



 雷达卡
雷达卡




1.企业、消费者在网络留下大量痕迹,新时代的经济学管理学需基于大数据重建!
分析经济行为,其实话题、问题在数据,英国皇家学会(2017)的机器学习的研究报告指出91%的全球数据是在过去5年中创造出来的,在这个大数据的时代,包括众多的数据来源、有政府公告、社交网络、交易数据、GPS导航等等。现在全球每天创造数据的速度是每天250亿Gb的惊人速度(汪寿阳、洪永淼、 霍红 、方颖、陈海强,2019)。首先需要掌握网络抓取的能力,下面看几个例子:
Python 爬虫分析2019年杭州国庆工作坊 & 课题申报高级研修
eg1:新浪即时新闻抓取:主要应用包Beautifufsoup
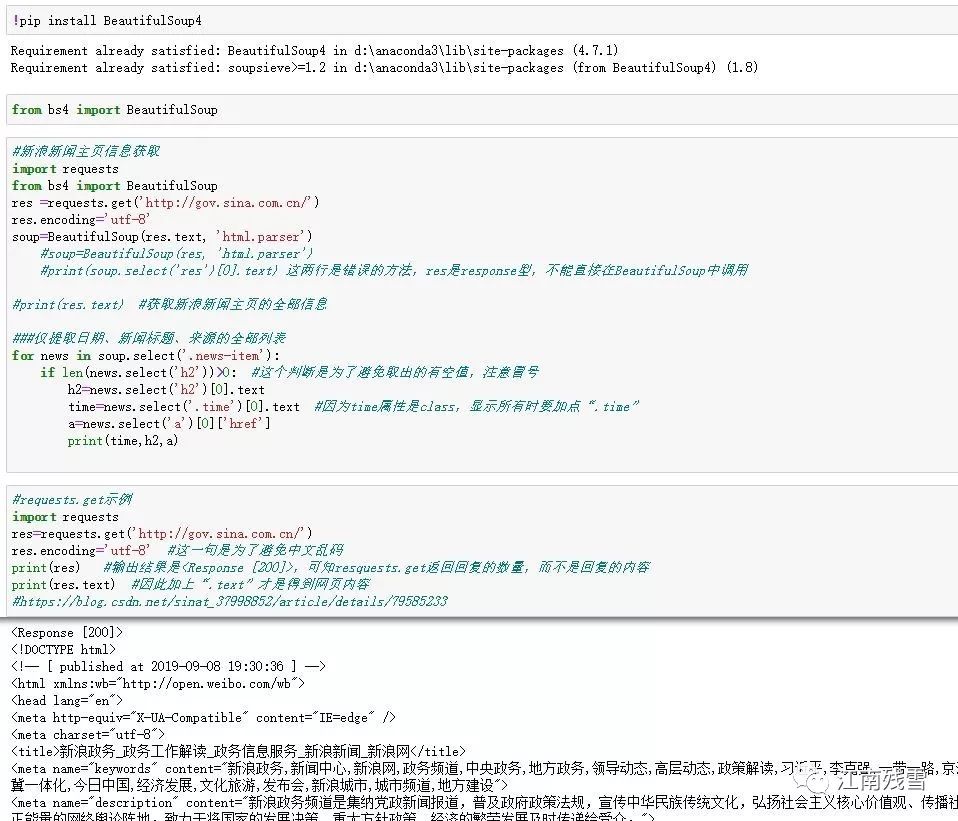

整理格式备用:

原标题:全国已发放价格临时补贴24亿元 惠及困难群众9000余万人次
首先分析网页,最后一行从网页分析知正文在哪?

接着代码提取:
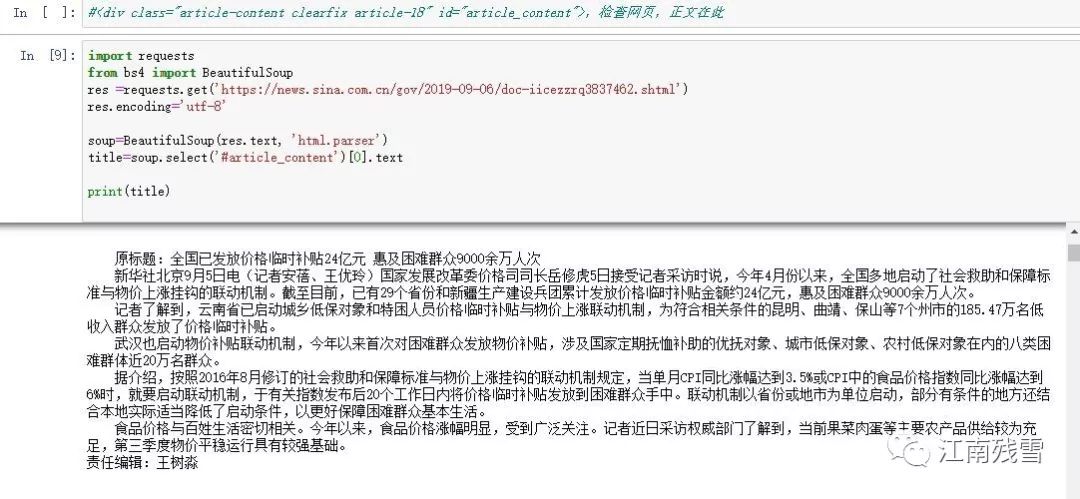
整理后备用:

得益于互联网的快速发展和计算机技术的进步, 文本大数据在经济学和金融学领域的 应用方兴未艾。在经济学领域,文本大数据被用于刻画经济政策不确定性(Baker et al, 2016)、 对行业进行动态分类(Hoberg and Phillips, 2015)、度量和预测经济周期(Thorsrud,2018;Shapiro et al., 2018),和度量媒体政治倾向及新闻需求(Gentzkow and Shapiro, 2010)等问 题。金融学中,文本数据被用于刻画关注度(如 Antweiler and Frank, 2004;Fang and Peress, 2009; Garcia, 2013)、情绪或语调(如 Tetlock 2007;Li 2010;Da et al. 2011;Loughran and McDonald 2011; Jegadeesh and Wu 2013;Kim and Kim 2014;Tsukioka et al. 2018)、新闻隐 含波动率(Manela and Moreira, 2017)和意见分歧(Antweiler and Frank, 2004; Hillert et al. 2018)等方面。非结构化文本大数据的运用拓宽了经济和金融领域的实证研究,但也带来了 新挑战。(沈艳|陈赟|黄卓,北京大学国家发展研究院工作论文,2019)。特朗普执政变幻无常,但其情绪化的特点也为应对中美贸易战提供了线索,提供几个研究其执政思路的github包:
利用机器学习算法进行特朗普twitter的主题分析https://blog.csdn.net/Aaronji1222/article/details/78153269?locationNum=1&fps=1
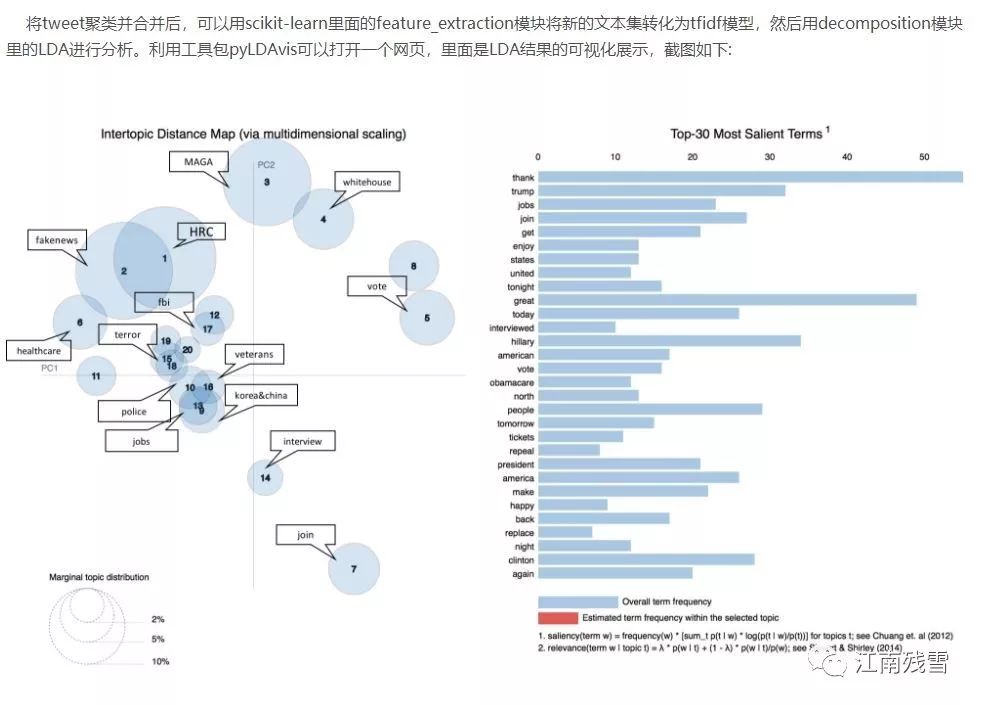
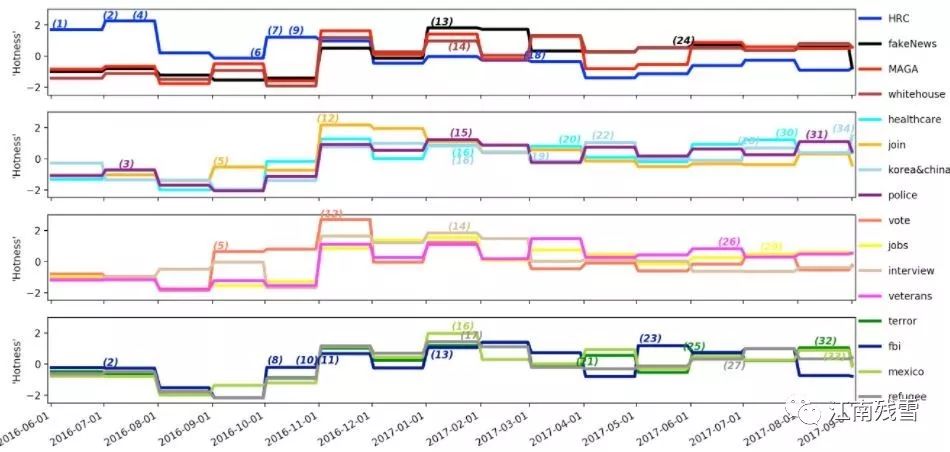
Python代码 GitHub 地址:https://github.com/AaronJi/TrumpTwitterAnalysis
Package要求:sklearn, gensim, nltk, tweepy, pyLDAvis, WordCloud, numpy, pandas
特朗普退出《巴黎协定》:python词云图舆情分析https://www.cnblogs.com/lemonbit/p/6935675.html
https://github.com/RodolfoFerro/pandas_twitter
Python 爬虫分析2019年杭州国庆工作坊 & 课题申报高级研修
eg:天眼查网贷金融数据提取整理备用:
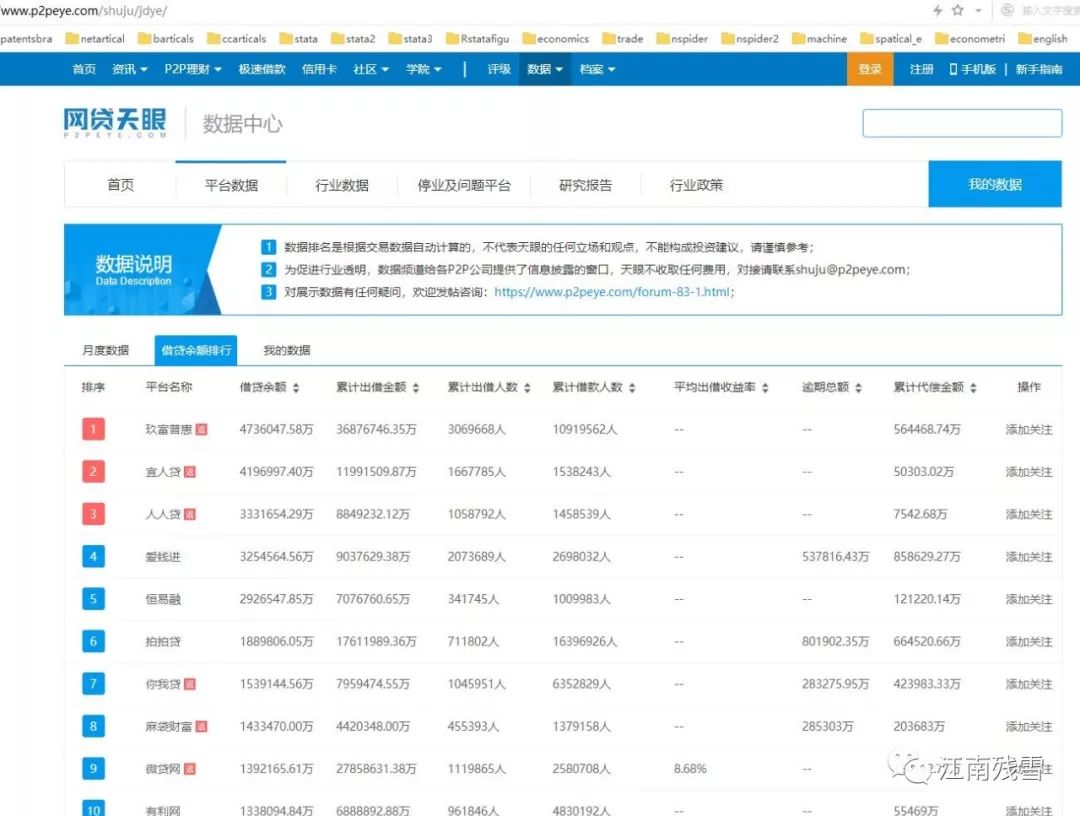

解码读取后还是很乱,比两年前乱多了,但是分析找到提取表格的线索:
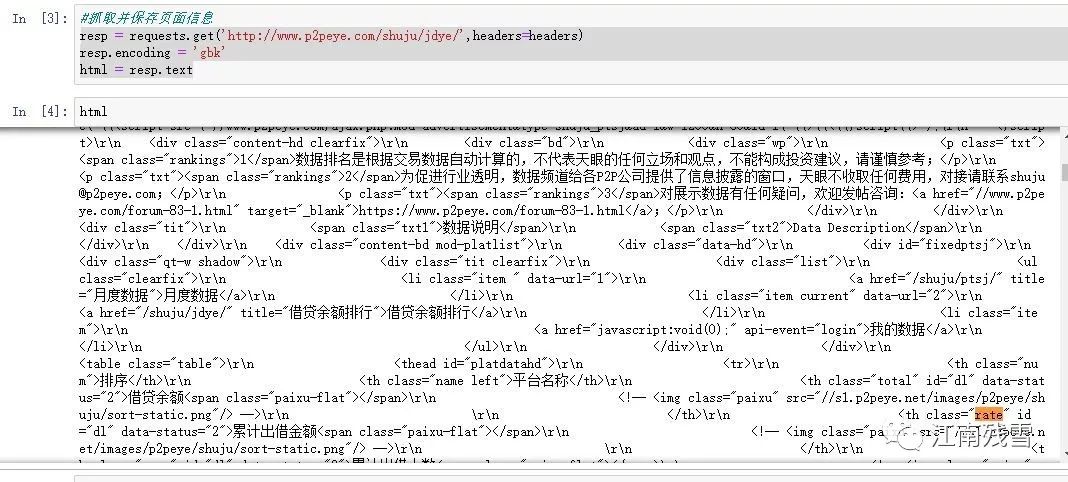
不但乱,而且不能同时看到所有列,由于不同列,padans也要写代码变换。但还是出现空数据,经大邓老师处理后得到:
Python 爬虫分析2019年杭州国庆工作坊 & 课题申报高级研修


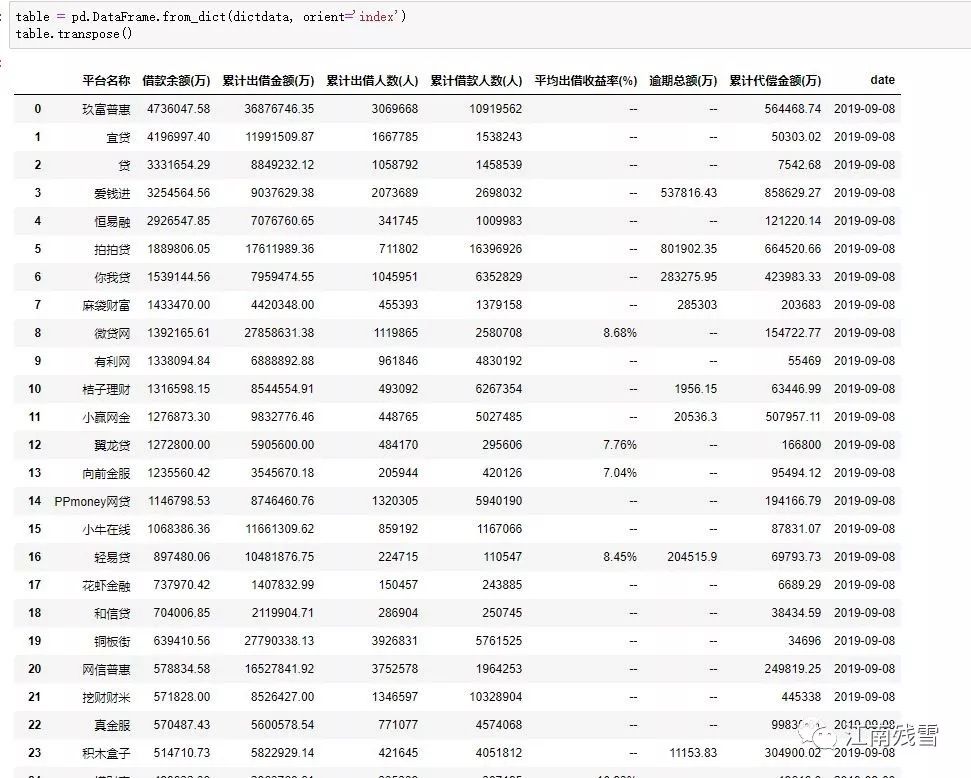
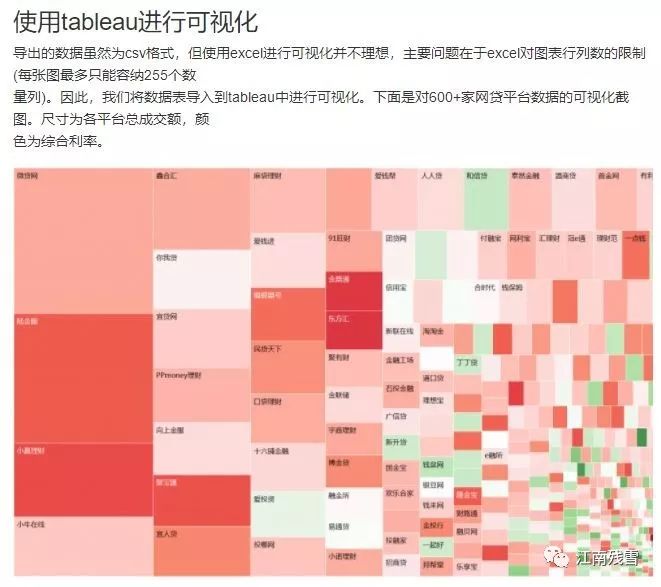
篮鲸工作室两年前的代码已经不能用,但其是始作俑者,还是感谢 蓝鲸(王彦平先生)的推广!
2.机器学习在经济管理方面的应用一瞥
针对高维非结构化数据,一个重要工具就是机器学习(machine learning)技术(也称为人工智能技术)。机器学习的过程本质是一个从数据中建立数学模型的过程,它包括有监督和无监督的学习(supervised and unsupervised learning)、强化学习(enforcement learning)、转移学习(transfer learning)、表示学习(representation learning)、深度学习(deep learning)等。由于这其中的主要贡献者来自于人工智能研究专家,因此被称为机器学习,他们试图强调和追求让机器像人一样去分析和处理自然世界的各类问题的目的。在过去十多年中,以深度学习(深度神经网络[14])为代表的机器学习方法取得了令人瞩目的理论和应用成果,为从大数据(主要是从各类非结构数据中)中抽取有用信息和服务提供了强有力的工具,如图像和人脸识别、声音的识别和处理、自然语言处理和理解、知识脸谱图等各项应用(汪寿阳、洪永淼、 霍红 、方颖、陈海强,2019)。

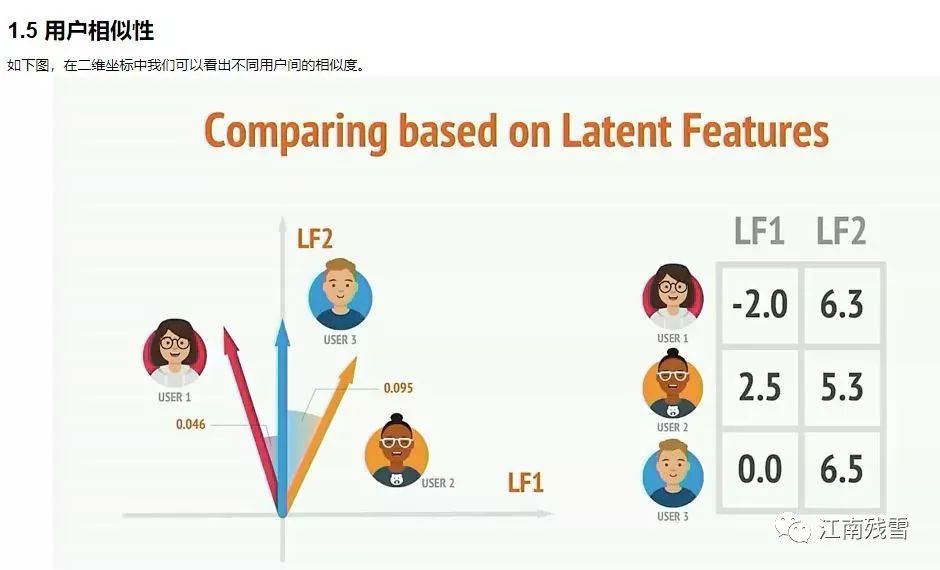
大数据背景下,如何利用大数据来展开因果推断以及政策评估成为一个重要研究方向。此外,大数据也使得我们能够进一步研究政策效应的异质性。比如,政策对结果变量分布尾端人群的影响程度往往不同于对结果变量分布中段人群的影响,同时,众多有关社会福利、平等性问题的回答都有赖于研究者了解政策效应在整个受众人群中的分布情况(汪寿阳、洪永淼、 霍红 、方颖、陈海强,2019)。
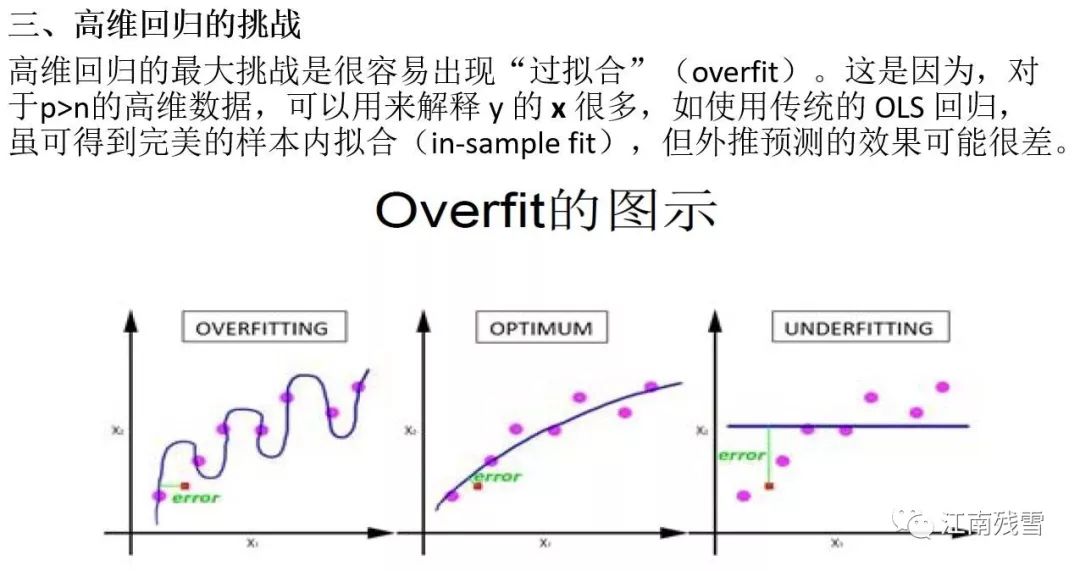

关于机器学习在计量经济学应用,继续参考本公众号此前的推文:
重温经典:“回归控制法”(RCM):附代码经典文献复制,一些更新延伸...
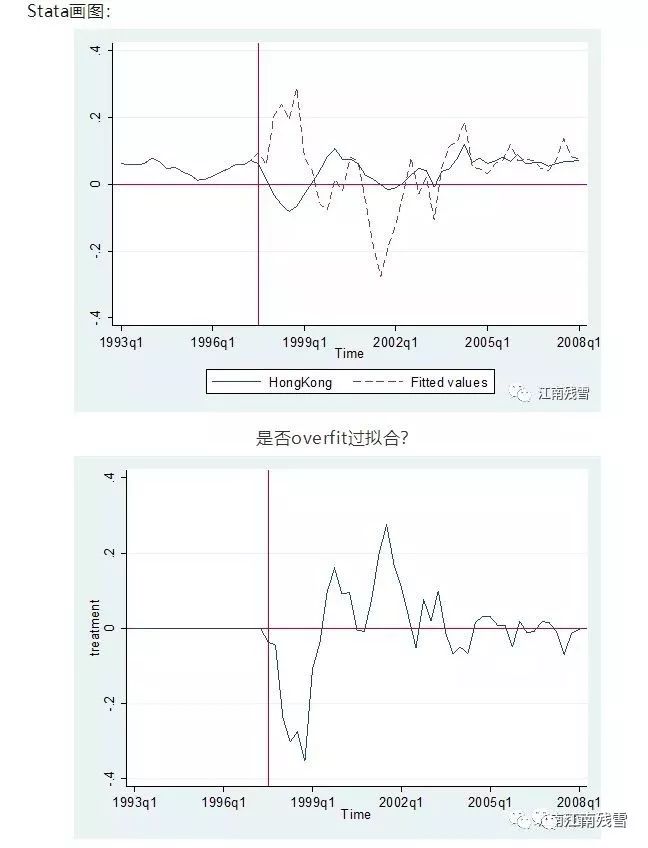

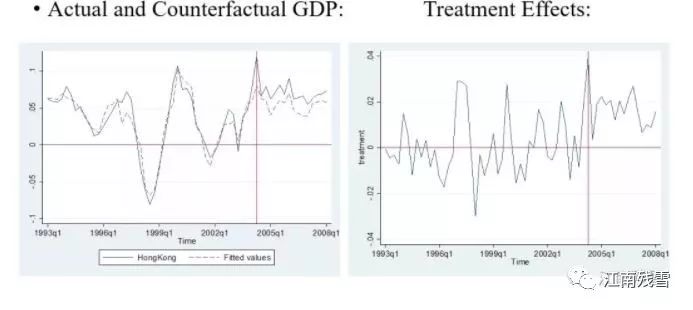
总之,大数据挖掘、基于机器学习改进的因果识别、结构方程估计与简约估计的结合(因为各有其优缺点,争论后还是互补吧!),乃现代计量经济学的三个方向!对于本科阶段,除打好基础外,需要关注这些变化,其实OLS也是最初的机器学习。硕士、博士阶段需要不落伍!周二将比较累,看着也有些头大,但课还是认真背的,效果就不知道了...


 京公网安备 11010802022788号
京公网安备 11010802022788号







