


 雷达卡
雷达卡



TSFresh(基于可扩展假设检验的时间序列特征提取)是一个专注于自动化提取时间序列数据特征的工具框架。该框架所生成的特征可广泛应用于回归、分类以及异常检测等机器学习任务中,有效简化了传统时间序列分析中的特征工程流程,显著提升了建模效率。
在实际应用中,TSFresh能够处理数百种统计类特征,例如均值、方差、偏度及自相关性等,并结合统计显著性检验对这些特征进行筛选,保留具有解释力的关键特征,同时剔除冗余或不相关的部分。此方法适用于单变量和多变量时间序列场景,具备良好的通用性和扩展性。
其核心工作流程主要包括三个阶段:首先将原始数据转换为指定格式;随后调用
extract_features执行自动化的特征提取;最后可根据需要使用
select_features完成特征选择步骤。
输入数据需遵循长格式(Long Format)结构,每个时间序列必须包含一个唯一的标识列,用于区分不同序列个体,这是确保特征正确提取的基础要求。
id构建示例与数据可视化
以下构建了一个包含100组观测、每组生成约100个特征的时间序列数据集:
importpandasaspd
importnumpyasnp
fromtsfreshimportextract_features
fromtsfreshimportselect_features
fromtsfresh.utilities.dataframe_functionsimportimpute
fromtsfresh.feature_extractionimportEfficientFCParameters
fromtsfresh.feature_extraction.feature_calculatorsimportmean
fromsklearn.model_selectionimporttrain_test_split
fromsklearn.ensembleimportRandomForestClassifier
fromsklearn.metricsimportaccuracy_score, classification_report, confusion_matrix
importmatplotlib.pyplotasplt
importseabornassns
# 构建大规模样本数据集
np.random.seed(42)
n_series=100
n_timepoints=100
time_series_list= []
foriinrange(n_series):
frequency=np.random.uniform(0.5, 2)
phase=np.random.uniform(0, 2*np.pi)
noise_level=np.random.uniform(0.05, 0.2)
values=np.sin(frequency*np.linspace(0, 10, n_timepoints) +phase) +np.random.normal(0, noise_level, n_timepoints)
df=pd.DataFrame({
'id': i,
'time': range(n_timepoints),
'value': values
})
time_series_list.append(df)
time_series=pd.concat(time_series_list, ignore_index=True)
print("Original time series data:")
print(time_series.head())
print(f"Number of time series: {n_series}")
print(f"Number of timepoints per series: {n_timepoints}")为了直观理解数据结构,对其进行可视化分析:
# 选择性可视化时间序列数据
plt.figure(figsize=(12, 6))
foriinrange(5): # 绘制前5条时间序列
plt.plot(time_series[time_series['id'] ==i]['time'],
time_series[time_series['id'] ==i]['value'],
label=f'Series {i}')
plt.title('Sample of Time Series')
plt.xlabel('Time')
plt.ylabel('Value')
plt.legend()
plt.savefig("sample_TS.png")
plt.show()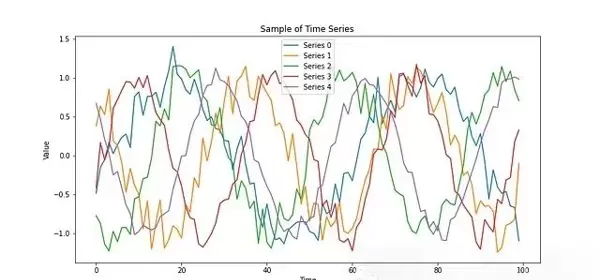
从图形可以看出,数据呈现出预期的随机波动模式,符合真实世界中常见时间序列的基本特性,如噪声干扰与动态变化。
特征提取实现
当前数据具备典型的时间序列属性,包含一定的噪声和趋势波动。接下来利用
tsfresh.extract_features函数启动特征提取过程。
# 执行特征提取
features=extract_features(time_series, column_id="id", column_sort="time", n_jobs=0)
print("\nExtracted features:")
print(features.head())
# 对缺失值进行插补处理
features_imputed=impute(features)部分输出结果如下所示(展示部分提取出的特征):
value__mean value__variance value__autocorrelation_lag_1
id
1 0.465421 0.024392 0.856201
2 0.462104 0.023145 0.845318特征筛选策略
为提升模型训练效率并降低维度负担,需对提取出的大量特征进行精简。通过调用
select_features函数,依据统计显著性水平对特征进行过滤。
# 构造目标变量(基于频率的二分类)
target=pd.Series(index=range(n_series), dtype=int)
target[features_imputed.index%2==0] =0 # 偶数索引分类
target[features_imputed.index%2==1] =1 # 奇数索引分类
# 执行特征选择
selected_features=select_features(features_imputed, target)
# 特征选择结果处理
ifselected_features.empty:
print("\nNo features were selected. Using all features.")
selected_features=features_imputed
else:
print("\nSelected features:")
print(selected_features.head())
print(f"\nNumber of features: {selected_features.shape[1]}")
print("\nNames of features (first 10):")
print(selected_features.columns.tolist()[:10])该步骤能有效识别出与目标变量存在强关联性的关键特征,从而提高后续建模的稳定性和预测能力。
在监督学习中的应用
特征工程的核心目标是为机器学习模型提供高质量的输入变量。TSFresh可与scikit-learn等主流机器学习库无缝对接,便于集成到标准建模流程中。
以下展示了其在分类任务中的具体应用实例:
# 分类模型构建
# 数据集划分
X_train_clf, X_test_clf, y_train_clf, y_test_clf=train_test_split(
selected_features, target, test_size=0.2, random_state=42
)
# 随机森林分类器训练
clf=RandomForestClassifier(random_state=42)
clf.fit(X_train_clf, y_train_clf)
# 模型评估
y_pred_clf=clf.predict(X_test_clf)
print("\nClassification Model Performance:")
print(f"Accuracy: {accuracy_score(y_test_clf, y_pred_clf):.2f}")
print("\nClassification Report:")
print(classification_report(y_test_clf, y_pred_clf))
# 混淆矩阵可视化
cm=confusion_matrix(y_test_clf, y_pred_clf)
plt.figure(figsize=(8, 6))
sns.heatmap(cm, annot=True, fmt='d', cmap='Blues')
plt.title('Confusion Matrix')
plt.xlabel('Predicted')
plt.ylabel('Actual')
plt.savefig("confusion_matrix.png")
plt.show()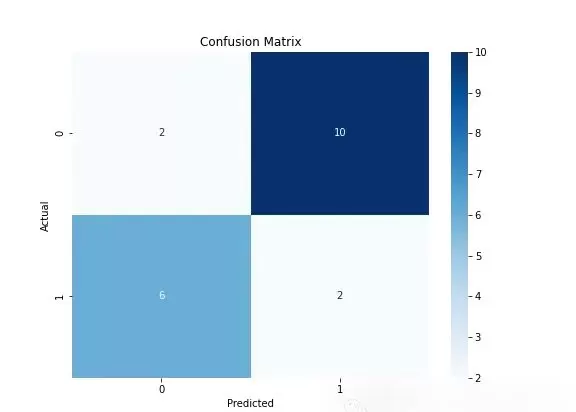
# 特征重要性分析
feature_importance=pd.DataFrame({
'feature': X_train_clf.columns,
'importance': clf.feature_importances_
}).sort_values('importance', ascending=False)
print("\nTop 10 Most Important Features:")
print(feature_importance.head(10))
# 特征重要性可视化
plt.figure(figsize=(12, 6))
sns.barplot(x='importance', y='feature', data=feature_importance.head(20))
plt.title('Top 20 Most Important Features')
plt.xlabel('Importance')
plt.ylabel('Feature')
plt.savefig("feature_importance.png")
plt.show()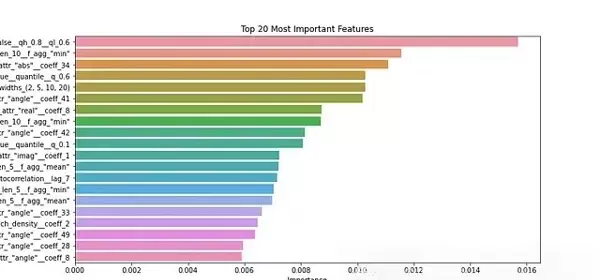
多变量时间序列支持
除了单变量处理外,TSFresh同样支持对多个变量同时进行特征提取,适用于复杂系统或多通道信号的数据分析场景。
# 多变量特征提取示例
# 添加新的时间序列变量
time_series["value2"] =time_series["value"] *0.5+np.random.normal(0, 0.05, len(time_series))
# 对多个变量进行特征提取
features_multivariate=extract_features(
time_series,
column_id="id",
column_sort="time",
default_fc_parameters=EfficientFCParameters(),
n_jobs=0
)
print("\nMultivariate features:")
print(features_multivariate.head())自定义特征函数扩展
为进一步增强灵活性,TSFresh允许用户通过
tsfresh.feature_extraction.feature_calculators模块来自定义特征提取逻辑,满足特定业务需求或研究目标。
# 多变量特征提取实现
# 构造附加时间序列变量
time_series["value2"] =time_series["value"] *0.5+np.random.normal(0, 0.05, len(time_series))
# 执行多变量特征提取
features_multivariate=extract_features(
time_series,
column_id="id",
column_sort="time",
default_fc_parameters=EfficientFCParameters(),
n_jobs=0
)
print("\nMultivariate features:")
print(features_multivariate.head())以下为使用matplotlib对提取后的特征分布情况进行可视化展示:
# 计算时间序列均值特征
custom_features=time_series.groupby("id")["value"].apply(mean)
print("\nCustom features (mean of each time series, first 5):")
print(custom_features.head())
# 特征分布可视化
plt.figure(figsize=(10, 6))
sns.histplot(custom_features, kde=True)
plt.title('Distribution of Mean Values for Each Time Series')
plt.xlabel('Mean Value')
plt.ylabel('Count')
plt.savefig("dist_of_means_TS.png")
plt.show()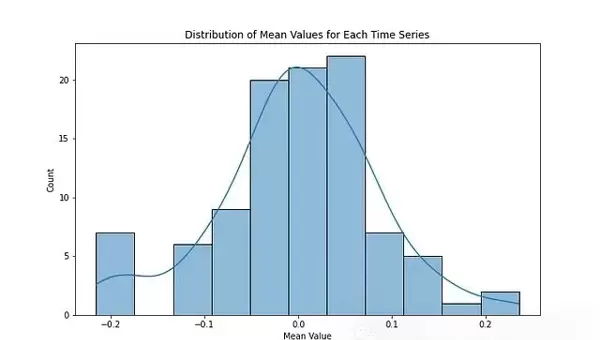
# 特征与目标变量关系可视化
plt.figure(figsize=(10, 6))
sns.scatterplot(x=custom_features, y=target)
plt.title('Relationship between Mean Values and Target')
plt.xlabel('Mean Value')
plt.ylabel('Target')
plt.savefig("means_v_target_TS.png")
plt.show()
总结
TSFresh在时间序列特征工程领域展现出强大的自动化能力。其通过系统化地生成大量候选特征,为下游机器学习任务提供了丰富的信息输入。然而,也应注意,自动生成的高维特征空间可能带来过拟合风险,尤其是在样本量有限的情况下。这一问题仍需结合具体应用场景开展更多实证研究加以验证与优化。

 京公网安备 11010802022788号
京公网安备 11010802022788号







