


 雷达卡
雷达卡



 [backcolor=rgba(18, 18, 18, 0.5)]
[backcolor=rgba(18, 18, 18, 0.5)]
编辑切换为居中
添加图片注释,不超过 140 字(可选)
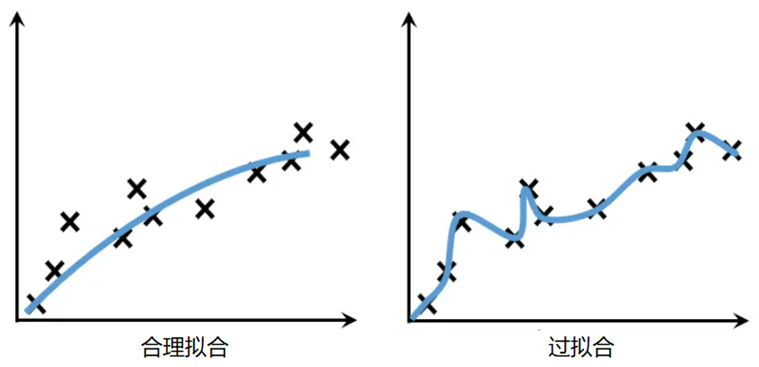
图1 模型过拟合
交叉验证(Cross-Validation),核心思想就是重复使用数据,将建模样本数据集进行拆分,然后组合成不同的训练集和测试集,在训练集中训练模型,在测试集中评价模型。在这样数据拆分的原理逻辑应用下,可以得到多个不同的训练集和测试集,其中某一个训练集的样本可能是下一个测试集的样本。交叉验证的目的是有效估计模型的测试误差,或称为泛化能力,然后根据模型验证的性能结果对比,选择精度较高的合适模型。交叉验证在实际应用中,K折交叉验证较为常用,但需要了解的是,交叉验证还有其他几种常用的经典方法。本文为了便于大家在建模过程中可以有效获取合理的模型,将具体介绍下在实际工作场景中最常用的几种交叉验证方法,包括HoldOut交叉验证、K-Fold交叉验证、分层K-Fold交叉验证、Shuffle-Split交叉验证、Leave-P-Out交叉验证等。为了便于说明各交叉验证方法的实现过程,我们通过具体的样本数据,同步给出各方法的实现过程与输出结果。样本数据包含8000条样本与12个字段,分别为主键ID、目标变量Y、特征变量X01~X10,部分样例如图2所示。
 [backcolor=rgba(18, 18, 18, 0.5)]
[backcolor=rgba(18, 18, 18, 0.5)]
编辑切换为居中
添加图片注释,不超过 140 字(可选)
图2 样本数据
1、HoldOut交叉验证
HoldOut交叉验证,是将整个数据集按照一定比例随机划分为训练集和验证集,在实际情景中,训练集与验证集的拆分比例一般为7:3或8:2。这种方法是最基础的也是最简单的交叉验证方法,由于在每次构建模型过程中,模型训练集上仅拟合一次,因此任务执行速度很快,但为了保证模型相对稳定,往往可以多次对数据进行拆分并训练模型,最后从中选择性能表现较优模型。在Python语言中,HoldOut交叉验证可通过调用函数train_test_split( )来选取数据,具体代码实现过程如图2所示(以逻辑回归算法分类为例),最终输出模型在训练集与测试集的准确率指标结果如图3所示。
 [backcolor=rgba(18, 18, 18, 0.5)]
[backcolor=rgba(18, 18, 18, 0.5)]
编辑切换为居中
添加图片注释,不超过 140 字(可选)
图3 HoldOut交叉验证代码
 [backcolor=rgba(18, 18, 18, 0.5)]
[backcolor=rgba(18, 18, 18, 0.5)]
编辑切换为居中
添加图片注释,不超过 140 字(可选)
图4 HoldOut交叉验证结果
2、K折交叉验证
K折交叉验证(K-Fold),这种方法的思想是将整个样本数据集拆分为K个相同大小的子样本,每个分区样本可以称为一个“折叠”,因此拆分后的样本数据可理解为K折。其中,某任意1折数据作为验证集,而其余K-1折数据相应作为作训练集。在交叉验证过程中,训练集与验证集的交替会重复K次,也就是每个折叠的分区样本数据都会作为验证集,其他折叠的数据作为训练集。模型训练后的最终精度评估,可以通过取K个模型在对应验证数据集上的平均精度。在Python语言中,K折交叉验证可通过调用函数cross_val_score( )与KFold( )来选取数据,具体代码实现过程如图5所示(以逻辑回归分类算法为例),最终输出模型在训练集与测试集的准确率指标结果如图6所示。
 [backcolor=rgba(18, 18, 18, 0.5)]
[backcolor=rgba(18, 18, 18, 0.5)]
编辑切换为居中
添加图片注释,不超过 140 字(可选)
图5 K折交叉验证代码、
 [backcolor=rgba(18, 18, 18, 0.5)]
[backcolor=rgba(18, 18, 18, 0.5)]
编辑切换为居中
添加图片注释,不超过 140 字(可选)
图6 K折交叉验证结果
3、分层K折交叉验证
分层K折交叉验证,主要原理逻辑与K折交叉验证是类似的,仍然是将整个样本数据集拆分为K个部分,最关键的区别是分层K折交叉验证通过对目标变量的分层抽样,使得每个折叠数据集的目标变量分布比例,与整个样本数据的目标情况保持一致,有效解决样本不均衡的情况,因此是K折交叉验证的优化版,且更能满足实际业务场景的需求。在Python语言中,分层K折交叉验证可通过调用函数cross_val_score( )与StratifiedKFold( )来选取数据,具体代码实现过程如图7所示(以逻辑回归分类算法为例),最终输出模型在训练集与测试集的准确率指标结果如图8所示。
 [backcolor=rgba(18, 18, 18, 0.5)]
[backcolor=rgba(18, 18, 18, 0.5)]
编辑切换为居中
添加图片注释,不超过 140 字(可选)
图7 分层K折交叉验证代码
 [backcolor=rgba(18, 18, 18, 0.5)]
[backcolor=rgba(18, 18, 18, 0.5)]
编辑切换为居中
添加图片注释,不超过 140 字(可选)
图8 分层K折交叉验证结果
4、Shuffle-Split交叉验证
Shuffle-Split交叉验证(蒙特卡罗交叉验证),这种方法虽然同样采用了样本数据随机拆分的思想,但实现过程主要有两个优点,一个是可以自由指定训练集与验证集的样本量大小,另一个是可以定义循环验证的重复次数n,相比K折交叉验证的固定K次重复明显更为灵活。在数据随机拆分的过程中,可以指定训练集与验证集的样本占比大小,二者比例之和没有必须为100%的要求,当比例小于1时,剩余占比的数据不参与模型的训练与验证。在Python语言中,Shuffle-Split交叉验证可通过调用函数cross_val_score( )与ShuffleSplit( )来选取数据,具体代码实现过程如图9所示(以逻辑回归分类算法为例),最终输出模型在训练集与测试集的准确率指标结果如图10所示。
 [backcolor=rgba(18, 18, 18, 0.5)]
[backcolor=rgba(18, 18, 18, 0.5)]
编辑切换为居中
添加图片注释,不超过 140 字(可选)
图9 Shuffle-Split交叉验证代码
 [backcolor=rgba(18, 18, 18, 0.5)]
[backcolor=rgba(18, 18, 18, 0.5)]
编辑切换为居中
添加图片注释,不超过 140 字(可选)
图10 Shuffle-Split交叉验证结果
5、Leave-P-Out交叉验证
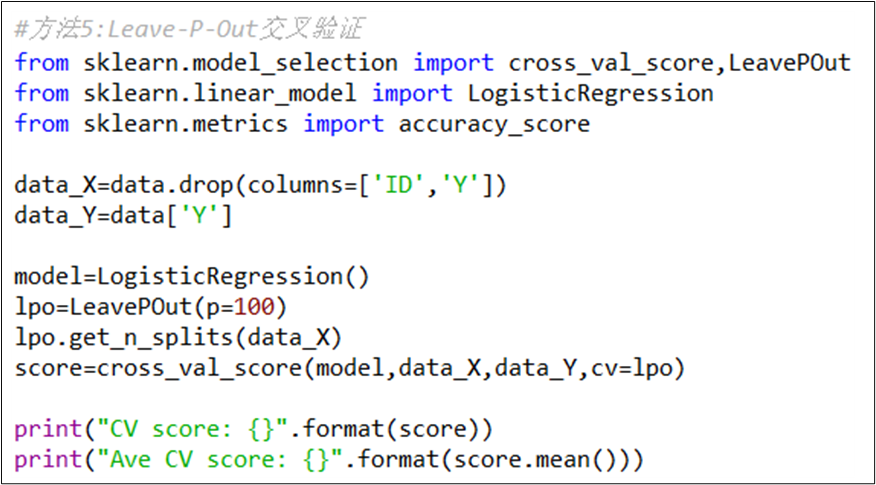
Leave-P-Out交叉验证,是通过指定p值后,p个样本作为验证集,剩余np个也不能作为训练集,然后不断重复这个过程,直到整个样本数据都作为验证集,这种方法的缺点是任务耗时较长,相比前几种方法应用相对较少。在Python语言中,Leave-P-Out交叉验证可通过调用函数cross_val_score( )与LeavePOut( )来选取数据,具体代码实现过程如图11所示(以逻辑回归分类算法为例)。
 [backcolor=rgba(18, 18, 18, 0.5)]
[backcolor=rgba(18, 18, 18, 0.5)]
编辑切换为居中
添加图片注释,不超过 140 字(可选)
图11 Leave-P-Out交叉验证结果
综合以上内容,我们结合实际样本数据,介绍了在实际工作场景中比较常用的几种交叉验证方法,包括HoldOut、K-Fold、分层K-Fold、Leave-P-Out、Shuffle-Split的交叉验证。当然,还有其他验证方法,例如留一交叉验证、时间序列交叉验证等,具体需要根据数据样本情况而定。但是,在实际建模过程中,无论采取哪种交叉验证方法,其目的都是为了获得一个综合性能较好的模型。针对以上介绍的几种交叉验证方法,在实际应用的过程中,需要注意以下几点:
(1)HoldOut、K-Fold、Leave-P-Out、Shuffle-Split交叉验证方法都不太适合样本不平衡的情况,可能会出现训练样本的目标取值分布与验证样本存在较大偏差,而分层K-Fold交叉验证可以有效解决样本不平衡问题;
(2)Leave-P-Out交叉验证虽然抽取数据较为详尽,但任务耗时较久,尤其是针对参数定义较为复杂的模型算法,一般情况下不建议使用;
(3)以上各方法在指定参数条件下,均采用随机抽样方法得到训练集与验证集,对样本的分配是随机的,因此不适合对排序有要求的时间序列样本数据;
(4)交叉验证方法在实际应用中,往往与网格搜索进行综合应用,一方面可以有效避免模型过拟合现象从而获得较为稳定的模型,另一方面可以通过多参数配置反复训练得到性能较优的模型。为了便于大家对模型交叉验证常用方法的进一步熟悉,我们准备了与本文内容同步的样本数据与python代码,供大家参考学习,详情请移至知识星球查看相关内容。
 [backcolor=rgba(18, 18, 18, 0.5)]
[backcolor=rgba(18, 18, 18, 0.5)]
编辑切换为居中
添加图片注释,不超过 140 字(可选)
...
~原创文章

 京公网安备 11010802022788号
京公网安备 11010802022788号







