


 雷达卡
雷达卡





movie.all<-NULL #设定汇总数据框初始状态;
for (n in 0:4){ #循环提取页面信息;
movie<-NULL;
url=paste("http://movie.douban.com/top250?start=",n*50,"&filter=&format=text",sep="")
# 获取网页源代码,以行的形式存放在web变量中
web <- readLines(url,encoding="UTF-8")
# 找到包含电影名称的行编号,并据此提取行内容;
name <- web[grep('<td headers="m_name">',web)+1]
# 用正则表达式来提取电影名
gregout <- gregexpr('>\\w+',name)
getcontent <- function(s,g){
substring(s,g+1,g+attr(g,'match.length')-1) #注substing(字符串,起始位,结束位)
}
movie.names = 0
for(i in 1:length(gregout)){
movie.names<-getcontent(name,gregout[])
}
# 找到包含电影发行年份的行编号并进行提取
year <- web[grep('<span class="year">',web)]
movie.year <- substr(year,36,39)
# 找到包含电影评分的行编号并进行提取
score <- web[grep('<td headers="m_rating_score">',web)+1]
movie.score <- substr(score,21,23)
# 找到包含电影评价数量的行编号并进行提取
rating <- web[grep('<td headers="m_rating_num">',web)+1]
movie.rating <- sub(' *','',rating)
movie<- data.frame(names=movie.names,year=as.numeric(movie.year),
score=as.numeric(movie.score),rate=as.numeric(movie.rating)) #将每页数据整合到一个临时数据框中;
movie.all<-rbind(movie.all,movie) #将多页数据整合到一个数据框中;
}
复制代码
整合好的250部电影的数据存放在movie.all数据框中,结果为:
str(movie.all)
'data.frame': 250 obs. of 4 variables:
$ names: Factor w/ 249 levels "阿凡达","阿甘正传",..: 43 46 2 3 10 16 26 35 44 12 ...
$ year : num 1994 1994 1994 1993 2010 ...
$ score: num 9.5 9.4 9.3 9.4 9.2 9.1 9.4 9.1 9.3 9.1 ...
$ rate : num 475026 449389 408079 316811 4546现在我们就可以进行数据分析了。
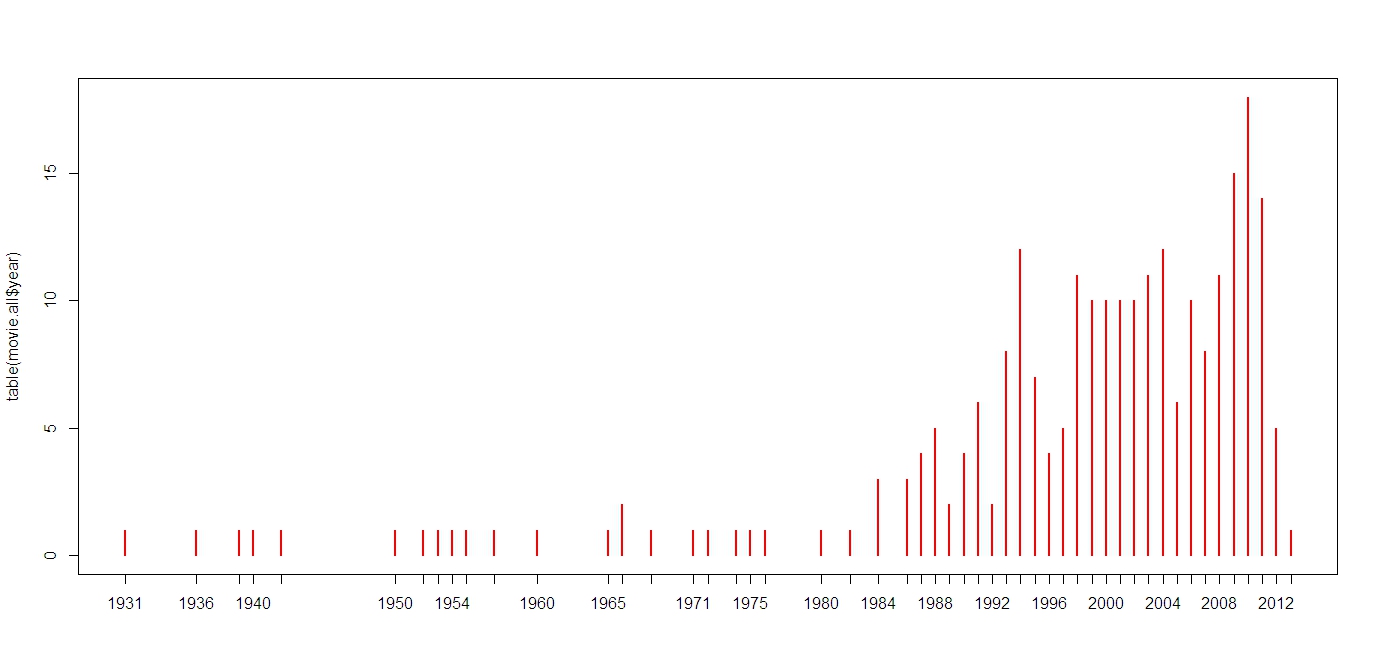
(1)目前评分最高的这250部电影的时间分布:
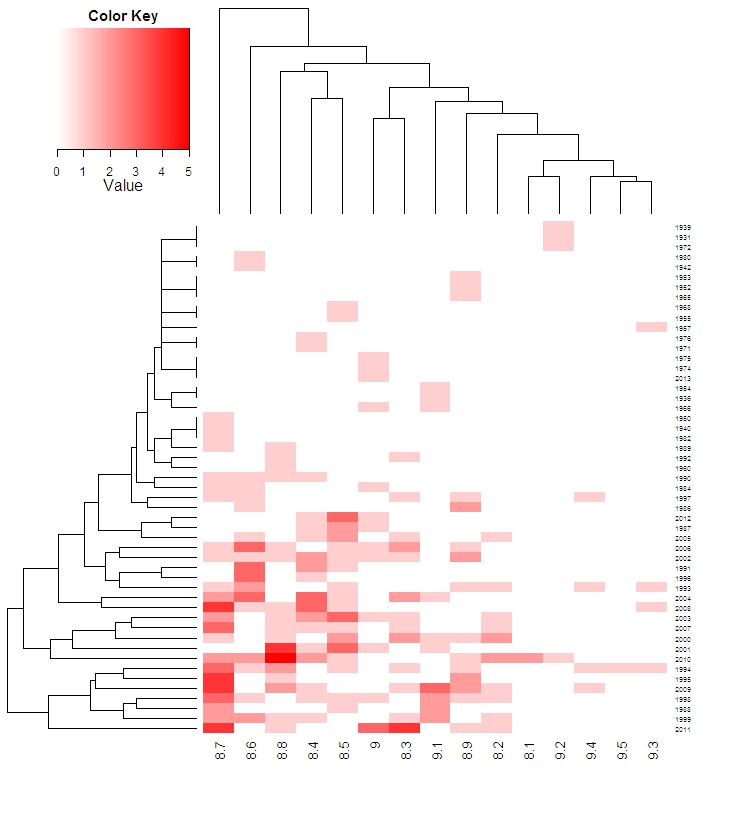
(2)时间+评分分布情况(热力图)
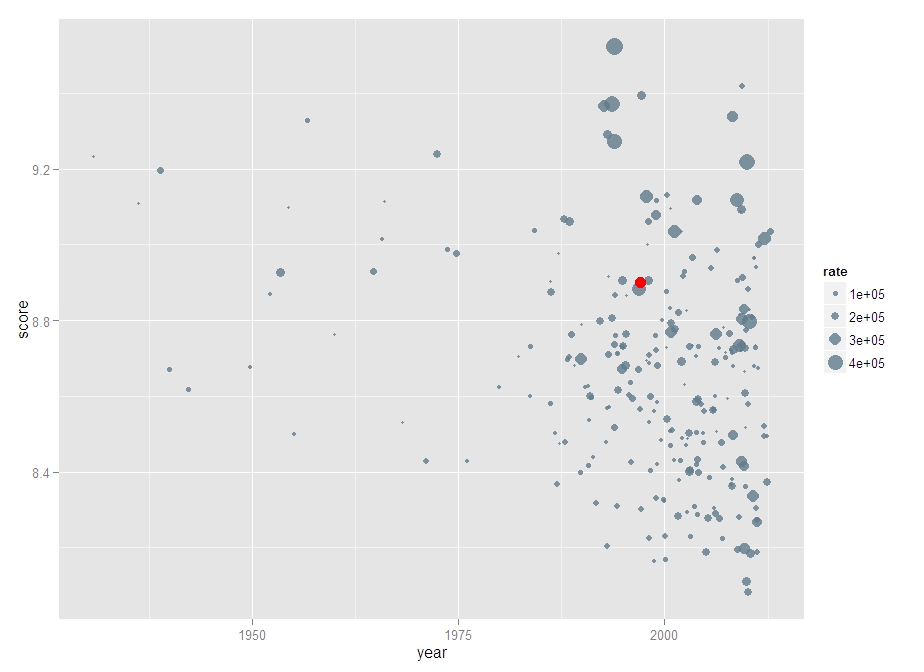
(3)时间+评分+评分人数情况(气泡图)




 京公网安备 11010802022788号
京公网安备 11010802022788号







