
关于本站
人大经济论坛-经管之家:分享大学、考研、论文、会计、留学、数据、经济学、金融学、管理学、统计学、博弈论、统计年鉴、行业分析包括等相关资源。
经管之家是国内活跃的在线教育咨询平台!
获取电子版《CDA一级教材》
完整电子版已上线CDA网校,累计已有10万+在读~ 教材严格按考试大纲编写,适合CDA考生备考,也适合业务及数据分析岗位的从业者提升自我。

论文
- 毕业论文 | 写毕业论文
- 毕业论文 | 为毕业论文找思路
- 毕业论文 | 可以有时间好好写 ...
- 毕业论文 | 毕业论文如何选较 ...
- 毕业论文 | 毕业论文选题通过 ...
- 毕业论文 | 还有三人的毕业论 ...
- 毕业论文 | 毕业论文答辩过程 ...
- 毕业论文 | 本科毕业论文,wi ...
考研考博
- 考博 | 南大考博经济类资 ...
- 考博 | 考博英语10000词汇 ...
- 考博 | 如果复旦、南大这 ...
- 考博 | 有谁知道春招秋季 ...
- 考博 | 工作与考博?到底 ...
- 考博 | 考博应该如何选择 ...
- 考博 | 考博失败了
- 考博 | 考博考研英语作文 ...
TOP热门关键词
坛友互助群 |
扫码加入各岗位、行业、专业交流群 |
分类交叉熵损失的正则化技巧在机器学习和深度学习中是防止过拟合的重要手段。正则化通过在损失函数中添加惩罚项来限制模型的复杂性,从而提高模型的泛化能力。
-
L1和L2正则化:这是最常见的正则化方法。L1正则化通过将权重的绝对值作为惩罚项加入到损失函数中,使得部分权重可能被压缩至零,从而实现特征选择。L2正则化则通过惩罚权重的平方和来防止权重过大,这有助于模型保持较小且均匀的权重分布。
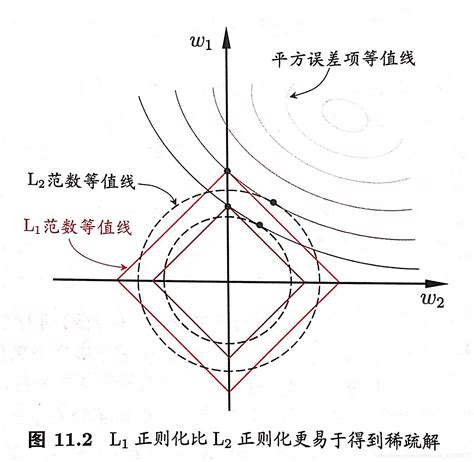
【机器学习】L1和L2正则化_l2normal的下标在哪-CSDN博客 -
Dropout正则化:这是一种在训练过程中随机丢弃部分神经元的方法,以减少模型对特定特征的依赖,从而增强模型的泛化能力。
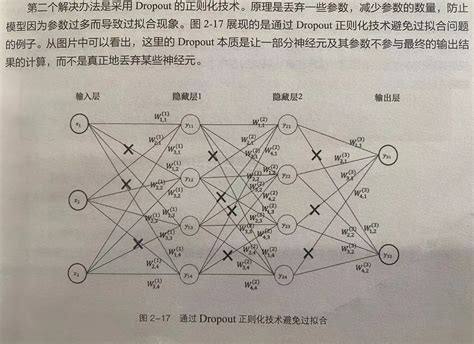
带你完全读懂正则化(看这一篇就够了) | AI技术聚合 -
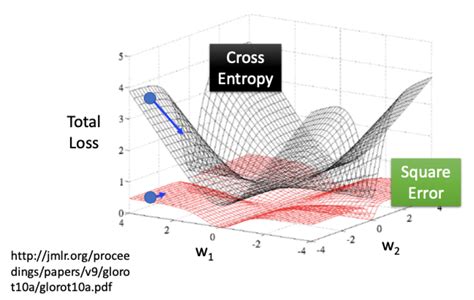
交叉熵损失与正则化结合:在多分类问题中,交叉熵损失函数常用于衡量模型预测值与真实标签之间的差异。通过引入正则化项,可以进一步防止模型过拟合。例如,在Keras模型中,可以通过
kernel_regularizer参数指定L1或L2正则化。

熵,交叉熵,KL散度公式与计算实例 (转载学习)_交叉熵计算-CSDN博客 -
加权交叉熵损失:为了解决类别不平衡问题,可以使用加权交叉熵损失,这种方法通过赋予不同类别的样本不同的权重来调整损失函数,从而提高模型对少数类别的识别能力。
逻辑回归的交叉熵损失函数原理 - 知乎 -
Focal Loss:这是一种改进的交叉熵损失,特别适用于处理类别不平衡问题。它通过调整样本的注意力权重来聚焦于难以分类的样本,从而提高模型的整体性能。
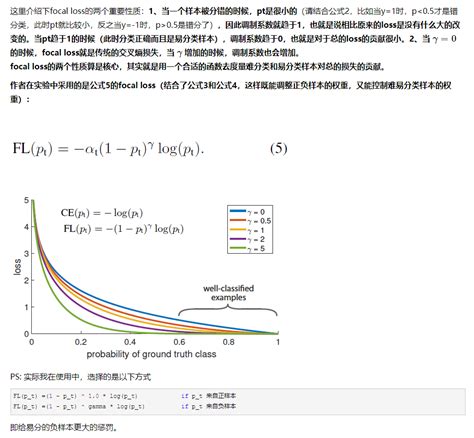
像素级样本不平衡问题loss设计 - 章云飞的博客 -
多视图分类中的正则化:在多视图分类任务中,可以通过设计特定的交叉熵损失函数来优化不同视角下的样本表示,以提高聚类质量和模型泛化能力。
-
正则化参数的选择:正则化效果依赖于正则化参数的设置。如果过大,可能导致模型欠拟合;如果过小,则可能无法有效防止过拟合。因此,通常需要通过交叉验证等方法来选择合适的值。

科学网—正则化+过拟合/欠拟合+交叉验证 - 张伟的 … blog.sciencenet.cn
通过这些正则化技巧,可以有效地控制模型的复杂度,避免过拟合,并提升模型在新数据上的表现。这些方法在实际应用中需要根据具体问题和数据集进行调整和优化,以达到最佳效果。

免流量费下载资料----在经管之家app可以下载论坛上的所有资源,并且不额外收取下载高峰期的论坛币。
涵盖所有经管领域的优秀内容----覆盖经济、管理、金融投资、计量统计、数据分析、国贸、财会等专业的学习宝库,各类资料应有尽有。
来自五湖四海的经管达人----已经有上千万的经管人来到这里,你可以找到任何学科方向、有共同话题的朋友。
经管之家(原人大经济论坛),跨越高校的围墙,带你走进经管知识的新世界。
扫描下方二维码下载并注册APP

您可能感兴趣的文章
人气文章
2.转载的文章仅代表原创作者观点,与本站无关。其原创性以及文中陈述文字和内容未经本站证实,本站对该文以及其中全部或者部分内容、文字的真实性、完整性、及时性,不作出任何保证或承若;
3.如本站转载稿涉及版权等问题,请作者及时联系本站,我们会及时处理。
