语文>124</语文>
<数学>127</数学>
<英语>145</英语>
<理综>259</理综>
</学生>
<学生>
<姓名>张大同</姓名>
<语文>116</语文>
<数学>143</数学>
<英语>119</英语>
<理综>273</理综>
</学生>
</班级考试成绩>
优势总结:
- JSON 更简洁,无需冗余标签;
- 键(如 “姓名”“语文”)仅定义一次,网络传输时流量消耗更少;
- 与 Python 字典天然兼容,解析效率更高。
第8章:面向对象
面向对象(OOP)是程序开发的核心思想之一,它模拟人类认识世界的思维方式,将复杂问题拆解为多个 “对象”,通过对象的交互解决问题。与传统的面向过程编程相比,OOP 更适合大型项目开发,具备 封装、继承、多态 三大特性。
8.1:面向对象 vs 面向过程:核心区别
8.1.1 两种编程范式的本质
| 编程方式 | 核心思想 | 关注点 | 优点 | 缺点 |
|---|---|---|---|---|
| 面向过程 | 按步骤解决难题 | 流程和逻辑顺序 | 代码结构清晰,容易理解 | 难以扩展,维护成本高 |
步骤、函数
简洁直接、执行效能高
代码复用性差、维护难度大
面向对象
抽象为对象间的互动
对象、属性、方法
易于扩展、便于维护、复用性强
入门门槛较高、执行效率略低
8.1.2 实例对比:制作一杯咖啡
????
面向过程方式(按步骤执行)
准备材料:水、咖啡粉
水壶加热水至沸腾→冷却至 90°C
滤杯放滤纸,预热杯子
咖啡粉放入滤纸
缓慢倒水冲泡
过滤完成,得到咖啡
????
面向对象方式(对象交互)
核心对象:咖啡机、水、咖啡粉、杯子
对象的属性与方法:
咖啡机:添加原料、煮制咖啡
水:设置加热温度
咖啡粉:设置研磨程度
杯子:接收咖啡液
灵活扩展:想喝茶时,只需将 “咖啡粉” 对象替换为 “茶叶”,无需修改其他流程
8.2:类与对象:OOP 的核心概念
8.2.1 类与对象的关系
类:具有相同属性和行为的事物的抽象集合(如 “汽车类”)
对象:类的具体实例(如 “我的特斯拉 Model 3”)
通俗理解:类是 “模板”,对象是 “根据模板创建的产品”
8.2.2 类的定义(语法 + 规范)
类的三要素
类名:采用大驼峰命名法(首字母大写,如Person、CoffeeMachine)
属性:描述事物的静态特征(如姓名、颜色、车轮数)
方法:描述事物的动态行为(如行驶、冲泡、加热)
基础语法
class 类名:
# 1. 类属性(声明在方法外部)
类属性名 = 属性值
# 2. 方法(声明在类内部,类似函数)
def 方法名(self, 参数...):
方法体
# 实例属性(声明在方法内部,用self修饰)
self.实例属性名 = 属性值示例:定义 “汽车类”
class Car:
# 类属性:所有汽车共享的特征
wheels = 4 # 车轮数(默认4个)
# 实例方法:汽车的行为
def drive(self):
# 实例属性:每个对象独有的特征(可动态添加)
self.speed = 0
print("汽车开始行驶")
def accelerate(self, increment):
self.speed += increment
print(f"加速至 {self.speed} km/h")8.3.1 属性:类属性 vs 实例属性
类型
声明位置
访问方式
修改方式
作用域
类属性:类内部、方法外部
类。属性 / 对象。属性
只能通过类修改
所有对象共享
实例属性:方法内部(self 修饰)
只能通过对象访问
对象。属性 = 新值
仅当前对象
代码示例:属性的使用与修改
class Car:
wheels = 4 # 类属性(所有汽车共享)
def __init__(self):
self.color = "红色" # 实例属性(每个对象独有)
# 1. 访问属性
my_car1 = Car()
print(Car.wheels) # 类访问类属性 → 4
print(my_car1.wheels) # 对象访问类属性 → 4
print(my_car1.color) # 对象访问实例属性 → 红色
# 2. 修改属性
Car.wheels = 3 # 类修改类属性(影响所有对象)
my_car1.wheels = 5 # 对象"影子修改"类属性(仅影响当前对象)
my_car1.color = "蓝色" # 对象修改实例属性
# 验证结果
my_car2 = Car()
print(Car.wheels) # → 3(类属性已被修改)
print(my_car1.wheels) # → 5(当前对象的修改)
print(my_car2.wheels) # → 3(新对象继承修改后的类属性)
print(my_car1.color) # → 蓝色(实例属性修改)
print(my_car2.color) # → 红色(新对象的默认实例属性)8.3.2 方法:实例方法 vs 类方法 vs 静态方法
类型
装饰器
第一个参数
调用方式
作用
实例方法:无
self(代表对象)
只能对象调用
操作实例属性、实现对象行为
类方法:@classmethod
cls(代表类)
类 / 对象均可调用
操作类属性、创建实例
静态方法
@staticmethod
没有默认参数
类 / 对象均能调用
独立功能(不依赖于类 / 对象属性)
代码示例:三种方法的使用
class Car:
wheels = 4 # 类属性
# 1. 实例方法
def drive(self, speed):
print(f"汽车以{speed}km/h行驶")
# 2. 类方法(用cls访问类属性)
@classmethod
def change_wheels(cls, num):
cls.wheels = num
print(f"车轮数修改为:{cls.wheels}")
# 3. 静态方法(独立功能)
@staticmethod
def check_safety():
print("正在进行安全检查...")
# 调用方法
my_car = Car()
my_car.drive(80) # 实例方法 → 汽车以80km/h行驶
Car.change_wheels(6) # 类方法 → 车轮数修改为:6
my_car.check_safety() # 静态方法 → 正在进行安全检查...
8.3.3 私有成员:数据安全的保障
1) 为什么需要私有成员?
类的公开成员可以被外部随意访问和修改,可能导致数据混乱。私有成员限制外部访问,仅允许类内部使用,增强代码安全性。
定义方式:属性 / 方法名前加双下划线(__)
class Car:
__engine = "V8" # 私有类属性
wheels = 4 # 公开类属性
def __start(self): # 私有方法
print(f"启动{self.__engine}发动机")
# 公开方法(内部访问私有成员)
def run(self):
self.__start()
print("汽车正常行驶")
# 测试
my_car = Car()
my_car.run() # 输出:启动V8发动机 → 汽车正常行驶
# 外部访问私有成员(报错)
print(my_car.__engine) # AttributeError
my_car.__start() # AttributeError
注意:
- 核心要点:类是抽象模板,对象是具体实例;属性描述特征,方法描述行为。
- 易错点:
- 实例属性必须通过self声明,且只能通过对象访问。
- 类方法用cls访问类属性,静态方法不能直接访问类 / 实例属性。
- 私有成员不能外部直接访问,需通过公开方法间接操作。
8.4:特殊方法:构造与析构
8.4.1 构造方法
__init__()
作用:创建对象时自动调用,用于初始化对象属性
分类:无参构造、有参构造
示例 1:无参构造(固定初始值)
class Car:
def __init__(self):
self.color = "红色" # 所有对象默认红色
self.speed = 0
my_car = Car()
print(my_car.color) # → 红色
示例 2:有参构造(动态初始化)
class Car:
def __init__(self, color, speed=0):
self.color = color # 传入颜色
self.speed = speed # 可选参数(默认0)
# 创建不同属性的对象
car1 = Car("蓝色")
car2 = Car("黑色", 50)
print(car1.color, car1.speed) # → 蓝色 0
print(car2.color, car2.speed) # → 黑色 50
8.4.2 析构方法
__del__()
作用:对象被销毁时自动调用,用于释放资源(如关闭文件、断开数据库连接)
对象销毁时机:Python 通过 “引用计数器” 管理内存,当对象引用数为 0 时,系统自动销毁对象
示例:析构方法的使用
class Car:
def __init__(self, name):
self.name = name
print(f"{self.name}已创建")
def __del__(self):
print(f"{self.name}已销毁(释放内存)")
# 测试
car = Car("特斯拉") # → 特斯拉已创建
del car # 手动销毁对象 → 特斯拉已销毁(释放内存)
扩展:与文件类似,每个对象都会占用系统的一块内存,使用之后若不及时销毁,会浪费系统资源。那么对象什么时候销毁呢?
答:Python通过引用计数器记录所有对象的引用(可以理解为对象所占内存的别名)数量,一旦某个对象的引用计数器的值为0,系统就会销毁这个对象,收回对象所占用的内存空间。
8.5:封装:隐藏细节,安全访问
封装是面向对象的基础特性,核心思想是隐藏类的内部实现细节,仅提供公开接口供外部访问。
这样既保障了数据的安全性,也简化了外部使用类的复杂度(无需关心内部逻辑)。
实现要求
类的属性声明为:
私有属性(Python 中用双下划线
__提供两类公开方法(
get_xxx()set_xxx()代码示例
class Person:
def __init__(self, name):
self.name = name # 公开属性(姓名)
self.__age = 1 # 私有属性(年龄,默认1岁)
# 公开方法:设置年龄(含合法性检验)
def set_age(self, new_age):
if 0 < new_age <= 120: # 限制年龄范围,确保数据安全
self.__age = new_age
# 公开方法:获取年龄
def get_age(self):
return self.__age
# 外部使用:仅通过公开接口操作,无需关心内部实现
person = Person("杰瑞")
person.set_age(22)
print(f"姓名是{person.name},年龄为{person.get_age()}岁") # 输出:姓名是杰瑞,年龄为22岁核心优势:
- 数据安全:防止外部直接修改属性导致的非法值(如年龄设为 200)。
- 低耦合度:外部与类的内部实现解耦,后续调整内部逻辑不影响外部使用。
8.6:继承:复用代码,扩展功能
继承用于描述类之间的 “从属关系”,核心是在不更改原有类的基础上,复用其代码并增加新功能。被继承的类称为 “父类(基类)”,继承的类称为 “子类(派生类)”,子类会自动获得父类的所有公开成员(属性和方法)。
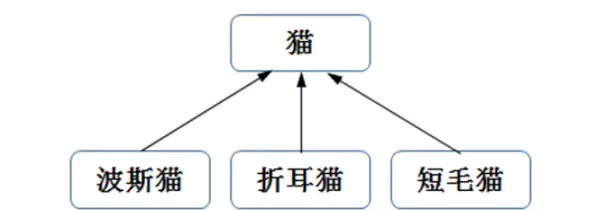
8.6.1. 单一继承:子类仅从一个父类继承
单一继承是最常见的形式,子类只关联一个父类。例如,在现实生活中,波斯猫、折耳猫、短毛猫都属于猫类,它们之间的关系即为单继承,如图所示。
语法格式
class 子类名(父类名):
# 子类自身的属性和方法(可选)
pass
代码示例
# 父类:猫类
class Cat(object):
def __init__(self, color):
self.color = color # 公开属性:颜色
self.__age = 1 # 私有属性:年龄(子类无法直接访问)
# 公开方法:猫的行为
def walk(self):
print("走猫步")
# 私有方法:子类无法直接调用
def __test(self):
print("父类私有方法")
# 子类:折耳猫(继承自 Cat)
class ScottishFold(Cat):
pass
# 子类使用:自动获得父类的公开成员
fold = ScottishFold("灰色")
print(f"{fold.color}的折耳猫") # 输出:灰色的折耳猫(访问父类公开属性)
fold.walk() # 输出:走猫步(调用父类公开方法)
# 注意:子类不会拥有父类的私有成员,也无法访问父类的私有成员。
# 错误示范:子类无法访问父类私有成员
# print(fold.__age) # 报错:AttributeError(无__age属性)
# fold.__test() # 报错:AttributeError(无__test方法)
8.6.2. 多重继承:子类从多个父类继承
子类可以同时从多个父类继承,自动获得所有父类的公开成员。
语法格式
class 子类名(父类名1, 父类名2, ...):
pass
代码示例(房车:继承房屋和汽车的功能)
# 父类1:房屋类
class House(object):
def live(self):
print("供人居住")
# 父类2:汽车类
class Car(object):
def drive(self):
print("行驶")
# 子类:房车(同时继承 House 和 Car)
class TouringCar(House, Car):
pass
# 子类使用:调用多个父类的方法
tour_car = TouringCar()
tour_car.live() # 输出:供人居住(调用 House 类方法)
tour_car.drive() # 输出:行驶(调用 Car 类方法)
关键注意点(同名方法优先级)
如果多个父类有同名方法,子类会根据继承顺序优先调用先声明的父类方法。
即如果子类从多个平行关系的父类中继承,那么子类将先继承哪个类,便会先调用哪个类的方法。
8.6.3. 重写:子类自定义父类方法
子类会完整地继承父类的方法,但如需适配自身需求,可以在子类中定义与父类同名的方法,覆盖父类方法(即 “重写”)。
代码示例(重写 + 调用父类方法)
# 父类:人类
class Person(object):
...
```
def say_hello(self):
print("打招呼!")
# 子类:中国人(重写父类方法)
class Chinese(Person):
def say_hello(self):
# 通过使用super()函数,子类可以在重写父类方法后间接调用父类的同名方法。
super().say_hello()
print("阿吃过啦") # 子类自定义逻辑
# 调用结果:优先执行子类中已重写的方法
chinese = Chinese()
chinese.say_hello()
# 输出:
# 打招呼!
# 阿吃过啦
8.7:多态:同一接口,不同行为
多态是面向对象编程中的灵活特性,其核心在于
使不同类的相同功能通过一个接口调用时表现出各异的行为
。其实现依赖 “继承 + 方法重写”。
主要逻辑
定义统一接口(函数或方法),接收 “父类类型” 的参数。
各子类重写该接口对应的方法,实现自定义行为。
当调用接口时,传入不同子类的实例,自动执行相应子类的方法。
代码示例(动物叫:不同动物发出不同的叫声)
# 父类:猫
class Cat:
def shout(self):
print("喵喵喵~")
# 父类:狗(虽无显式继承,但遵循同一接口规范)
class Dog:
def shout(self):
print("汪汪汪!")
# 统一接口:接受任意实现了 shout() 方法的对象
def animal_shout(obj):
obj.shout()
# 多态体现:同一接口调用不同对象时行为各异
cat = Cat()
dog = Dog()
animal_shout(cat) # 输出:喵喵喵~
animal_shout(dog) # 输出:汪汪汪!
主要优势
灵活性高:添加新的子类(例如 Bird 类)时,无需更改接口代码,可直接复用。
代码简洁:统一接口减少了冗余,降低了调用者的记忆负担。
8.8:运算符重载:赋予运算符新功能
运算符重载是 Python 的高级特性,核心在于
重写基类 object 的特殊方法
,使得
+
、
-
、
*
等内置运算符能适用于自定义类的实例。
常用运算符及对应的特殊方法
运算符
特殊方法
功能描述
+
__add__(self, other)
加法操作
-
__sub__(self, other)
减法操作
*
__mul__(self, other)
乘法操作
/
__truediv__(self, other)
除法操作(真除法)
代码示例(自定义计算器类)
class Calculator(object):
def __init__(self, number):
self.number = number # 初始化数值
# 重载 + 运算符
def __add__(self, other):
self.number += other
return self.number
# 重载 - 运算符
def __sub__(self, other):
self.number -= other
return self.number
# 重载 * 运算符
def __mul__(self, other):
self.number *= other
return self.number
# 重载 / 运算符(注意:除数不能为0)
def __truediv__(self, other):
if other != 0:
self.number /= other
return self.number
else:
raise ValueError("除数不可为0")
# 使用示例
calc = Calculator(10)
print(calc + 5) # 输出:15(调用 __add__)
print(calc - 3) # 输出:12(调用 __sub__)
print(calc * 2) # 输出:24(调用 __mul__)
print(calc / 4) # 输出:6.0(调用 __truediv__)
总结:
面向对象的三大特性各有侧重点:
封装:保护数据,隐藏细节(“安全”);
继承:重用代码,快速扩展(“高效”);
多态:统一接口,灵活适应(“灵活”);
运算符重载:拓展运算符功能,使自定义类更易操作。
掌握这些特性后,可以编写更加易于维护和可扩展的 Python 代码,尤其适用于大型项目开发。
第9章:异常
程序开发与运行中,异常是不可避免的。它可能源于代码设计缺陷,也可能由外部环境变化(如文件缺失、输入错误)引起。如果不加以处理,程序会直接终止并返回错误信息。
9.1:异常概述
异常是在程序执行时发生的错误事件,会导致正常流程中断。当程序没有设置异常处理机制时,默认情况下 Python 解释器将以如下方式响应:输出异常信息(包括行号、类型和描述)并终止程序。
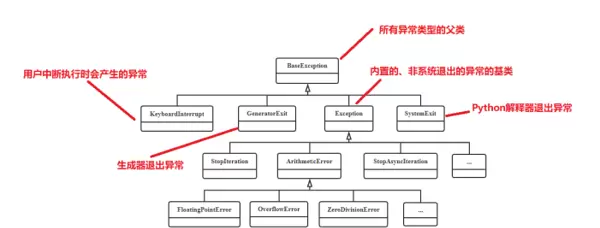
9.1.1 核心异常类型
Python 中所有异常都继承自
BaseException
类,常见的业务异常多继承自其子类
Exception
。以下是开发中频繁遇到的异常类型:
NameError
:使用未定义的变量或函数时触发。
IndexError
:列表、元组等序列类型的索引超出范围访问时触发。
AttributeError
:尝试访问对象不存在的属性或方法时触发。
FileNotFoundError
:尝试打开不存在的文件或目录时触发。
ZeroDivisionError
:除数为 0 时触发(如
5/0
)。
ValueError
:传入的值类型正确但内容无效(如
int('abc')
)。
9.1.2 异常信息示例
异常触发时,解释器输出的 Traceback 信息格式如下(以除零错误为例):
Traceback (most recent call last):
File "E:\pyproject\异常\异常概念.py", line 1, in <module>
print(5/0)
ZeroDivisionError: division by zero
信息包含三个部分:
错误发生的文件路径与行号、引发错误的代码、异常类型及描述。
9.2:异常捕获:try-except 相关语句
Python 提供
try-except
系列语句来捕捉并处理异常,防止程序意外终止。可根据需求选择基础捕获、组合子句等不同用法。
9.2.1 基础用法:try-except
主要作用是监控
try
块中的代码,当异常发生时执行
except
块的处理逻辑。
语法规则:
try:
可能出错的代码
except [异常类型 [as error]]: # 将捕获到的异常对象赋值给error
捕获异常后的处理代码
try-except 语句可以捕捉与处理程序中的单个、多个或全部异常。
(1)捕捉单个异常
针对特定类型的异常单独处理,精准定位问题。
num1 = int(input('请输入被除数:'))
num2 = int(input('请输入除数:'))
try:
print('结果为', num1 / num2)
except ZeroDivisionError: # 单个异常类型
print('出错了:除数不能为0')
(2)捕捉多个异常
用元组指定多种类型的异常,统一处理同类错误。
# 如果输入的是字母进行异常捕捉
try:
num1 = int(input('请输入被除数:'))
num2 = int(input('请输入除数:'))
print('结果为', num1 / num2)
except (ZeroDivisionError, ValueError) as error: # 定义error变量输出异常内容
print('出错了:', error) # 输出具体的异常描述
(3)捕捉所有异常
通过
Exception
(所有业务异常的父类)捕获未明确指定的异常,适合兜底处理。
try:
num1 = int(input('请输入被除数:'))
num2 = int(input('请输入除数:'))
print('结果为', num1 / num2)
except Exception as error: # 父类异常
print('出错了:', error)
9.2.2 组合用法:try-except-else
else
子句在
try
块未发生异常时执行,用于处理正常流程的后续逻辑。
语法规则:
try:
可能出错的代码
except [异常类型 [as error]]: # 将捕获到的异常对象赋值给error
捕获异常后的处理代码
else:
未捕获异常后的处理代码
**示例:**如果除法过程没有异常则输出结果
try:
num1 = int(input('请输入被除数:'))
num2 = int(input('请输入除数:'))
result = num1 / num2
except Exception as error:
print('出错了:', error)
else:
print('计算成功,结果是:', result) # 无异常时执行
9.2.3 强制执行:try-except-finally
finally
子句无论
try
块是否发生异常,都会执行。常用于资源清理(如关闭文件、网络连接)。
语法规则:
try:
可能出错的代码
except [异常类型 [as error]]: # 将捕获到的异常对象赋值给error
捕获异常后的处理代码
finally:
一定执行的代码
示例:
try:
file = open('f:\\luckycloud.txt', mode='r', encoding='utf-8')
print(file.read())
except FileNotFoundError as error:
print('文件操作出错:', error)
finally:
file.close() # 不论是否出现错误,均关闭文件
print('文件已关闭')
9.3:主动引发异常:raise 与 assert
除了程序自动产生的异常,开发人员也可以通过语句主动引发异常,用于验证输入、标记业务问题等场景。
9.3.1 raise 语句
明确地引发指定的异常,支持三种使用格式,可以自定义异常描述信息。
raise语句的语法结构如下:
raise 异常类 # 格式1:通过异常类名引起特定的异常
raise 异常类实例 # 格式2:通过异常类的实例引起特定的异常
raise # 格式3: 重新引发刚刚出现过的异常
# 格式1:直接引发异常类
raise IndexError
# 格式2:经由异常对象引发(可附带描述)
index_error = IndexError('索引超出范围')
raise index_error
# 格式3:再次抛出刚捕获的异常
try:
5 / 0
except:
print('检测到异常,重新抛出')
raise
# 格式4:异常链(一个异常触发另一个异常)
try:
5 / 0
except Exception as e:
raise IndexError('索引错误') from e # 记录原始异常上下文
9.3.2 assert 语句(断言语句)
用于检验表达式是否成立,如果不成立则引发
AssertionError
异常。适用于调试阶段的逻辑验证(如参数合法性)。
语法结构:
assert 表达式[, 异常信息]
示例:
num1 = int(input('请输入被除数:'))
num2 = int(input('请输入除数:'))
assert num2 != 0, '除数不可为0' # 当表达式为False时触发异常
result = num1 / num2
print(f'{num1} / {num2} = {result}')
执行结果(如果输入的除数为 0):
Traceback (most recent call last):
File "E:\pyproject\异常\assert.py", line 3, in <module>
assert num2 != 0,'除数不能为0' #assert语句判定num2不等于0
^^^^^^^^^
AssertionError: 除数不能为0
9.3.3 异常的传播机制
异常会沿着函数调用
堆栈
由内向外
传播,直到被捕捉或导致程序终止。
示例:
def func_b():
raise ValueError('提供的值无效') # 内层函数引发异常
def func_a():
func_b() # 调用内层函数,没有捕捉异常
try:
func_a() # 外部捕捉传递的异常
except ValueError as e:
print('捕捉到异常:', e)
输出:
捕获到异常:输入值无效
9.4:自定义异常
当 Python 内置异常不能满足业务需求时,可以创建自定义异常类。需要继承
Exception
(或其子类),类名建议以
Error
结尾,提高可读性。
自定义异常示例:
# 定义自定义异常类
class ShortPwd(Exception):
'''自定义异常'''
def __init__(self, length, atleast):
self.length = length
self.atleast = atleast
try:
text = input('请输入密码:')
if len(text) < 3:
raise ShortPwd(len(text), 3)
except ShortPwd as result:
print('ShortPwd:输入的长度是%d,最小长度应为%d' % (result.length, result.atleast))
运行结果:
请输入密码:12
ShortPwd:输入的长度是2,长度至少应该是3
请输入密码:1234
设置密码成功
9.4.1 自定义异常要点
必须继承自
Exception
(而不是
BaseException
,以防捕获系统级异常)。
可以添加自定义属性和方法,以扩展异常信息。
配合
raise
语句使用,在业务规则不满足时主动触发。

 京公网安备 11010802022788号
京公网安备 11010802022788号







