


 雷达卡
雷达卡
















 The recent post on KDnuggets
The recent post on KDnuggets 20 Questions to Detect Fake Data Scientists has been very popular - most viewed in the month of January.
However these questions were lacking answers, so KDnuggets Editors got together and wrote the answers to these questions. I also added one more critical question - number 21, which was omitted from the 20 questions post.
Here are the answers. Because of the length, here are the answers to the first 11 questions, and here is part 2.
Q1. Explain what regularization is and why it is useful.
Answer by Matthew Mayo.
Regularization is the process of adding a tuning parameter to a model to induce smoothness in order to prevent overfitting. (see also KDnuggets posts on Overfitting)
This is most often done by adding a constant multiple to an existing weight vector. This constant is often either the L1 (Lasso) or L2 (ridge), but can in actuality can be any norm. The model predictions should then minimize the mean of the loss function calculated on the regularized training set.
Xavier Amatriain presents a good comparison of L1 and L2 regularization here, for those interested.
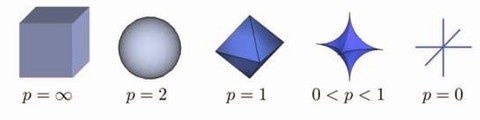
Fig 1: Lp ball: As the value of p decreases, the size of the corresponding L-p space also decreases.
Q2. Which data scientists do you admire most? which startups?
Answer by Gregory Piatetsky:
This question does not have a correct answer, but here is my personal list of 12 Data Scientists I most admire, not in any particular order.

Geoff Hinton, Yann LeCun, and Yoshua Bengio - for persevering with Neural Nets when and starting the current Deep Learning revolution.
Demis Hassabis, for his amazing work on DeepMind, which achieved human or superhuman performance on Atari games and recently Go.
Jake Porway from DataKind and Rayid Ghani from U. Chicago/DSSG, for enabling data science contributions to social good.
DJ Patil, First US Chief Data Scientist, for using Data Science to make US government work better.
Kirk D. Borne for his influence and leadership on social media.
Claudia Perlich for brilliant work on ad ecosystem and serving as a great KDD-2014 chair.
Hilary Mason for great work at Bitly and inspiring others as a Big Data Rock Star.
Usama Fayyad, for showing leadership and setting high goals for KDD and Data Science, which helped inspire me and many thousands of others to do their best.
Hadley Wickham, for his fantastic work on Data Science and Data Visualization in R, including dplyr, ggplot2, and Rstudio.
There are too many excellent startups in Data Science area, but I will not list them here to avoid a conflict of interest.
Here is some of our previous coverage of startups.
Q3. How would you validate a model you created to generate a predictive model of a quantitative outcome variable using multiple regression.
Answer by Matthew Mayo.
Proposed methods for model validation:
- If the values predicted by the model are far outside of the response variable range, this would immediately indicate poor estimation or model inaccuracy.
- If the values seem to be reasonable, examine the parameters; any of the following would indicate poor estimation or multi-collinearity: opposite signs of expectations, unusually large or small values, or observed inconsistency when the model is fed new data.
- Use the model for prediction by feeding it new data, and use the coefficient of determination (R squared) as a model validity measure.
- Use data splitting to form a separate dataset for estimating model parameters, and another for validating predictions.
- Use jackknife resampling if the dataset contains a small number of instances, and measure validity with R squared andmean squared error (MSE).



 京公网安备 11010802022788号
京公网安备 11010802022788号







