
关于本站
人大经济论坛-经管之家:分享大学、考研、论文、会计、留学、数据、经济学、金融学、管理学、统计学、博弈论、统计年鉴、行业分析包括等相关资源。
经管之家是国内活跃的在线教育咨询平台!
CDA数据分析师证书
谁适合考CDA证书?年龄18-40周岁,专业是计算机、工商管理、统计学、管理科学类,学历本科及以上,行业是金融、信息技术、电信等,岗位是数据、产品、运营等。
期刊
- 期刊库 | 马上cssci就要更新 ...
- 期刊库 | 【独家发布】《财 ...
- 期刊库 | 【独家发布】“我 ...
- 期刊库 | 【独家发布】“我 ...
- 期刊库 | 【独家发布】国家 ...
- 期刊库 | 请问Management S ...
- 期刊库 | 英文期刊库
- 核心期刊 | 歧路彷徨:核心期 ...
TOP热门关键词
免费学术公开课,扫码加入 |
Stata绘图(二) | 多期DID的平行趋势检验
作者:石器时代的大菠萝
多期DID的平行趋势检验有两种等价的展示方法,一是回归法,二是绘图法,前者相对容易,而后者的操作过程稍复杂。不少人借鉴了Beck et al.(2010)的做法,但该文实际用的模型是渐进DID,即最终所有个体均实施了政策,因此相关命令需要经过一定修改才能用于一般的多期DID。本文的前半部分将会简单介绍多期DID,后半部分将会参考Beck et al.(2010)对图片的设定提供一个绘图过程。
多期DID简介
两期DID:Yit=常数+Dt+Gi+ Dt* Gi+ eit
——Stata命令:reg y D G D_G 其他控制变量
注:D_G是D与G的交互项
多期DID:Yit=常数+Xit+时间虚拟变量+ ui+ eit
——Stata命令:xtreg y x i.time 其他控制变量,fe
其中,Yit是被解释变量;Dt表示政策后虚拟变量(取1表示政策之后,取0则表示政策之前);Gi表示处理变量(取1表示处理组,取0则表示控制组);Xit表示“个体i为处理组”且“时间t在政策之后”则取值为1,其他情况取值为0,有一种等价说法是——Xit表示个体i在t时间是否实施了政策。
请注意:不要把Xit理解成是交互项,因为在多期DID中,控制组样本的Dt无法给出合适的定义。简单来说,控制组样本根本不存在“政策年度”一说,更谈不上样本是发生在政策“之前”还是“之后”了。
Dt表示政策实施前后的虚拟变量,在两期DID中,因为只存在两期数据,因此其等价于时间虚拟变量。两期DID的Dt到了多期DID中,就转化为时间虚拟变量;Gi表示处理变量,由于多期DID中的个体效应ui包含了Gi的信息(Gi是ui的子集),因此同时在模型中放入Gi与ui将导致严重的多重共线性问题,应该只放入信息含量更多的ui。多期DID中的Xit来自两期DID中的Dt* Gi,尽管本文一再强调不应该把Xit理解成Dt与Gi的乘积,但是不少初学者依然会习惯性认为Xit等价于两个变量的乘积。
综上,两期DID推导至多期DID的变化过程是:Dt→时间虚拟变量,Gi→ui,Dt*Gi→Xit。多期DID没有对政策时点是否一致性提出要求,因此多期DID还适用于政策时点不一致情形。
生成Xit的Stata过程对初学者来说可能稍有难度,有的人习惯在Excel中整理数据,有的人喜欢用merge命令把数据全部匹配到一起。由于不同人有不同的习惯,下面介绍如何在Excel和Stata中应该怎么制作出这个变量。
第一种做法:使用Excel来制作Xit是非常直观的。
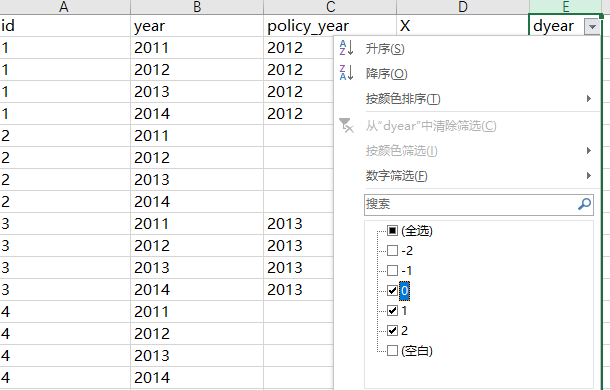
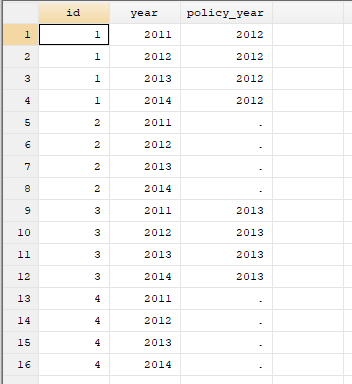
第一步,你需要为数据添加一列policy_year,对于控制组样本应该设定为空白值,X就是最终要生成的变量。例子中一共有16个样本。
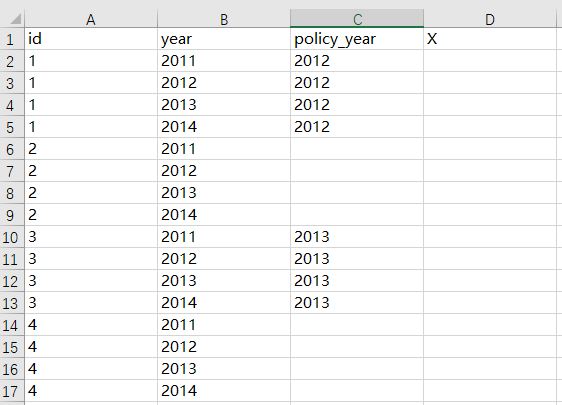
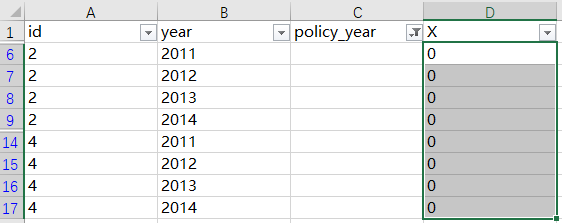
第二步,从16个样本中,筛选出policy_year为空白值的样本,然后对这些样本的X全部赋值为0。满足条件的一共有8个。
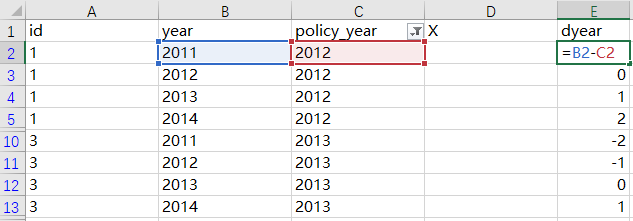
第三步,从16个样本中,筛选出policy_year有取值的样本(一共8个样本),新变量dyear是用year减去policy_year。
第四步,从16个样本中,筛选出dyear≥0的样本(一共5个样本),然后对这些样本的X赋值为1。
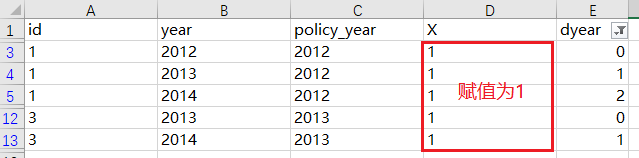
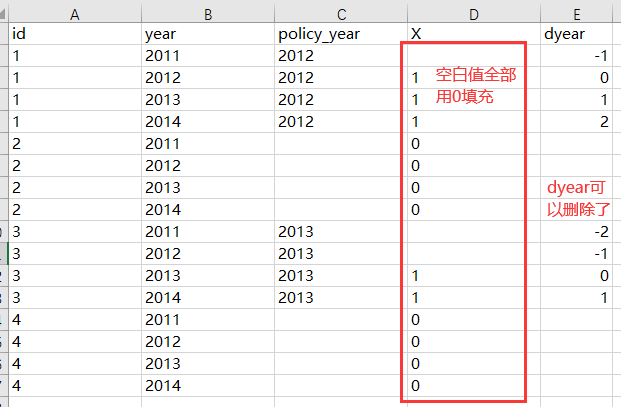
第五步,取消筛选功能后,你可以在X中发现仍有空白值(3个),用0填充他们,最后再把dyear删除,X就生成完毕了。
 )
)
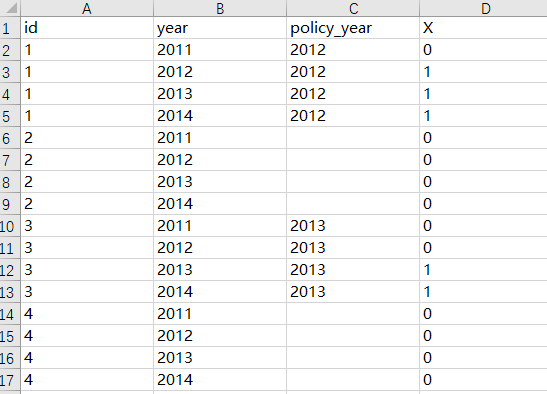
第二种做法:使用Stata来生成x,过程相对简单,如果不想一步步操作Excel可以考虑这种做法。
第一步,数据导入Stata。
第二步,输入命令:
gen x=0
replace x=1 if year>= policy_year
*平行趋势检验还需要生成处理变量treat(处理组取1,控制组取0)。
*这个变量在Excel中非常容易生成,因此方法一不详细介绍生成过程。
gen treat=0
replace treat=1 if policy_year!=.
多期DID的Stata命令
xtreg y x i.time 其他控制变量,fe r
提示:推荐使用聚类稳健标准误进行回归,也就是加上“r”,但是这么做或许会降低系数的显著性。为什么会这样呢?这个问题与t检验的自由度有关,本帖不展开讨论这个技术细节。如果你在多期DID的回归使用了聚类稳健标准误,那么在平行趋势检验中,你应该继续使用聚类稳健标准误,从而做到前后一致。请不要低估考虑“是否使用聚类稳健标准误”的意义,它不但影响系数的显著性,还可能影响绘图策略。
平行趋势检验的Stata命令——回归法
*变量说明:y表示被解释变量,id表示样本个体;year表示样本年份;policy_year表示政策发生年份;
*treat取1表示处理组,取0表示控制组。
set more off
xtset id year
gen distance = year - policy_year
*了解数据情况。
tab distance, missing
*请确认distance变量是否存在以下两类问题:
*1.样本稀疏的问题,即样本个数在某些年份非常少。2.distance的取值范围太宽,检验太多期的平行趋势可能是没有必要的。
*你可以采用“缩尾处理策略”以应对上面两种问题:
*replace distance = -4 if distance < -4
*replace distance = 5 if distance > 5
*生成一系列的变量:
*d_j的数学含义是:若样本是”处理组“且为”政策实施前的第j期“则取值为1,其他情况取值为0。
*dj的数学含义是:若样本是”处理组“且为”政策实施后的第j期“则取值为1,其他情况取值为0。
*current的数学含义是:若样本是”处理组“且为”政策实施当期“则取值为1,其他情况取值为0。
*例如,某个个体的政策实施于2013年,那么该个体在2012年的变量D_1取值为1,其余均为0。
尽管上面给出的数学定义是十分清晰的,但为了照顾初学者,下面给出一个直观的数据描述。以d_1为例,若样本是”处理组“且为”政策实施前的第1期“(distance=-1)则取值为1(橘色区域所示),其余情况取值为0。
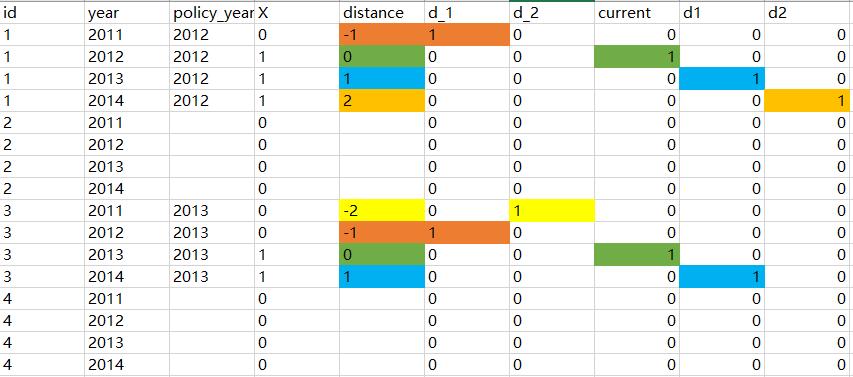
*第一步,生成变量d_j、dj、current。
*(1)生成d_j,假设你在“tab distance, missing”中发现,distance最小值是-4,那么生成过程如下:
forvalues i=1/4 {
gen d_`i' = 0
replace d_`i' = 1 if treat== 1 & distance== -`i'
}
*(2)生成dj,假设你在“tab distance, missing”中发现,distance最大值是5,那么生成过程如下:
forvalues i=1/5 {
gen d`i' = 0
replace d`i' = 1 if treat== 1 & distance== `i'
}
*(3)生成current。
gen current = 0
replace current = 1 if treat== 1 & distance== 0
*回归法进行平行趋势检验:
xtreg y d_4 d_3 d_2 d_1 d1 d2 d3 d4 d5 i.year 控制变量, fe r
*判别方法:若d_4 d_3 d_2 d_1均不显著,则表明平行趋势假设成立。
你可能已经注意到了,current不被包含在回归模型中,尽管我们生成了它。原因是d_j、dj、current无法同时被放进模型,否则会产生严格多重共线性问题,Stata会自动在“d_4 d_3 d_2 d_1 current d1 d2 d3 d4 d5”中随机drop掉一个变量(哪个被drop掉与顺序有关)。为了进行平行趋势检验,我们应该在d_j与current中选择一个变量并手动去掉。如果你发现检验结果不理想,可以尝试调整drop对象。被drop掉的那个变量,我们称之为基期。 若d_j的回归系数是不显著的,说明d_j的系数与基期没有显著差异,从而支持了平行趋势假设。本文的例子是以current为基期,如果你希望改变基期的位置,我在49楼写了一个以d_1为基期的代码示例。
尽管有些人还认为,可以在dj中选择一个变量去掉,但严格意义上这是不合适的。若所有d_j系数均不显著倒也无妨,同样可以说明平行趋势假定成立,但如果所有d_j的系数均显著为正(或负),那么我们无从判断d_j中任意两个回归系数是否有显著差异。另外,偶尔也会见到一些不规范的做法,比如在不采取“缩尾处理策略”情况下(前文对此策略已经用例子介绍了),只对current附近几期进行平行趋势检验,这种情况下,如果你得到了一些显著的d_j,你可能会误以为平行趋势检验没有通过。总之,基期的选择对平行趋势检验的结果是有影响的,请不要忽略这个问题。基于上述观点,tvdiff这个专门用来进行平行趋势检验的命令,由于不允许指定基期,因此价值可能有限。
平行趋势检验的Stata命令——绘图法
平行趋势检验的绘图法需要你先完成回归法的所有步骤,也就是在执行下面这条命令之后,才可以进行绘图法。下面这个回归的结果,已经可以用来判断检验是否通过了。若检验没有通过,绘图法也就没必要做了。
xtreg y d_4 d_3 d_2 d_1 d1 d2 d3 d4 d5 i.year 控制变量, fe r
如果你认为以下内容有一定操作难度,那么你可以考虑放弃用绘图法来展示平行趋势检验的结果。正如前文所述,绘图法与回归法是等价的,绘图法对论文的意义只是“锦上添花”。
方法1:采用coefplot绘制简易图形
ssc install coefplot
coefplot,keep( d_4 d_3 d_2 d_1 d1 d2 d3 d4 d5 ) levels(90) vertical lcolor(black) mcolor(black) msymbol(circle_hollow) ytitle(回归系数, size(small)) ylabel(, labsize(small) angle(horizontal) nogrid) yline(0, lwidth(vthin)lpattern(solid) lcolor(black)) xtitle(政策实施相对时间, size(small)) xlabel(,labsize(small)) graphregion(fcolor(white) lcolor(white) ifcolor(white) ilcolor(white)) ciopts(recast(rcap)) xline(10.5, lwidth(vthin) lpattern(solid)lcolor(black))
Stata15会出现字体问题;如果你是Stata14,字体会默认为宋体,因此推荐用Stata14来作图。
本文使用Beck et al.(2010)提供的数据,参照上面的命令可以得到的图片大致如下,部分地方仍需要进一步手工调整。
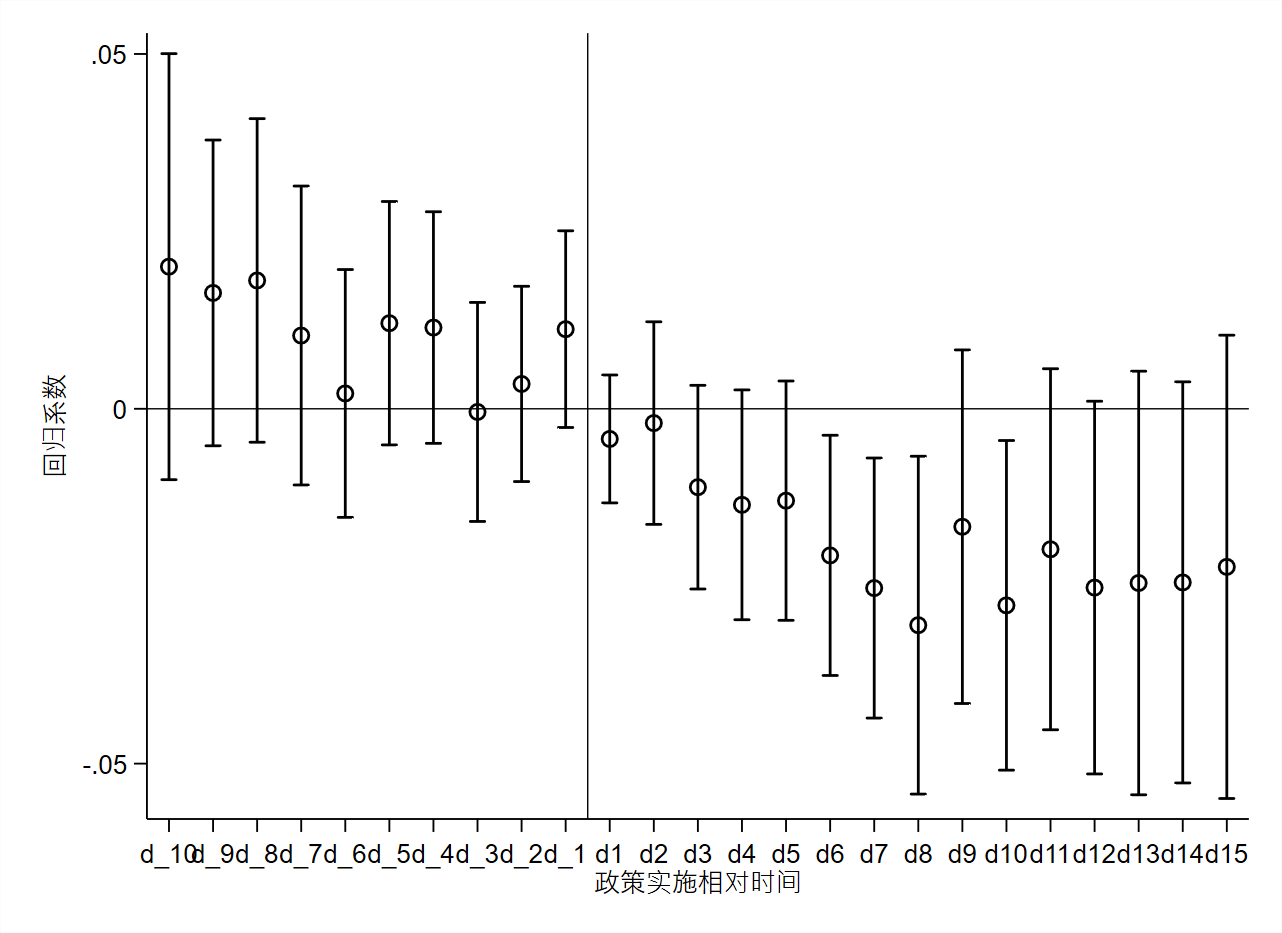
例如,调整x轴和y轴的标签。
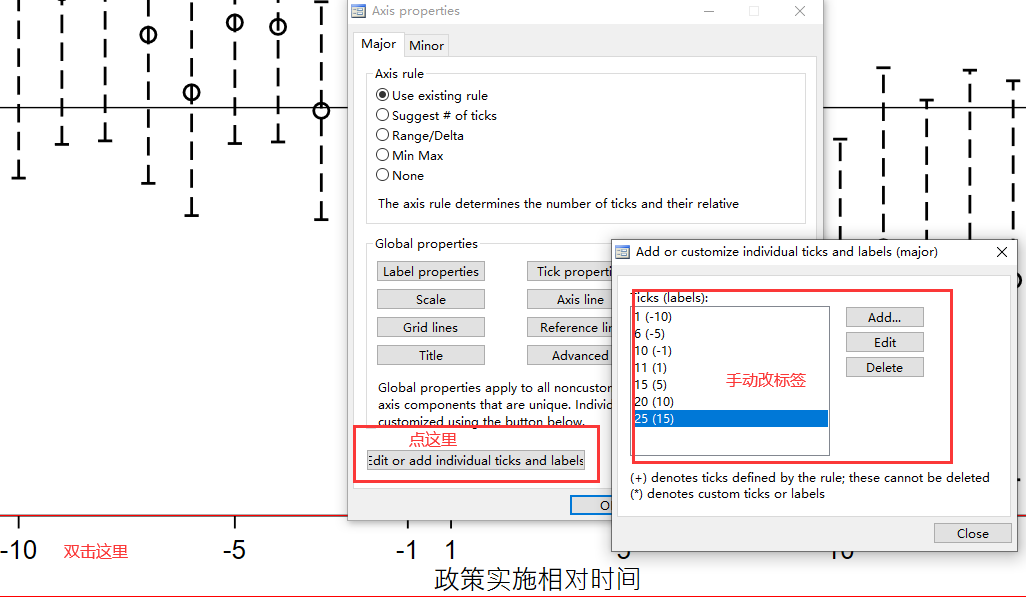
此处展示一个简单调整以后的图:
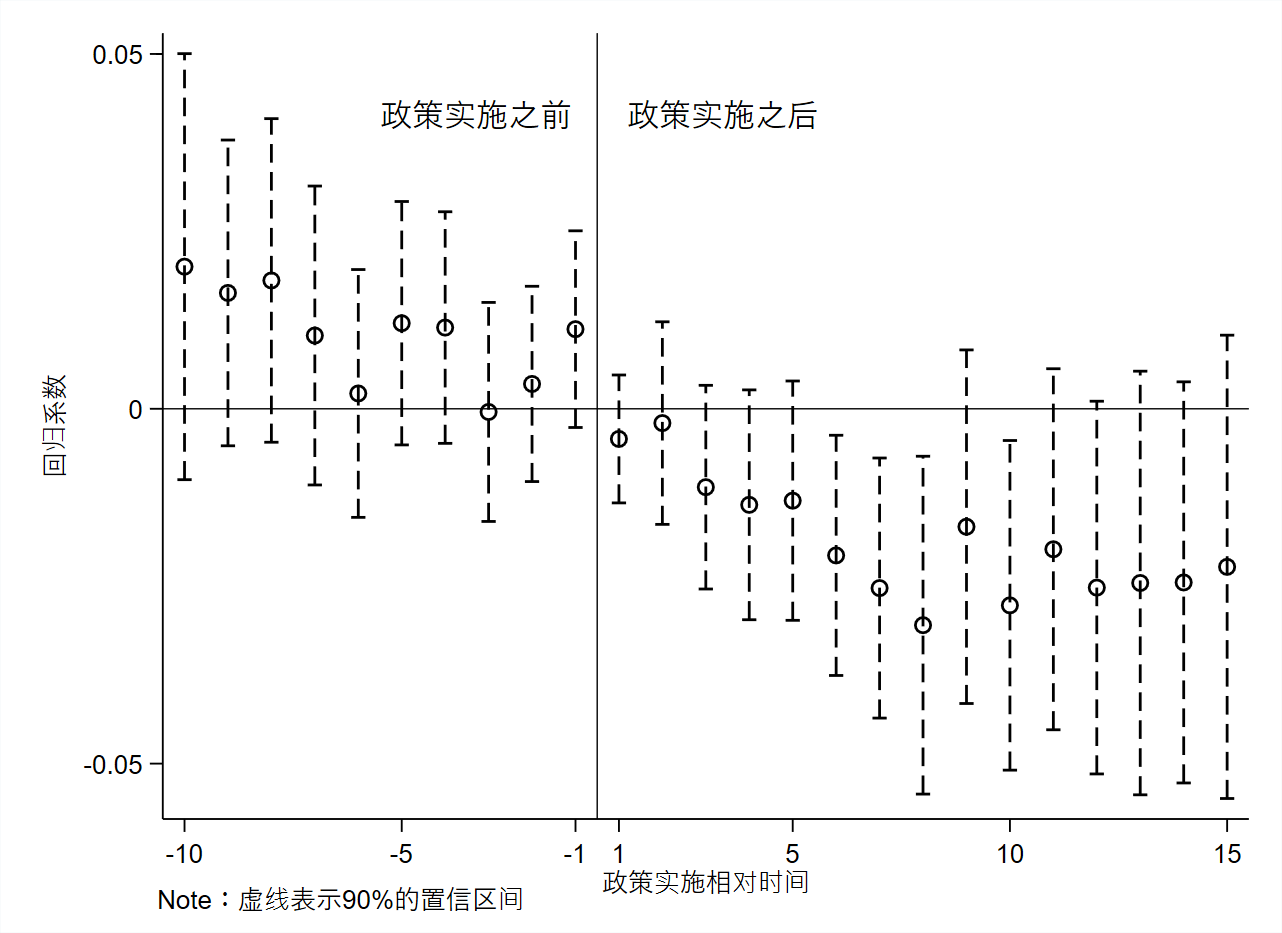
上面这个图有个缺陷,就是无法在基期(current)的位置形成一个断点,优点是过程简单方便。一个可行的替代方案是,你可以将基期设定在最开头(即d_4),即回归模型设置为:
xtreg y d_3 d_2 d_1 current d1 d2 d3 d4 d5 i.year 控制变量, fe r
方法2:命令直接绘图(非常推荐)
第一步:手工计算置信区间
首先考虑置信区间是如何被计算出来的。
为计算90%置信区间,需要计算t统计量,最精确的命令是:gen t = invttail ( d2 , 0.05 )
其中,参数d2是F统计量的第二个自由度,可以从前文的xtreg回归中获得这个数字。


gen t = invttail ( 48 , 0.05 )
*生成b_j的系数与置信区间(假设有4期,即distance最小值是-4;你可以手动调整下面命令的参数)
forvalues i=1/4 {
gen b_`i' = _b[d_`i']
gen se_b_`i' = _se[d_`i']
gen b_`i'LB = b_`i' - t * se_b_`i'
gen b_`i'UB = b_`i' + t * se_b_`i'
}
*生成bj的系数与置信区间(假设有5期,即distance最大值是5)
forvalues i=1/5 {
gen b`i' = _b[d`i']
gen se_b`i' = _se[d`i']
gen b`i'LB = b`i' - t * se_b`i'
gen b`i'UB = b`i' + t * se_b`i'
}
第二步:将上述计算结果集中反映在三个变量中
gen b = .
gen LB = .
gen UB = .
*生成系数(政策前)
forvalues i=1/4 {
replace b = b_`i' if distance == -`i'
}
*生成系数(政策后)
forvalues i=1/5{
replace b = b`i' if distance == `i'
}
*生成系数置信区间下限(政策前)
forvalues i=1/4 {
replace LB = b_`i'LB if distance == -`i'
}
*生成系数置信区间下限(政策后)
forvalues i=1/5 {
replace LB = b`i'LB if distance == `i'
}
*生成系数置信区间上限(政策前)
forvalues i=1/4 {
replace UB = b_`i'UB if distance == -`i'
}
*生成系数置信区间上限(政策后)
forvalues i=1/5 {
replace UB = b`i'UB if distance == `i'
}
第三步:删除重复值与无用的变量
绘图不会用到那么多变量与样本,只需要保留关键数据即可。
keep distance b LB UB
duplicates drop distance,force
sort distance
第四步:绘制图片
下面是绘图命令,与coefplot一样,即使有了绘图设定,很多地方还是需要你手动调整。如果你了解graph editor,非常推荐直接在editor中对图片进行加工。
twoway (connected b distance, sort lcolor(black) mcolor(black) msymbol(circle_hollow) cmissing(n))(rcap LB UB distance, lcolor(black)lpattern(dash) msize(medium)),ytitle(Percentage change) ytitle(, size(small)) yline(0, lwidth(vthin) lpattern(dash) lcolor(teal)) ylabel(, labsize(small) angle(horizontal) nogrid) xtitle(Years relative to branch deregulation) xtitle(, size(small)) xline(0, lwidth(vthin) lpattern(dash) lcolor(teal)) xlabel(-2(1)2, labsize(small)) xmtick(-2(1)2, nolabels ticks)legend(off)graphregion(fcolor(white) lcolor(white) ifcolor(white) ilcolor(white))
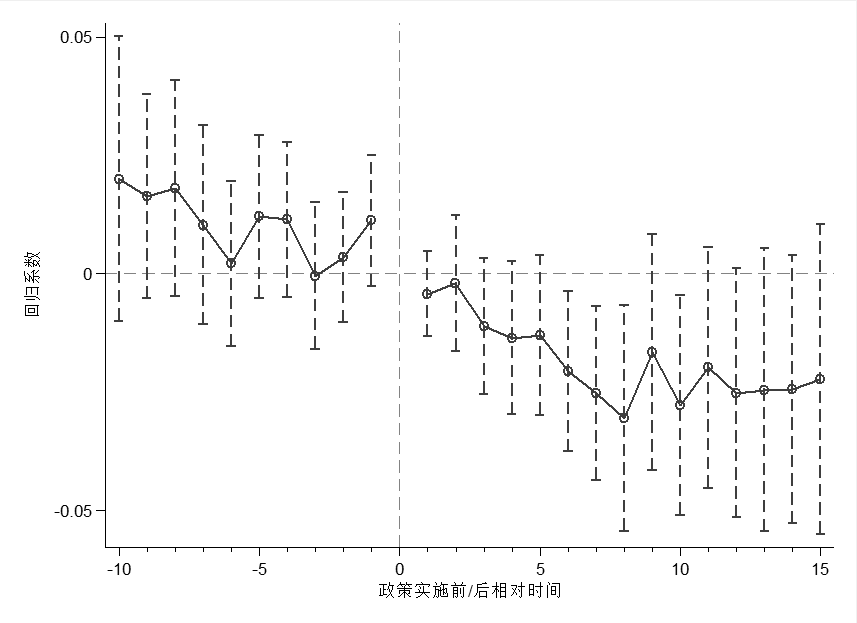
优点是图片美观,基期位置生成了一个断点,这是coefplot无法做到的。最重要的是,这种方法允许你以任意d_j为基期,并且也允许你相应位置形成断点(本帖没有给如何在d_j位置形成断点的方法)。缺点是整个绘图过程比较麻烦。
当政策时点一致时,不少论文选择用两期DID的设定(即Dt、Gi、DtGi)来回归多期数据,这是一种不合适的处理方法。如果你用的命令是reg,那么信息多的ui就会被信息少的Gi取代,内生性问题可能很严重;如果你用的命令是xtreg-,fe,那么Gi的系数将会无法被固定效应模型估计出系数,因为Gi通常不随时间改变,所以不少求助帖子会问分组变量Gi的系数为什么ommited了。一种不好的做法可能是这样的,以reg Dt、Gi、DtGi i.year对多期数据进行回归,模型中还额外控制了时间虚拟变量。正如前文所述,Dt与时间虚拟变量存在很强的联系,因此如果同时在模型中放入两者,容易导致Dt、DtGi的方差膨胀因子增大,进而使Dt和DtGi系数的显著性下降。如果你的政策实施时点是一致的,你也希望用多期DID进行回归(实际上也本应如此),那么你的实际操作过程会更简单,但是本文没有把这种特例单独列出来讨论。你可以按照本文的思路照搬照做,就当它是时点不一致,只需要在最后一步绘图中做出修改,将x轴可以直接写某某年,而不是“-1”“-2”这样子。最后需要指出的是,两期DID只是多期DID的特例,切勿用两期DID的思想套到多期DID身上,这句话很重要,再怎么强调也不过分。但是,你可以拿多期DID的思想直接套在两期DID上,如果你能“反套”成功,那就真的理解了多期DID了。
参考文献
Beck T, Levine R, Levkov A. Big bad banks? The winners and losers from bank deregulation in the United States[J]. The Journal of Finance, 2010, 65(5): 1637-1667.
免流量费下载资料----在经管之家app可以下载论坛上的所有资源,并且不额外收取下载高峰期的论坛币。
涵盖所有经管领域的优秀内容----覆盖经济、管理、金融投资、计量统计、数据分析、国贸、财会等专业的学习宝库,各类资料应有尽有。
来自五湖四海的经管达人----已经有上千万的经管人来到这里,你可以找到任何学科方向、有共同话题的朋友。
经管之家(原人大经济论坛),跨越高校的围墙,带你走进经管知识的新世界。
扫描下方二维码下载并注册APP

您可能感兴趣的文章
本站推荐的文章
人气文章
2.转载的文章仅代表原创作者观点,与本站无关。其原创性以及文中陈述文字和内容未经本站证实,本站对该文以及其中全部或者部分内容、文字的真实性、完整性、及时性,不作出任何保证或承若;
3.如本站转载稿涉及版权等问题,请作者及时联系本站,我们会及时处理。
