


 雷达卡
雷达卡



引言
随着国内房地产市场步入精细化发展阶段,二手房交易成为推动市场流动的关键环节。购房者、投资者及业内人士对于市场动态与价格走势的需求愈发迫切。作为数据科学家,我们坚信“数据驱动决策”的核心理念——通过深入挖掘大量房产信息中的规律,不仅能够为普通购房者提供科学的参考依据,还能为行业的宏观调控提供有力的数据支持。

项目背景与目标
项目背景
在居住条件改善与房地产市场结构调整的双重作用下,二手房市场的地域差异性和价格影响因素变得更为复杂。不同城市及其内部区域的房价受到地理位置、房屋特性、建筑年代等多种因素的影响,传统的经验判断已经难以适应市场的快速变化。因此,我们选择了三个具有代表性的城市,运用数据挖掘技术建立分析与预测系统,旨在提高市场洞察的精确性。
项目目标
- 数据爬取:使用Python的requests库从链家平台抓取二手房的关键信息,如位置、面积、户型、总价、单价等。
- 数据清洗:执行去重、缺失值填充、异常值处理及数据类型转换等预处理工作,确保数据的质量。
- 数据可视化:借助直方图、词云图、地理分布图等工具,形象地展现市场分布与价格特点。
- 特征工程:挑选并对房价有显著影响的特征进行编码,构建高效的建模数据集。
- 模型训练:基于决策树(DT)、梯度提升树(GBT)、随机森林(RF)三种算法构建价格预测模型,评估各种因素对房价的影响。
- 模型优化:通过剔除异常值和网格搜索调参,提高模型的预测准确率。
数据采集与预处理
数据采集
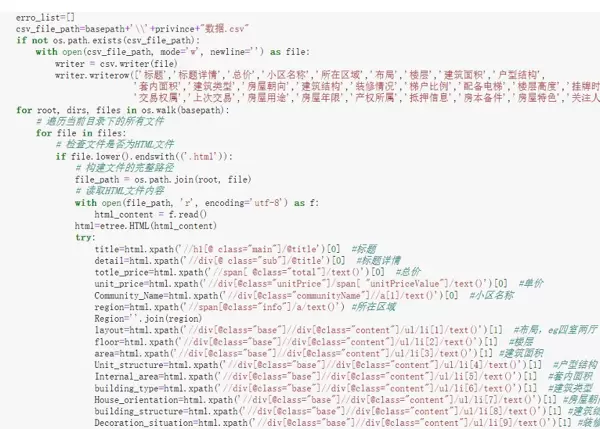
本项目的数据来源是链家网站的二手房部分,通过分析网页URL的模式,制定了按城市和区域划分的爬虫策略。首先抓取目标城市各区域的URL,然后按照分页规则遍历每个页面上的房源,最终下载单个房源的HTML文件并从中抽取所需信息。
核心爬虫代码示例:
import requests
import os
from lxml import etree
import pandas as pd
# 定义爬取函数:参数为城市URL和城市名称
def crawl_city_houses(city_url, city_name):
# 创建城市对应的存储文件夹
city_dir = f'htmls/{city_name}'
if not os.path.exists(city_dir):
os.makedirs(city_dir)
# 请求城市首页,获取各区链接
response = requests.get(city_url, headers=headers)
html = etree.HTML(response.text)
area_urls = html.xpath('//div[@data-role="ershoufang"]//a/@href')
area_names = html.xpath('//div[@data-role="ershoufang"]//a/text()')
# 遍历各区,爬取分页数据
for area_url, area_name in zip(area_urls, area_names):
area_dir = f'{city_dir}/{area_name}'
if not os.path.exists(area_dir):
os.makedirs(area_dir)爬取流程与代码示意图:
数据清洗
由于三个城市的原始数据采用了相同的提取逻辑,因此清洗流程相同。以下是针对赣州数据的核心步骤说明:
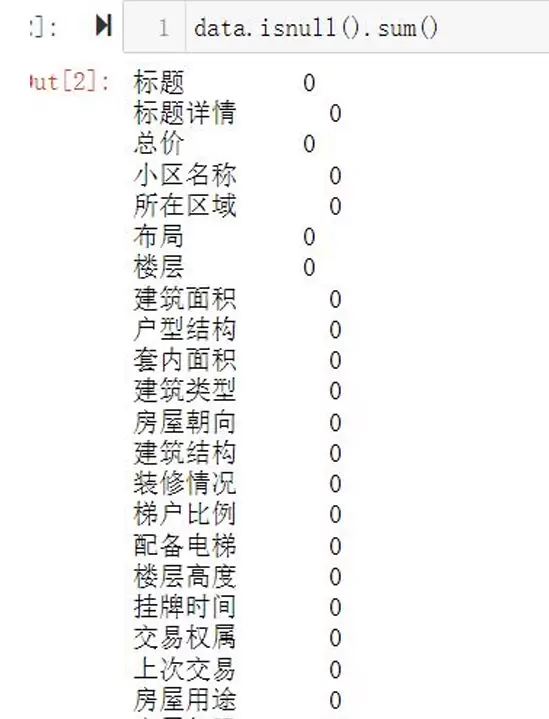
加载数据并检查基本信息:

处理缺失值:对于房屋特点等描述性字段,用“无”填充;数值型字段则根据其分布特征填充平均值或中位数。
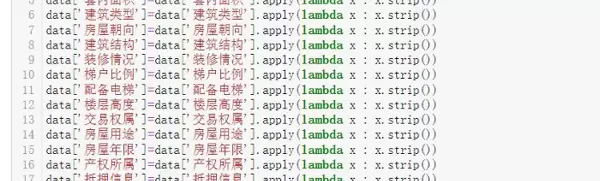
优化数据格式:移除字符串中的空格和换行符,移除冗余字段(例如,“所在区域”字段因为已经有了“所在市”和“所在县区”字段可以被移除)。

特征分解与提取:
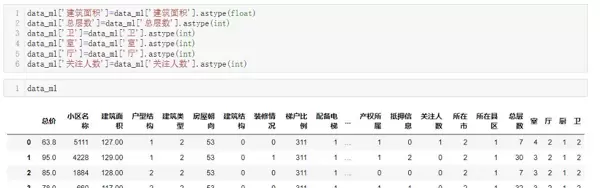
从“面积”字段中提取数字,并转换为浮点数以便建模。
将“楼层”字段拆分成“楼层高度”(低/中/高)和“总楼层数”两个独立特征。
从“户型”字段中提取“室、厅、厨、卫”的数量,并转换为整数特征。
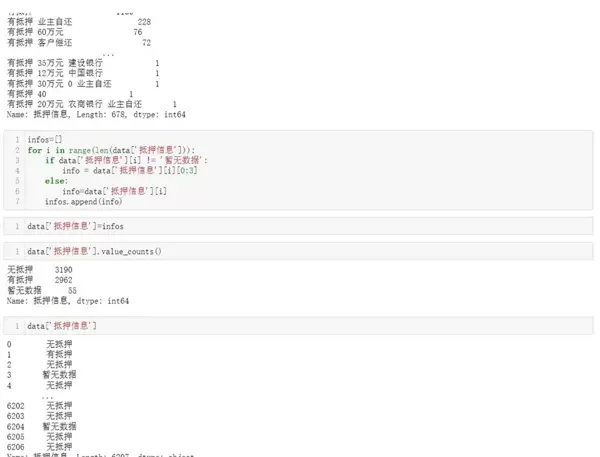
简化“抵押信息”字段,分类为“有抵押、无抵押、暂无数据”三类。
探索式数据分析
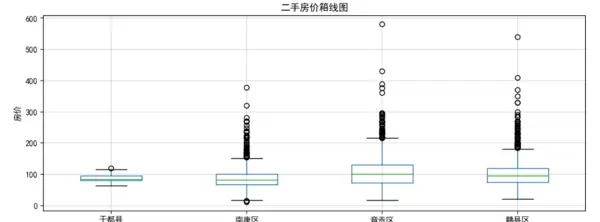
利用可视化工具从多个角度分析数据,包括区域分布、价格特征和房源属性等。以下是三个城市的主要分析成果:
赣州数据可视化
各县区房源数量分布:显示了不同区域的房源交易活跃度。

房源相关特征分布:展示了房屋特性的整体情况,为后续的特征选择提供了依据。
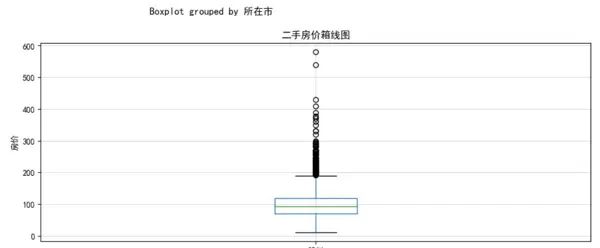
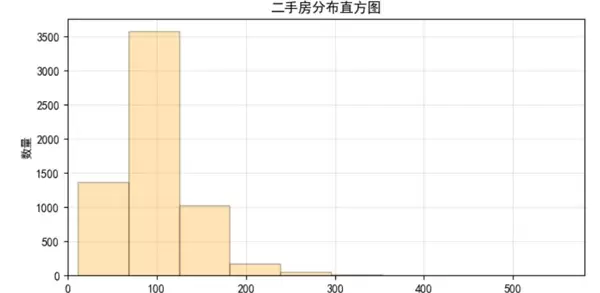
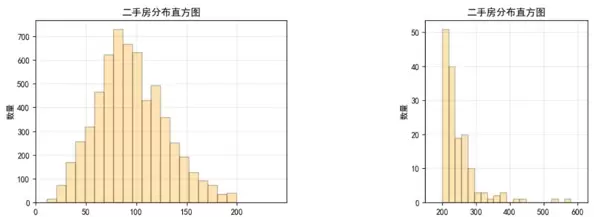
房价分布直方图:鉴于高价房源比例极低,以1000万元为界限分开展示高低价房源,以便更清晰地看到价格的集中区间。
房源标题词云图:提炼出市场上流行的宣传关键词,反映了购房者的关注重点。词云图的生成代码如下所示。



相关文章

Python电影票房预测模型研究——贝叶斯岭回归Ridge、决策树、Adaboost、KNN分析猫眼豆瓣数据
原文链接:https://tecdat.cn/?p=43754
多城市二手房价格预测与区域差异分析
房价地理图:直观展示价格差异
通过各县区平均房价的地理图,我们可以清晰地看到核心城区与郊区之间的房价梯度,这种可视化方式有助于直观理解区域价格差异。
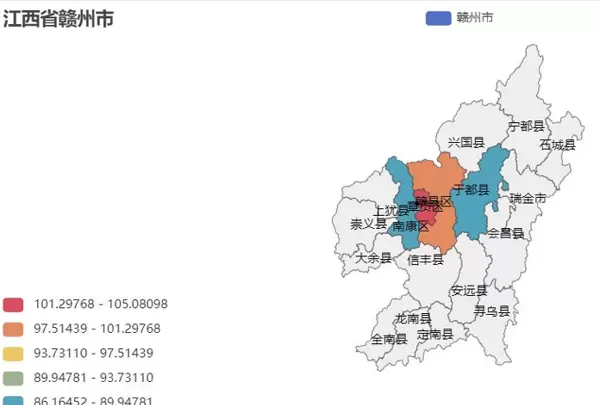
数据可视化大屏:全面展现市场概况
数据可视化大屏整合了多个核心指标,如房源数量、均价、户型分布等,旨在全方位展示市场的总体状况,为决策提供数据支持。
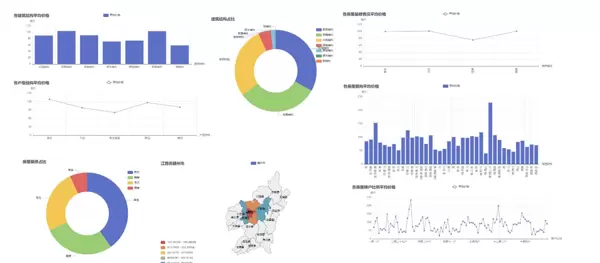
南昌市数据可视化分析
南昌市的数据可视化分析逻辑与赣州相同,但由于城市特性的不同,呈现出了不同的数据特征。以下是南昌市的核心可视化结果:
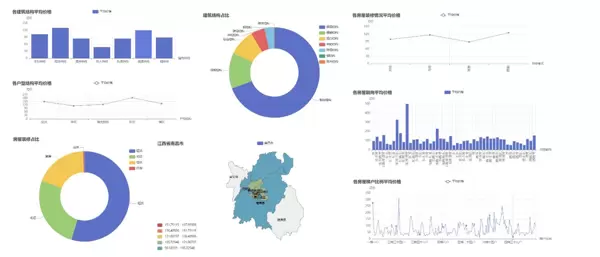
深圳市数据可视化分析
作为一线城市,深圳的房价水平和区域差异十分显著。以下展示了深圳的核心可视化结果:
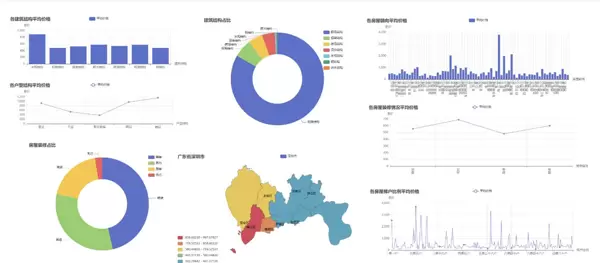
跨城市对比分析
通过对深圳、赣州、南昌三个城市的二手房市场进行对比,我们发现深圳的二手房价格显著高于其他两个城市,且异常值较多。赣州和南昌的房价分布则更为集中,主要受到核心城区与郊区地理位置的影响。此外,这三个地区的房源类型主要以满足基本需求的户型为主,装修情况普遍为简单装修和中等装修。
模型设计与优化
数据合并与特征处理
为了构建有效的预测模型,首先需要将来自不同城市的清洗后数据进行合并。经过处理,我们得到了包含42640条记录和31个特征的建模数据集。以下是合并过程中的一些关键代码示例:
核心合并代码(修改后关键片段):
import pandas as pd
# 读取三个城市的清洗后数据
ganzhou_data = pd.read_csv('清洗后数据/赣州_清洗后.csv', index_col=False)
nanchang_data = pd.read_csv('清洗后数据/南昌_清洗后.csv')
shenzhen_data = pd.read_csv('清洗后数据/深圳_清洗后.csv')
# 纵向合并数据
combined_data = pd.concat([ganzhou_data, nanchang_data, shenzhen_data], axis=0)
# 去重并重置索引
combined_data.drop_duplicates(inplace=True)
combined_data = combined_data.reset_index(drop=True)
# 保存合并后数据
combined_data.to_csv('./合并后数据集.csv', index=False)异常值检测与处理
在数据预处理阶段,我们通过箱线图发现了深圳存在较多的高价异常值,这些异常值可能会影响模型训练的准确性。因此,我们采用了IQR法则来处理这些异常值,具体代码如下:
核心处理代码(修改后关键片段):
# 计算四分位数
Q1 = model_data['总价'].quantile(0.25)
Q3 = model_data['总价'].quantile(0.75)
IQR = Q3 - Q1
# 定义异常值边界
upper_bound = Q3 + 3 * IQR
# 剔除异常值
optimized_data = model_data[model_data['总价'] <= upper_bound]
optimized_data.to_csv('./训练数据.csv', index=False)特征筛选与编码
在模型训练前,我们进行了特征筛选,去除了难以量化的特征(如标题、挂牌时间等),并保留了与目标变量高度相关的特征。对于分类特征(如户型结构、装修情况等),我们使用了LabelEncoder进行编码。下面是部分编码代码示例:
核心编码代码(修改后关键片段):
from sklearn.preprocessing import LabelEncoder
import joblib
# 筛选建模特征
model_data = combined_data.drop(['标题', '标题详情', '套内面积', ...], axis=1)
# 定义需要编码的分类特征
cat_features = ['小区名称', '户型结构', '建筑类型', ..., '所在县区']
label_encoders = {}
# 对分类特征进行编码
for feat in cat_features:
le = LabelEncoder()
model_data[feat] = le.fit_transform(model_data[feat])
label_encoders[feat] = le
# 保存编码器
joblib.dump(label_encoders, '模型/label_encoders.pkl')特征相关性分析
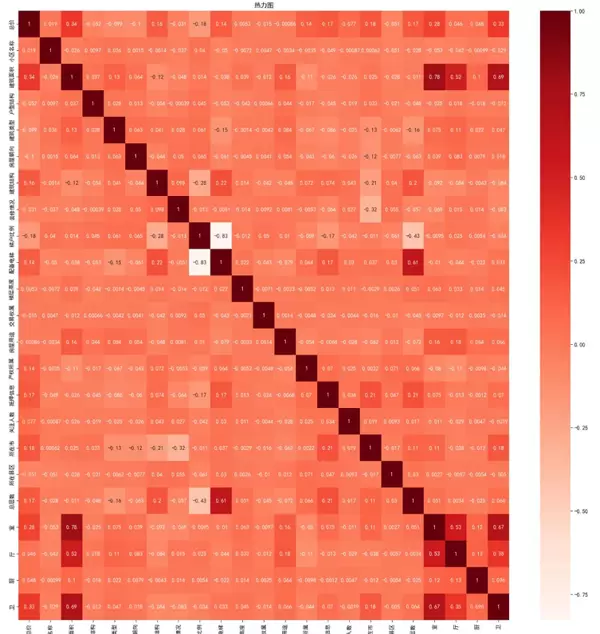
通过热力图分析,我们筛选出与“总价”相关性较高的特征,并剔除了相关性较低的特征,如小区名称、关注人数等,以优化建模特征集。
模型训练(未处理异常值)
在未处理异常值的情况下,我们使用8:2的比例划分了训练集和测试集,分别训练了决策树(DT)、梯度提升树(GBT)、随机森林(RF)三种模型,并使用R、MSE、RMSE作为评估指标。以下是各个模型的预测效果:
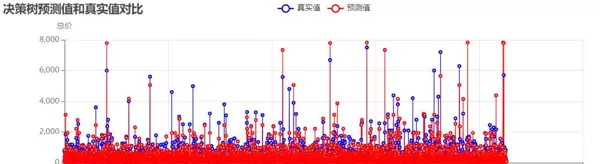
决策树模型:
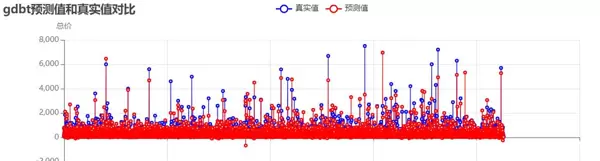
梯度提升树模型:
随机森林模型:
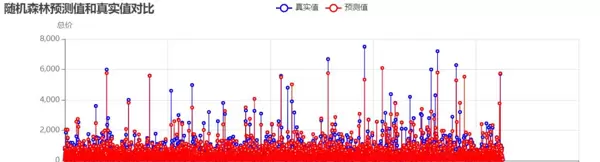
分析结果显示,未处理异常值时,模型的R值较低,尤其是在高价房源的预测上偏差较大,需要通过异常值处理和参数优化来提升模型性能。
模型优化
在异常值处理的基础上,我们使用网格搜索(GridSearchCV)为各个模型寻找最优参数,以提高模型的泛化能力。以下是优化后的模型预测效果:
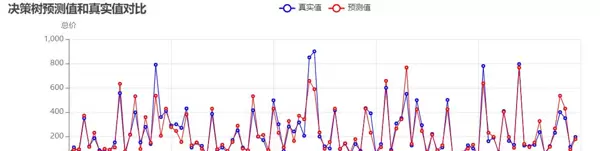
决策树模型(优化后):
梯度提升树模型(优化后):
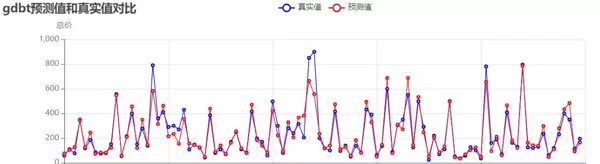
随机森林模型(优化后):
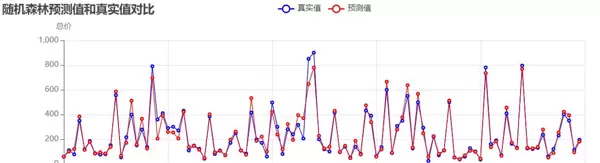
优化后的模型性能如下表所示:
| 模型 | R | MSE | RMSE |
|---|---|---|---|
| 决策树 | 0.871 | 4220.42 | 64.96 |
| 梯度提升树 | 0.895 | 3422.84 | 58.50 |
| 随机森林 | 0.911 | 2928.50 | 54.16 |
结果表明,通过剔除异常值和优化参数,三种模型的预测精度显著提升,其中随机森林模型表现最佳,R达到0.911,预测值与真实值拟合度良好,能够有效捕捉二手房价格的核心影响因素。
结论与服务支持
本研究通过完整的数据挖掘流程,实现了多城市二手房价格预测与区域差异分析,验证了决策树、梯度提升树、随机森林在房价预测场景中的有效性。核心结论包括:地理位置(所在城市、县区)、建筑面积、户型结构是影响二手房价格的关键因素;深圳房价整体偏高且波动较大,赣州、南昌房价分布较为集中;随机森林模型经过异常值处理与参数优化后,预测精度最高,可为市场参与者提供可靠的参考。
核心服务保障
- 应急修复服务:提供24小时响应的“代码运行异常”求助服务,比学生自行调试效率提升40%,避免因代码问题耽误项目进度。
- 人工创作保障:所有代码与论文内容均经过人工优化,确保代码能运行且具有原创性,解决“代码能运行但怕查重、怕漏洞”的问题。
- 全流程支持:提供从数据爬取到模型落地的全流程答疑服务,不仅教会“怎么做”,更解释“为什么这么做”,帮助真正掌握数据分析思维。
本文项目的完整代码、数据及可视化素材已同步至交流社群,进群即可获取。如需个性化修改、代码调试或润色服务,可联系团队获取一对一支持,让数据分析学习更高效、更省心。
关于分析师

在此对Liping Xiao对本文所作的贡献表示诚挚感谢。Liping Xiao的专业方向为数据科学与大数据技术,曾在北京中电中采数据服务有限公司担任数据处理工作,擅长Python编程,在深度学习、数据分析、数据采集等领域具备专业的实践能力和技术储备。

 京公网安备 11010802022788号
京公网安备 11010802022788号







