



 雷达卡
雷达卡



这篇文章介绍用线性模型处理回归问题。从简单问题开始,先处理一个响应变量和一个解释变量的一元问题。然后,介绍多元线性回归问题(multiple linear regression),线性约束由多个解释变量构成。紧接着,介绍多项式回归分析(polynomial regression问题),一种具有非线性关系的多元线性回归问题。最后,介绍如果训练模型获取目标函数最小化的参数值。在研究一个大数据集问题之前,先从一个小问题开始学习建立模型和学习算法。
一元线性回归
假设你想计算匹萨的价格。虽然看看菜单就知道了,不过也可以用机器学习方法建一个线性回归模型,通过分析匹萨的直径与价格的数据的线性关系,来预测任意直径匹萨的价格。先用scikitlearn写出回归模型,然后介绍模型的用法,以及将模型应用到具体问题中。假设我们查到了部分匹萨的直径与价格的数据,这就构成了训练数据,如下表所示:
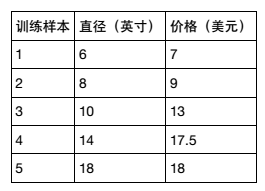
可以用matplotlib画出图形:
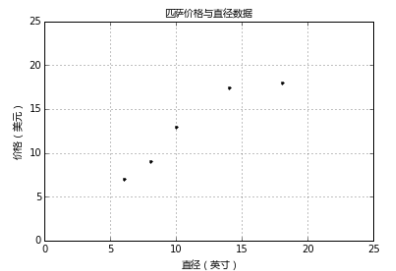
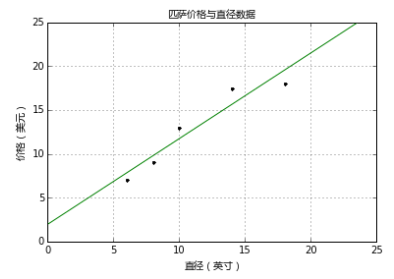
上图中,'x'轴表示匹萨直径,'y'轴表示匹萨价格。能够看出,匹萨价格与其直径正相关,这与我们的日常经验也比较吻合,自然是越大越贵。下面就用scikit-learn来构建模。

预测一张12英寸匹萨价格:$13.68。
一元线性回归假设解释变量和响应变量之间存在线性关系;这个线性模型所构成的空间是一个超平面(hyperplane)。超平面是n维欧氏空间中余维度等于一的线性子空间,如平面中的直线、空间中的平面等,总比包含它的空间少一维。在一元线性回归中,一个维度是响应变量,另一个维度是解释变量,总共两维。因此,其超平面只有一维,就是一条线。
上述代码中sklearn.linear_model.LinearRegression类是一个估计器(estimator)。估计器依据观测值来预测结果。在scikit-learn里面,所有的估计器都带有fit()和predict()方法。fit()用来分析模型参数,predict()是通过fit()算出的模型参数构成的模型,对解释变量进行预测获得的值。因为所有的估计器都有这两种方法,所有scikit-learn很容易实验不同的模型。LinearRegression类的fit()方法学习下面的一元线性回归模型:
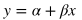
y表示响应变量的预测值,本例指匹萨价格预测值, 是解释变量,本例指匹萨直径。截距和相关系数 是线性回归模型最关心的事情.下图中的直线就是匹萨直径与价格的线性关系。用这个模型,可以计算不同直径的价格,8英寸$7.33,20英寸$18.75。

一元线性回归拟合模型的参数估计常用方法是普通最小二乘法(ordinary least squares )或线性最小二乘法(linear least squares)。首先,我们定义出拟合成本函数,然后对参数进行数理统计。
带成本函数的模型拟合评估
下图是由若干参数生成的回归直线。如何判断哪一条直线才是最佳拟合呢?

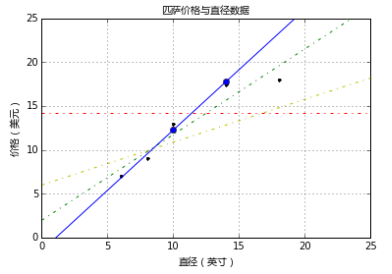
成本函数(cost function)也叫损失函数(loss function),用来定义模型与观测值的误差。模型预测的价格与训练集数据的差异称为残差(residuals)或训练误差(training errors)。后面会用模型计算测试集,那时模型预测的价格与测试集数据的差异称为预测误差(prediction errors)或训练误差(test errors)。
模型的残差是训练样本点与线性回归模型的纵向距离,如下图所示:

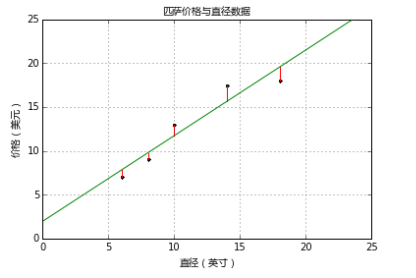
我们可以通过残差之和最小化实现最佳拟合,也就是说模型预测的值与训练集的数据最接近就是最佳拟合。对模型的拟合度进行评估的函数称为残差平方和(residual sum of squares)成本函数。就是让所有训练数据与模型的残差的平方之和最小化,如下所示:
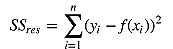
其中, 是观测值, 是预测值。残差平方和计算如下:
![]()
解一元线性回归的最小二乘法
通过成本函数最小化获得参数,先求相关系数贝塔。按照频率论的观点,首先需要计算x的方差和x与y的协方差。
方差是用来衡量样本分散程度的。如果样本全部相等,那么方差为0。方差越小,表示样本越集中,反正则样本越分散。方差计算公式如下:
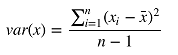

Numpy里面有var方法可以直接计算方差,ddof参数是贝塞尔(无偏估计)校正系数(Bessel'scorrection),设置为1,可得样本方差无偏估计量。
![]()
协方差表示两个变量的总体的变化趋势。如果两个变量的变化趋势一致,也就是说如果其中一个大于自身的期望值,另外一个也大于自身的期望值,那么两个变量之间的协方差就是正值。 如果两个变量的变化趋势相反,即其中一个大于自身的期望值,另外一个却小于自身的期望值,那么两个变量之间的协方差就是负值。如果两个变量不相关,则协方差为0,变量线性无关不表示一定没有其他相关
性。协方差公式如下:
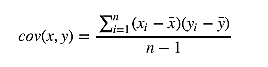

现在有了方差和协方差,就可以计算相关系统贝塔了。
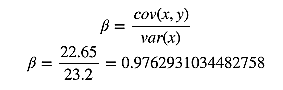
算出贝塔后,就可以计算阿尔法了:
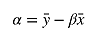
将前面的数据带入公式就可以求出阿尔法了:
α = 12.9 − 0.9762931034482758 × 11.2 = 1.9655172413793114
这样就通过最小化成本函数求出模型参数了。把匹萨直径带入方程就可以求出对应的价格了,如11英寸直径价格$12.70,18英寸直径价格$19.54。
模型评估
前面用学习算法对训练集进行估计,得出了模型的参数。如何评价模型在现实中的表现呢?现在假设有另一组数据,作为测试集进行评估。
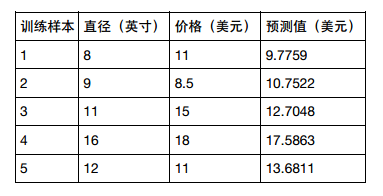
有些度量方法可以用来评估预测效果,我们用R方(r-squared)评估匹萨价格预测的效果。R方也叫确定系数(coefficient of determination),表示模型对现实数据拟合的程度。计算R方的方法有几种。一元线性回归中R方等于皮尔逊积矩相关系数(Pearson product moment correlation coefficient或Pearson's r)的平方。
这种方法计算的R方一定介于0~1之间的正数。其他计算方法,包括scikit-learn中的方法,不是用皮尔逊积矩相关系数的平方计算的,因此当模型拟合效果很差的时候R方会是负值。下面用scikitlearn方法来计算R方。

=56.8
然后,计算残差平方和,和前面的一样:
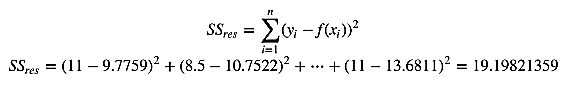
最后用下面的公式计算R方:
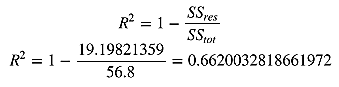
R方是0.6620说明测试集里面过半数的价格都可以通过模型解释。现在,用scikit-learn来验证一下。LinearRegression的score方法可以计算R方:

转载:宽客在线
 提升卡
提升卡 置顶卡
置顶卡 沉默卡
沉默卡 变色卡
变色卡 抢沙发
抢沙发 千斤顶
千斤顶 显身卡
显身卡


 京公网安备 11010802022788号
京公网安备 11010802022788号







